Of course either your NVMe RAIDZ2 is faster than your network or slower. If slower, then sustained bulk writes will eventually fill up that part of ARC which is allowed to be used for pending writes and then things will slow down.
You also need to understand whether writes will be synchronous or asynchronous, and then there are some ZFS tuneable parameters which you can tweak to increase the amount/proportion of memory that can be used for pending writes (at the expense of data or metadata held in ARC - the limits are there to prevent bulk writes from trashing the entire ARC and give a balance between caching the writes and preserving the ARC contents).
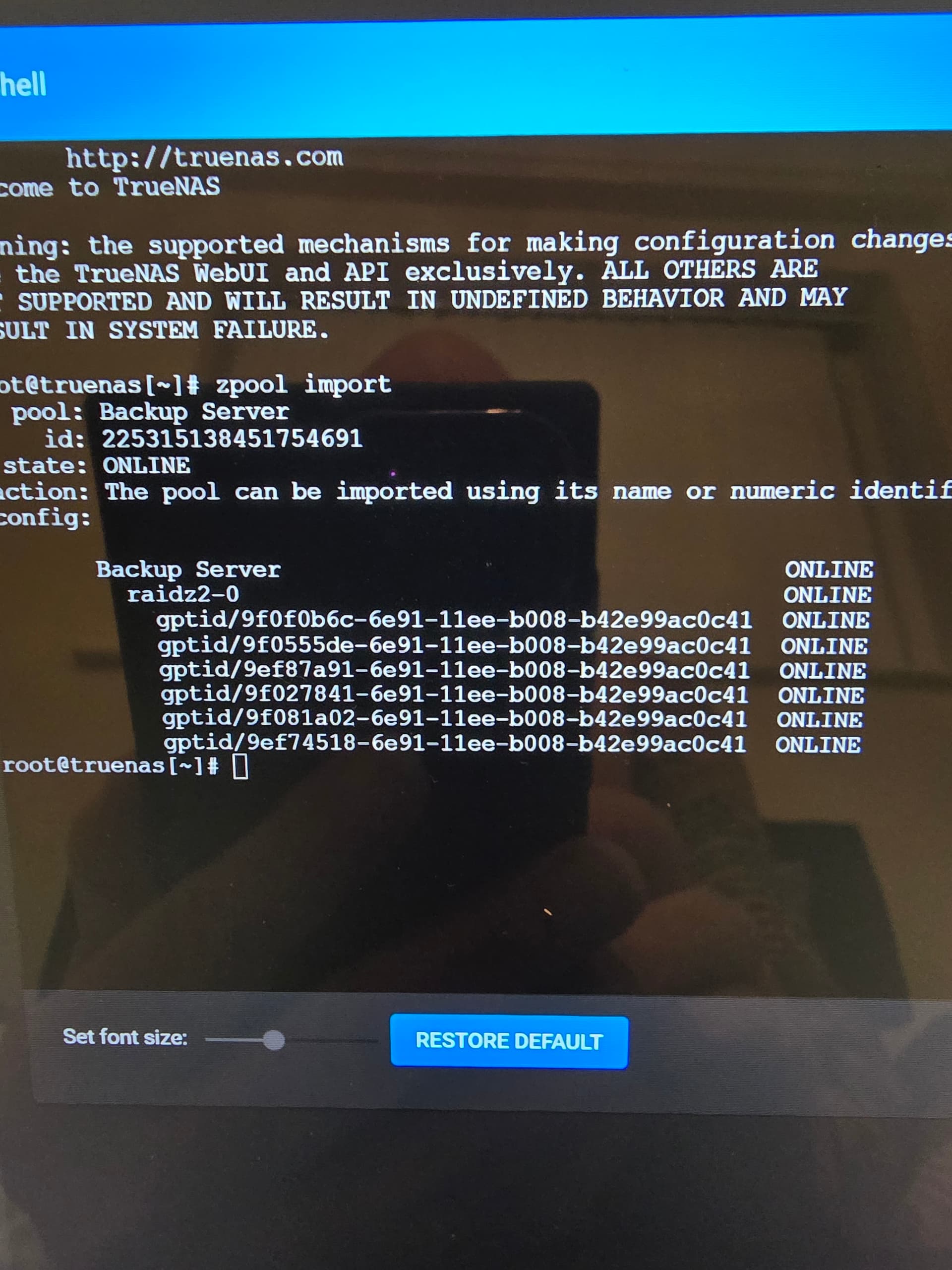
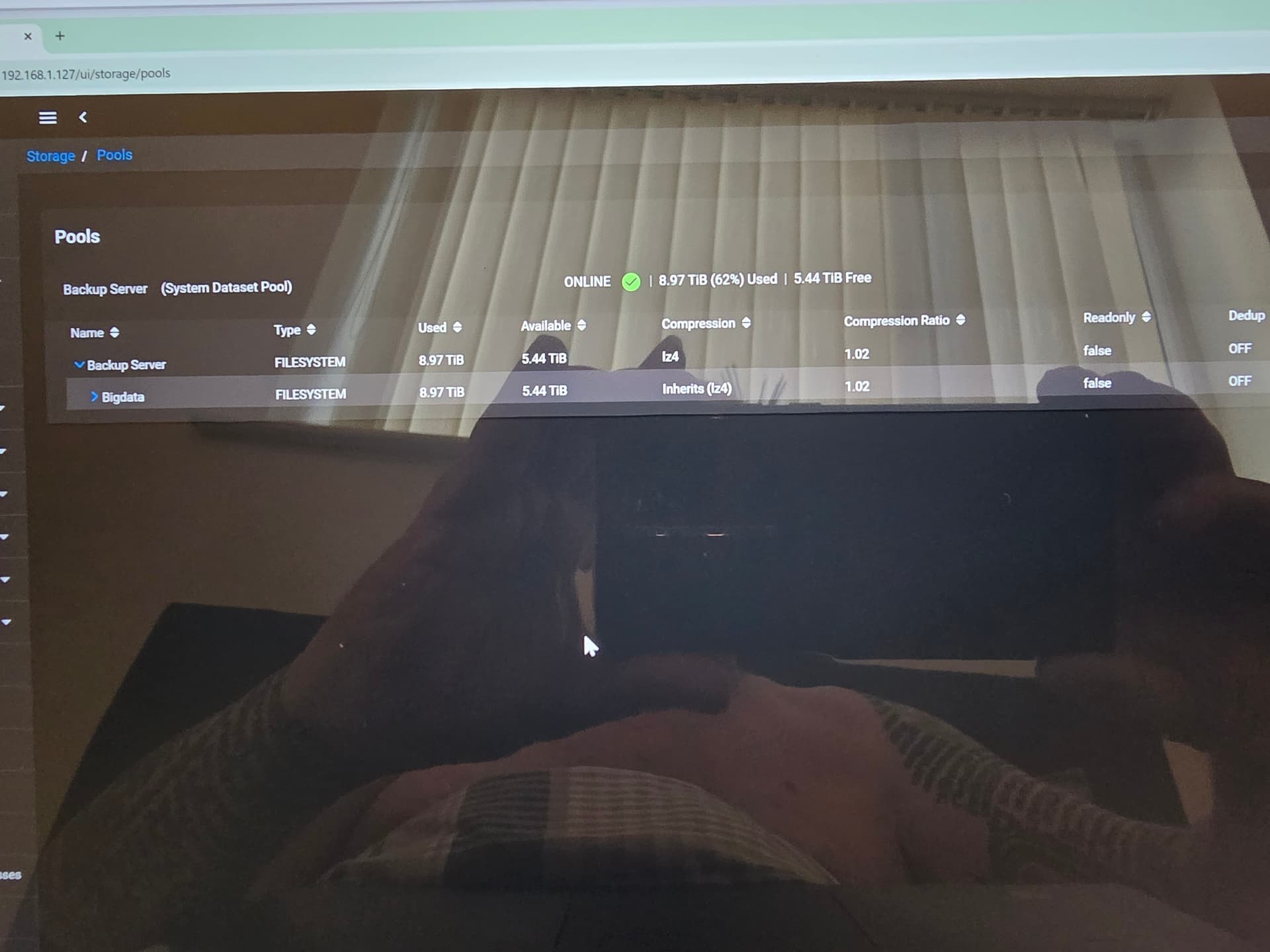
What did you recently do? Did you have to import the pool after you got all the drives showing or was everything just working once the drives were showing? Have you checked to see what the share settings currently are? Sharing tab of your GUI?
ZFS buffers up 5 seconds (by default) of writes then commits a Transaction Group (TXG) in one go.
It supports two of these.
Which means theoretically you require enough RAM to buffer 10 seconds of writes from your fastest connection in order to not throttle the network connection.
And that’s not including TCP buffers and windows either.
So 10gbe is 1GB/s. So 10GB for incoming write buffer.
(This is also how you can size a SLOG btw)
And then that gets written to disk. If your disk can sustain the incoming rate, then eventually back pressure will get applied
The important point is that ZFS always buffers up 5 seconds of async writes. Sync writes are written without buffering.
I am not sure this is true. Sync writes actually consist of two writes:
ZIL - this is done immediately without buffering for each network write. This is what ensures transactional consistency in the event of an unplanned shutdown. The ZIL exists regardless of SLOG. The SLOG helps by being on a much faster device or simply by being on a separate device from the data with separate I/O capacity or both.
Grouped writes - which are quite like async writes (or could even be the same as asynch writes - though I think the buffers and buffer amounts are separate).
There are definitely memory limits on how much data is stacked up for a TXG (the tuneable parameters I previously mentioned). So I guess if it reaches these tuneable limits before the 5 secs are up it does a TXG anyway to clear some memory.
But in general terms, your memory estimates sound like they might be right.
It is pretty good - in fact I am surprised at how good it is. But, the vast majority of my I/O is for Plex data or media streaming. The plex data is probably very repeated and the quantity of repeated data is relatively small (and on SSD anyway), and the streaming data benefits from sequential pre-fetch (which looks like an ARC hit both in the summary statistics and in terms of I/O speed).
I only do a small amount of random desktop I/O and again to a few common directories the metadata of which is likely to be in ARC.
Summary: I think my usage is probably quite typical for a small home Plex user. But other usage patterns may not be as good with small ARC and thus need more memory.
My NAS server is an old-ish Terramaster appliance, and 10GB is the max memory it will take (2GB on board + 8GB SODIMM) - otherwise I would have put in more from the start.