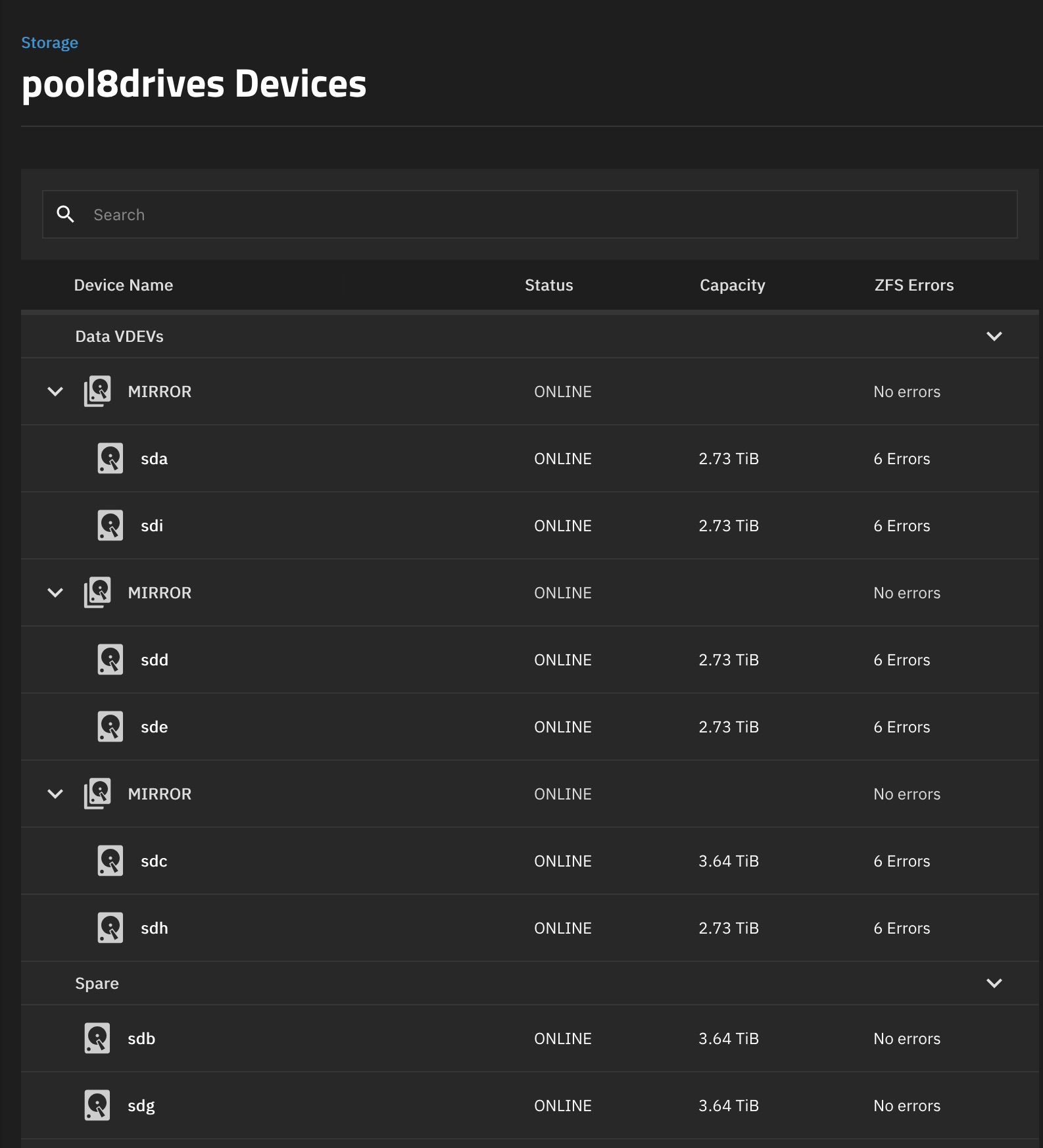
in my pool8drives pool, a 3 x MIRROR | 2 wide 3TB SATA drives (see signature for the details) one of the drives failed.
So I replaced with another SATA drive but of 4TB capacity (yes, I flagged the Treat Disk Size as Minimum checkmark when I created the pool).
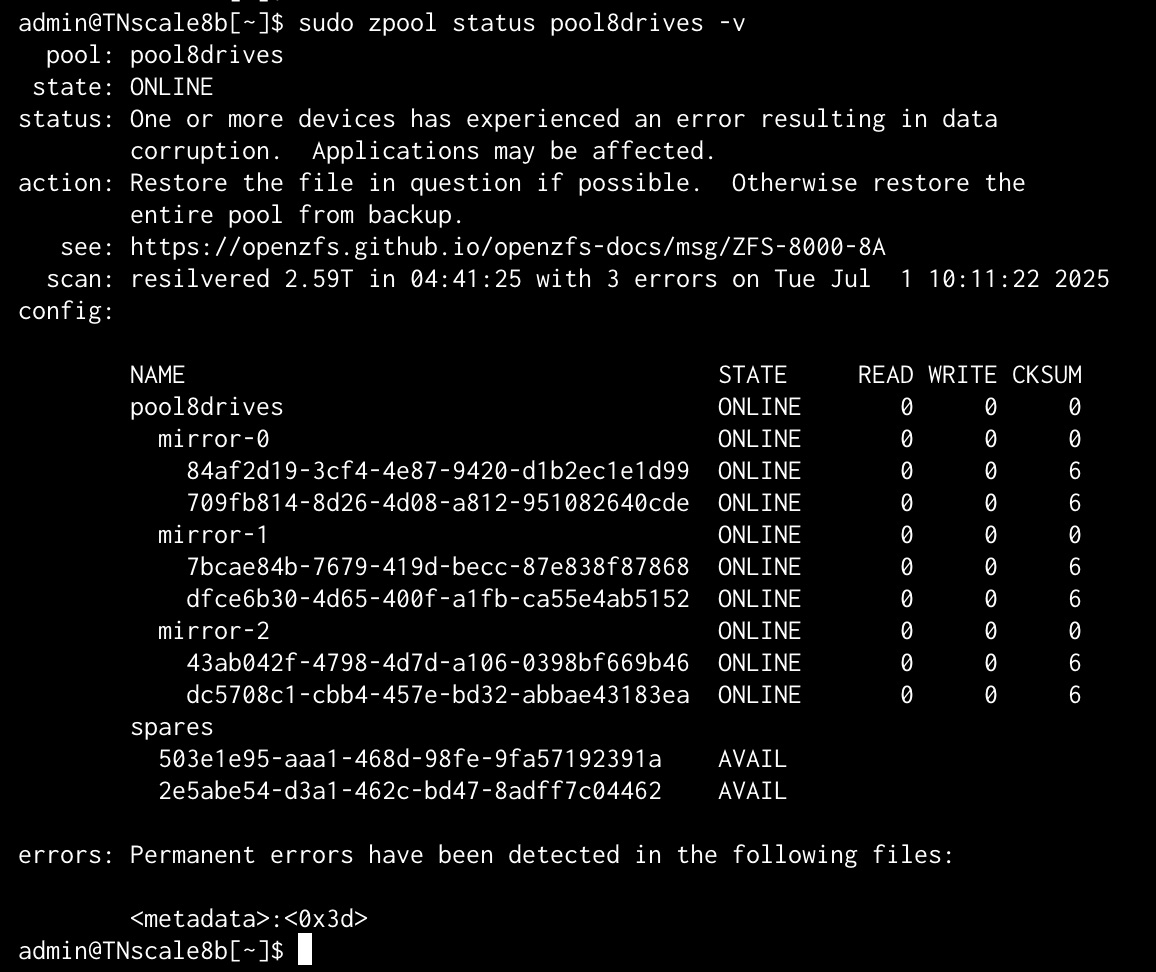
The replacement went okay, all the drives appears online and available except for the error TN Scale is reporting in all the drives (thei error wasn’t present before the drive replacement, even with the drive failed).
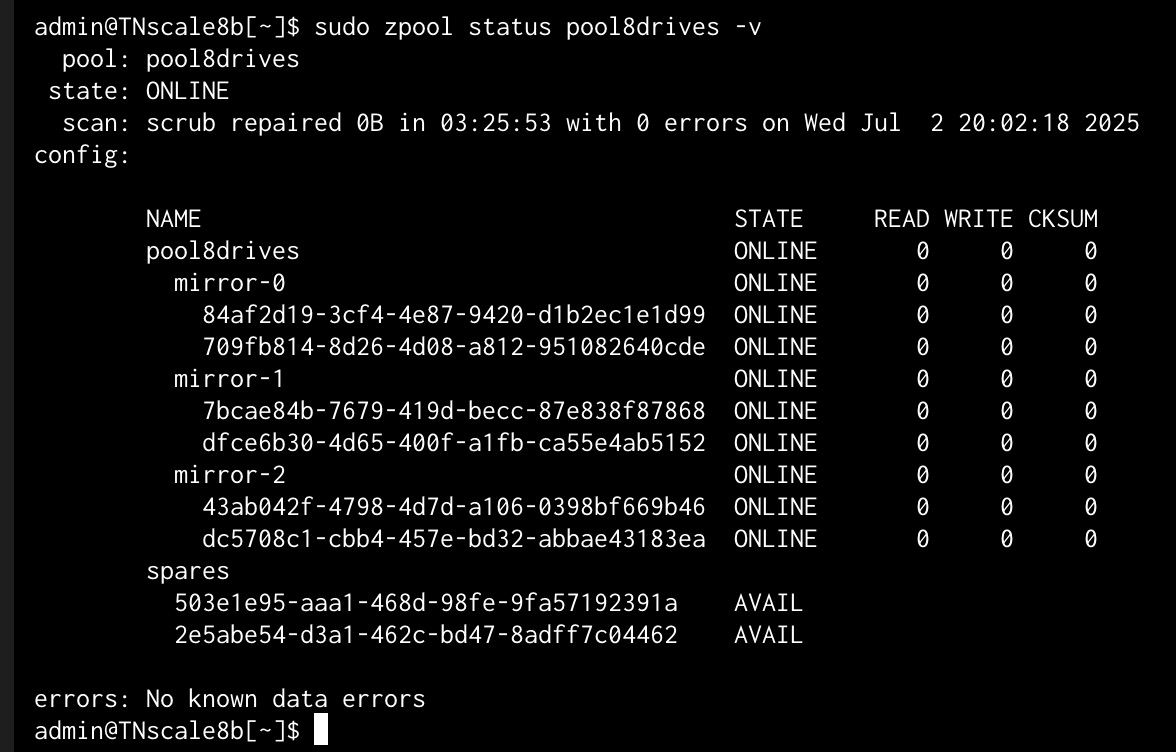
Have you performed a pool scrub since replacing the failed drive?
Pool defaults include redundant_metadata=all so unless it’s been corrupted across all three vdevs it should be able to rebuild.
When set to all , ZFS stores an extra copy of all metadata. If a single on-disk block is corrupt, at worst a single block of user data (which is recordsize bytes long) can be lost.
It’s not the first drive I replace (in my other TN NAS) but in this case I shocked how a simple drive replacement had a so tragic outcome.
Is it that common to toast a pool just replacing a drive?
What about if I try to replace the metadata damaged file, supposed I’m able to find it?
I do have a bunch of snapshots (on same NAS) and configuration file backups (elsewhere)
Yes, I am surprised that a server grade system, (AMD Epyc with ECC RAM, and LSI HBAs), would have this problem.
No, this is way outside of normal.
However, I would suggest running a days long memory test. And if you can’t take that much down time, then at least hours long.
There are potentially 2 causes, over-heating of HBA controllers, which could easily affect all disks attached. Second, a memory error that caused a bit flip in ZFS Metadata, which when written twice to different vDevs, both would be corrupt.
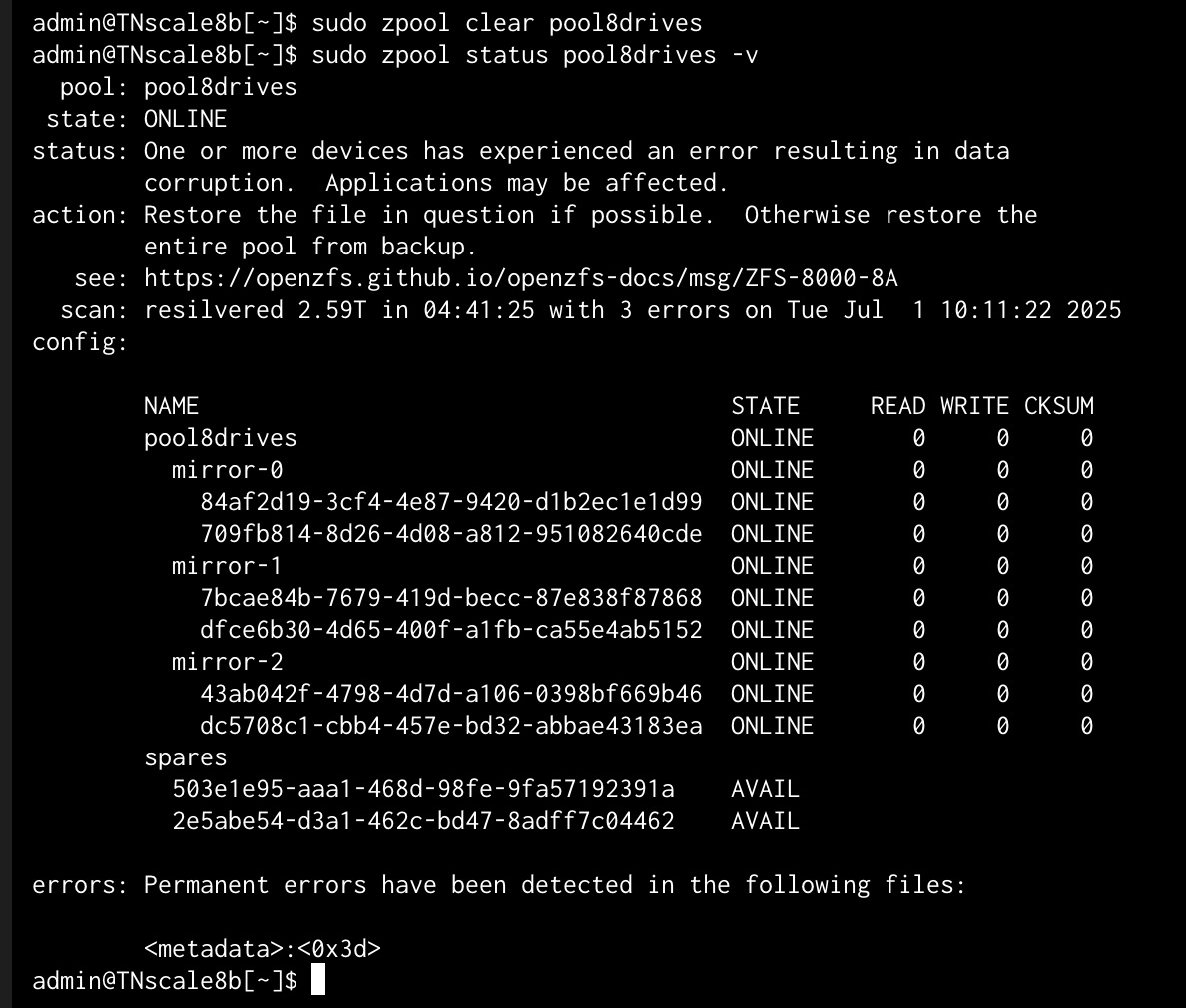
If an error clear & scrub does not make the error go away, then perhaps rolling back to an earlier transaction might help. But, then again, their may not be any good ZFS transaction group to roll back to.
This does tell us something. The likely cause was a HBA / disk controller problem, perhaps over-heating. If either HBA seems to have restricted air flow, you might look to add additional cooling via internal fans.