I recently replaced an 8x 1TB vdev with 8x 8TB. The dataset assigned to this vdev was instantiated with 128k record sizes, but I changed it before replacing the drives to 1M. When using the TrueNAS Raid Calculator online, my 8x 8TB with a record size of 1M should give me 2 extra TiB than I currently show. Is there anything I can do about this without starting completely from scratch? Even then, if I do start from scratch, is there a way to define record size when creating a VDEV from the GUI? I cannot seem to find one and it seems to be tied to the dataset.
Based on the this post, is this just a GUI estimate for capacity based on the default 128KiB?
My current expanded pool
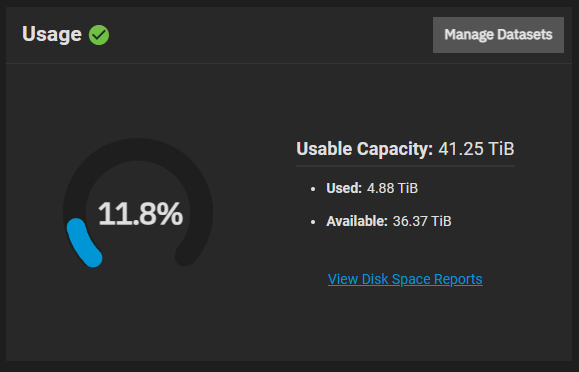
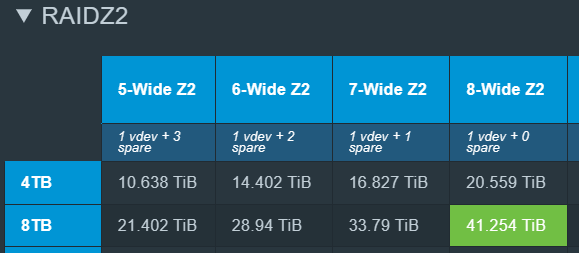
Expected capacity with 8x 8TB (7.27TiB) and the default 128KiB record size
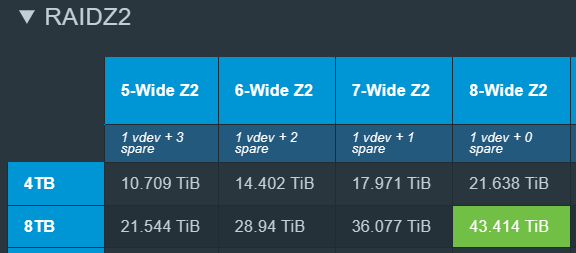
Expected capacity with 8x 8TB (7.27TiB) and the 1MiB record size
OS Version:TrueNAS-SCALE-24.04.1.1
Product:Standard PC (i440FX + PIIX, 1996)
Model:QEMU Virtual CPU version 2.5+
Memory:6 GiB
I wonder if you need to turn on zstd compression, followed by running a rebalancing script? Is the data small files, databases, virtual machines, etc. or images, movies, and the like? Large record sizes are only beneficial for large files.
So could you verify in the Datasets GUI that the recordsize is what you expect it to be and that compression has been turned on? Thereafter, I’d run the rebalancing script, see here.
Most of the storage is linux isos and similar media, but it is littered with small metadata files as well. Additionally, it is used for Proxmox Backup Server, so larger files there as well.
It looks like the new record size is effective for new files based on the histogram shown in the linked article, though it would probably be best to run that rebalancing script too.
Thanks for the pointer!
Block Size Histogram
block psize lsize asize
size Count Size Cum. Count Size Cum. Count Size Cum.
512: 123K 61.6M 61.6M 3.82K 1.91M 1.91M 0 0 0
1K: 23.4K 24.3M 85.9M 23.8K 24.5M 26.4M 0 0 0
2K: 45.6K 155M 240M 4.34K 11.7M 38.2M 0 0 0
4K: 185K 744M 985M 5.76K 28.8M 67.0M 0 0 0
8K: 171K 1.94G 2.90G 3.22K 34.8M 102M 30.1K 361M 361M
16K: 42.1K 926M 3.80G 173K 2.72G 2.82G 371K 8.69G 9.04G
32K: 102K 4.73G 8.53G 296K 9.31G 12.1G 228K 10.7G 19.8G
64K: 349K 31.4G 39.9G 5.38K 507M 12.6G 209K 20.6G 40.4G
128K: 37.3M 4.66T 4.70T 37.8M 4.72T 4.73T 37.4M 6.58T 6.61T
256K: 15.0K 5.54G 4.70T 5.91K 2.17G 4.73T 13.2K 4.85G 6.62T
512K: 22.7K 16.3G 4.72T 11.1K 8.36G 4.74T 20.5K 15.3G 6.63T
1M: 190K 190G 4.90T 224K 224G 4.96T 200K 265G 6.89T
2M: 0 0 4.90T 0 0 4.96T 0 0 6.89T
4M: 0 0 4.90T 0 0 4.96T 0 0 6.89T
8M: 0 0 4.90T 0 0 4.96T 0 0 6.89T
16M: 0 0 4.90T 0 0 4.96T 0 0 6.89T
1 Like
You can also consider making different datasets for the different data sizes for more optimization instead of placing everything in a single sized data ‘bucket’.
1 Like
Most of the metadata files are intermingled with the larger files, but creating additional unique datasets for other uses in the pool is probably smart regardless.
Doesn’t record size only dictate the maximum record size though? My research concluded that as long as you’re not running a DB with a specific record size requirement/optimization, bigger is better, especially if you have a lot of large files. I don’t know if I could find it again but I also thought that smaller files would utilize smaller records such that ZFS doesn’t waste space with small files with large record sizes.
1 Like
Larger blocks can improve the efficiency of read and write operations for large files, Large block size can also lead to increased fragmentation and wasted space if there are many small files.
Linux Journal has a decent article that came out recently on Linux file systems and block sizes and data structures.
https://www.linuxjournal.com/content/understanding-linux-filesystems-inodes-block-sizes-and-data-structures
1 Like
Correct.
I try to demystify it here.
1 Like
Reply to @PhilD13
I could be wrong, but I believe that block size and record size are different. Block size can be defined on creation (with ashift?) and record size is set by the dataset and can be updated to affect future files. Some research indicates that the two terms are used interchangeably but I don’t know if that is done correctly most of the time.
https://www.usenix.org/system/files/login/articles/login_winter16_09_jude.pdf describes that “Writing a 16 KB file should take up only 16 KB of space (plus metadata and redundancy space), not waste an entire 128 KB record.”
Regardless, this is out of the scope of the question- I am wondering why the GUI is showing a lower total capacity than expected. Unless this is just an estimate using the default 128KiB record size, I want to make sure I set everything up correctly.
Reply to @winnielinnie
I am correct in my understanding of record sizes or the fact that the GUI only shows an estimate of total capacity based on the default 128KiB record size?
Also thanks for the writeup, really insightful and solidifies my understanding of record sizes and how it affects datasets. You should consider putting that info into another post under the ‘Resources’ section of the forum for other people to reference!
I’m not sure how the GUI and/or ZFS estimates come up with this number for a pool comprised of RAIDZ vdevs.
You have to remember: A pool can be comprised of a mixture of different vdevs (mirror, RAIDZ1, RAIDZ2, RAIDZ3), and furthermore, datasets in the pool can have different recordsize policies.
So how could the GUI / middleware / ZFS accurately land on the same numbers as the RAIDZ calculator? There are too many variables that can dynamically change throughout the life of a pool.
You may be correct that it just assumes 128-KiB recordsize for everything.
That’s an excellent point, thanks. I’ll just assume that for now.