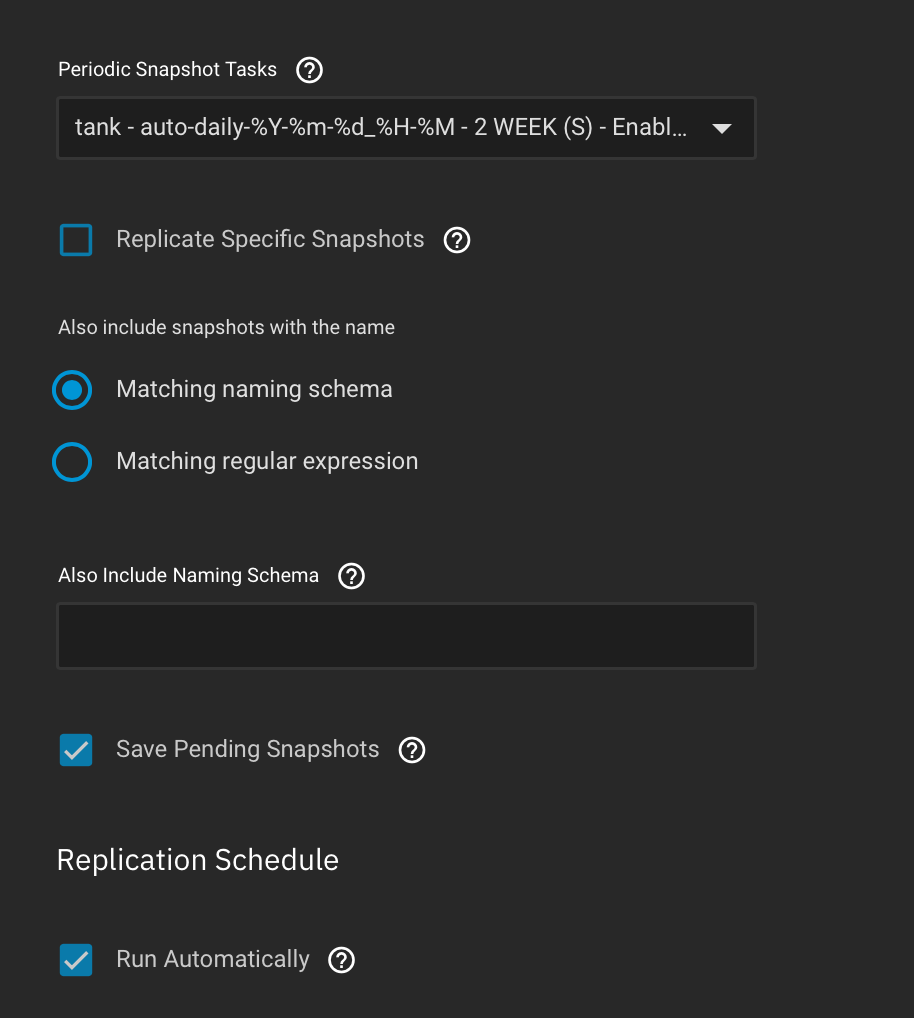
I have two systems. One is running 23.10.2 (Cobia), the other Dragonfish 24.04 RC1
My Cobia system is attempting to replicate a dataset (docker/volumes) to the Dragonfish system… and its relatively large (86GB), over a relatively slow 40mbps link.
This is a fine thing usually.
The issue is that the transfer failed, and now TrueNAS is attempting to use a resumable replication, which is also a fine thing… but that is reliably failing to resume… which is not fine.
[2024/04/12 00:00:04] INFO [Thread-4321] [zettarepl.paramiko.replication_task__task_9] Connected (version 2.0, client OpenSSH_9.2p1)
[2024/04/12 00:00:04] INFO [Thread-4321] [zettarepl.paramiko.replication_task__task_9] Authentication (publickey) successful!
[2024/04/12 00:00:05] INFO [replication_task__task_9] [zettarepl.replication.pre_retention] Pre-retention destroying snapshots: []
[2024/04/12 00:00:05] INFO [replication_task__task_9] [zettarepl.replication.run] For replication task 'task_9': doing push from 'tank/bizadmin' to 'tank/replicas/titan/bizadmin' of snapshot='auto-daily-2024-04-12_00-00' incremental_base='auto-daily-2024-04-11_00-00' include_intermediate=False receive_resume_token=None encryption=False
[2024/04/12 00:00:06] INFO [replication_task__task_9] [zettarepl.paramiko.replication_task__task_9.sftp] [chan 5] Opened sftp connection (server version 3)
[2024/04/12 00:00:06] INFO [replication_task__task_9] [zettarepl.transport.ssh_netcat] Automatically chose connect address 'chronus.<redacted>'
[2024/04/12 00:00:09] INFO [replication_task__task_9] [zettarepl.replication.pre_retention] Pre-retention destroying snapshots: []
[2024/04/12 00:00:09] INFO [replication_task__task_9] [zettarepl.replication.run] For replication task 'task_9': doing push from 'tank/certificates' to 'tank/replicas/titan/certificates' of snapshot='auto-daily-2024-04-12_00-00' incremental_base='auto-daily-2024-04-11_00-00' include_intermediate=False receive_resume_token=None encryption=False
[2024/04/12 00:00:09] INFO [replication_task__task_9] [zettarepl.transport.ssh_netcat] Automatically chose connect address 'chronus.<redacted>'
[2024/04/12 00:00:13] INFO [replication_task__task_9] [zettarepl.replication.pre_retention] Pre-retention destroying snapshots: []
... 296 more lines ...
[2024/04/12 00:59:30] INFO [replication_task__task_9] [zettarepl.replication.run] Resuming replication for destination dataset 'tank/replicas/titan/docker/volumes'
[2024/04/12 00:59:30] INFO [replication_task__task_9] [zettarepl.replication.run] For replication task 'task_9': doing push from 'tank/docker/volumes' to 'tank/replicas/titan/docker/volumes' of snapshot=None incremental_base=None include_intermediate=None receive_resume_token='1-132c326b1c-f8-789c636064000310a500c4ec50360710e72765a526973030c4b23381d560c8a7a515a79630c001489e0d493ea9b224b518489f586aa883cdfc92fcf4d2cc140686ab8fd50a66b627d57820c97382e5f31273538174625eb67e4a7e72766a917e597e4e696e6ab143626949be6e4a62664ea5ae91819189ae81b1ae9171bc8181ae8101d81e6e0684bf92f3730b8a528b8bf3b3116e050058e6276a' encryption=False
[2024/04/12 00:59:30] INFO [replication_task__task_9] [zettarepl.transport.ssh_netcat] Automatically chose connect address 'chronus.<redacted>'
[2024/04/12 00:59:31] WARNING [replication_task__task_9] [zettarepl.replication.partially_complete_state] Specified receive_resume_token, but received an error: contains partially-complete state. Allowing ZFS to catch up
[2024/04/12 01:00:31] INFO [replication_task__task_9] [zettarepl.replication.pre_retention] Pre-retention destroying snapshots: []
[2024/04/12 01:00:31] INFO [replication_task__task_9] [zettarepl.replication.run] Resuming replication for destination dataset 'tank/replicas/titan/docker/volumes'
[2024/04/12 01:00:31] INFO [replication_task__task_9] [zettarepl.replication.run] For replication task 'task_9': doing push from 'tank/docker/volumes' to 'tank/replicas/titan/docker/volumes' of snapshot=None incremental_base=None include_intermediate=None receive_resume_token='1-132c326b1c-f8-789c636064000310a500c4ec50360710e72765a526973030c4b23381d560c8a7a515a79630c001489e0d493ea9b224b518489f586aa883cdfc92fcf4d2cc140686ab8fd50a66b627d57820c97382e5f31273538174625eb67e4a7e72766a917e597e4e696e6ab143626949be6e4a62664ea5ae91819189ae81b1ae9171bc8181ae8101d81e6e0684bf92f3730b8a528b8bf3b3116e050058e6276a' encryption=False
[2024/04/12 01:00:31] INFO [replication_task__task_9] [zettarepl.transport.ssh_netcat] Automatically chose connect address 'chronus.<redacted>'
[2024/04/12 01:00:32] WARNING [replication_task__task_9] [zettarepl.replication.partially_complete_state] Specified receive_resume_token, but received an error: contains partially-complete state. Allowing ZFS to catch up
[2024/04/12 01:00:32] ERROR [replication_task__task_9] [zettarepl.replication.run] For task 'task_9' non-recoverable replication error ContainsPartiallyCompleteState()
It appears to find the resume token, attempts to use it… fails… tries again… then fails finally.
While its failing, the progress dialog just sits at 0% like this:
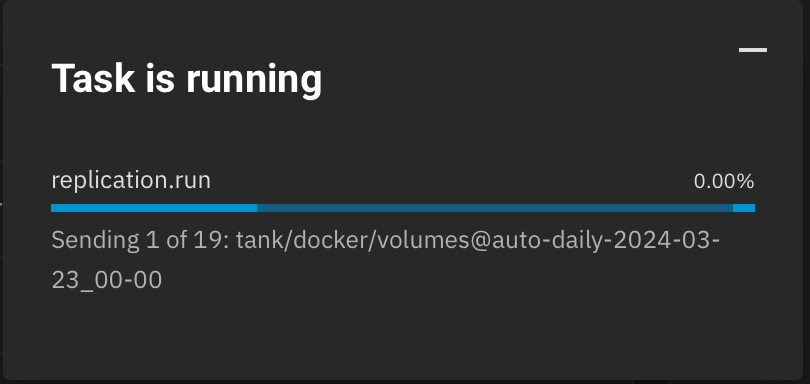
Any ideas… it seems this should work… I can probably blow away the partial dataset on the destination, but I figured there is an underlying issue here.