That would explain why the resilver has stopped.
Yes. It’s perhaps a little unfair to suggest TrueNAS SCALE is unstable simply because you are seeing multiple drive failures. These drives would have failed on any other ZFS system no doubt.
Question is how old are the drives? When did the first one fail and why was it not replaced? Resilvers and I dare say Expansion will put considerable stress on drives so if they are already creaking it can be enough to send them over the edge.
2 Likes
There is a difference with ZFS compared to EXT2/3/4. If their is bit-rot in a file on EXT2/3/4, (but not in directory entry), you probably won’t know it unless you see the corruption when using the file. So some people rant about ZFS reporting errors when they “never” had errors with EXT2/3/4. It may just be the case they never knew about the errors. ZFS will report any corruption on read and scrub.
In general, TrueNAS SCALE with ZFS is stable. But, in some cases, like with SMR disks, USB attached data disks, (not boot disk), or consumer / home hardware without ECC memory, problems can occur.
We have such a wide variety of use cases, and setups that from an outside perspective it can be hard to nail down causes of problems.
3 Likes
I never thought of this, but when you add a drive to say a raidz1 via expansion, and the process is not yet finished, does that count as the one disk the vdev is allowed to loose?
I’m not very familiar with expansion but my guess would be until the expansion is complete the original pool config applies.
Do you have your apps on a 17-wide raidz2 of HDDs? ![]()
No. With raidz2 you’re at risk after losing two drives. Any more issue during the-LONG—resilver can be fatal.
It generally is, but you have been pushing your luck too far.
It goes without saying but IF you can still access the data on this pool then I suggest you backup any important data asap.
1 Like
ok ![]() let me clear that :
let me clear that :
-
That’s not me that choose to put the ix-applications on the RaidZ2 pool, it’s the system at the installation of the apps, while it was enough space on the system disk holding Scale to do so, as only one third of the boot disk is used btw… don’t know why Scale don’t put it on there and choose the Raid pool… BTW, shouldn’t RaidZ2 strong enough to not break ?
 if the system trust that, why not me ?
if the system trust that, why not me ? -
I’ve lost a disk as it really died on me, it’s the first ‘removed’ disk, being replaced.
-
when the disk died an expansion of the pool was just beginning, and the system stopped that for me to replace the dead disk. that’s the second ‘removed’ disk, so technically it is only one disk that’s lost for now,
-
then the ‘faulted’ disk is one new that was just placed last month and for whom the Raid expansion resilvering took a long time.
-
when this resilvering ran I’ve seen numerous time disks being 'stopped and ‘removed’ with lotsa wanabe errors said to be on it from the pool just to be recalled later and finishing resilver fine without any errors.
so I don’t see why it would be different this time…
for the ext4 disks I still haven’t lost any files with them in ten years (and as I often copy and use these files from disk to disks and across other machines and the NAS I can say that these files are fine with no rot ![]()
ZFZ was said to be the strongest and safest filesystem of the universe, that’s why I choose TrueNAS Scale for my needs (and for the added possibility of growing the pool when I have the money for without having to reconstruct it after backuckping the whole beast first each time. I don’t have many money so it was the right solution for me, at least at start ![]()
I need a monstrous sized Raid array for my work as some files used can be very big and better put in one chunk that in a multitude of small pieces across lotsa stuff to be used without glitches…
I would like to know if dRAID is possible with Scale at all ?? as asked before…
So, as now I just can’t backup 120 TO of datas (don’t have the space for that) I just think I will shut down that NAS totally for now and look for another RAID solution to keep my files safe.
Well, looking at the bright side of things, your long line of less than ideal configuration choices, intentional or not, now mean that you likely no longer have 120 TB of data to worry about anymore. So that’s that weight of your chest, whew!
Scale can use dRAID. That doesn’t mean it’s a good fit for you, I would say it’s more of a specialist option.
1 Like
thanks for dRAID, but I don’t recall having given the choice at install time.
now at 500 Euro an enterprise or nas disk I can only do what I can with my poor life ;p
BTW I was wondering why so many gossiped on UnRaid and nearly never on TrueNAS, while unraid is paid for use software… perhaps my biggest error was to choose FreeNAS at first ? ;p
In no way is that expected or OK. Could be heat on that LSI, could be RAM as the system doesn’t have ECC - hard to say but “wannabe errors” during resilver point to a massive problem.
For ZFS, planning ahead is very much helpful. I don’t think draid is right for you, but multiple vdevs would have been - as would have been ECC memory (just for peace of mind) and investigating any errors that crop up when they shouldn’t.
Typically with this many disks you’d see 8x10 TB or maybe max 10x10 TB per vdev. Of course you can have multiple vdevs in the same pool, this doesn’t mean you split your data. It just means you design in a way that is friendly to resilver. Strain on the disks and risk of failure goes up the wider the vdev is.
Unraid is going to be much easier to administrate. I don’t think it can save you from whatever underlying issue causes the “wannabe errors” in this system, but it certainly needs a lot less planning.
Your apps on TrueNAS, btw, are best placed on an appropriately-sized mirror SSD pool. Not the boot drive. A separate pool.
1 Like
I would have been happy to be able to use ecc memory (as I have it in stock) but never got the box to boot with it installed whatever the OS, although that same ram worked elsewhere in others ![]() don’t know why, as at least the mobo is said to made good use of ecc mem if available as well as the OS and TrueNAS… the i7 in this machine should handle it too…
don’t know why, as at least the mobo is said to made good use of ecc mem if available as well as the OS and TrueNAS… the i7 in this machine should handle it too…
unraid is not for me as I support Free Software the most.
the only software I bought (one time for all) for linux is my pro scanner one : I can feed it with any scanner I want, even very old scsi or parallel port ones or very uncommon ones and it just works ![]() I had less chances with sane… as I have a lot of ‘safepu’ hardware in my collection it’s perfect to use or test it !
I had less chances with sane… as I have a lot of ‘safepu’ hardware in my collection it’s perfect to use or test it !
Not sure where you’re getting that from? What I can find about the Maximus IV gene-z is that it doesn’t support ECC. The i7-2600 as well does not support ECC, see https://www.intel.com/content/www/us/en/products/sku/52213/intel-core-i72600-processor-8m-cache-up-to-3-80-ghz/specifications.html
ECC in Intel land is Xeon, some i3 and some Pentium, depending on generation. Xeon and workstation chipsets only. With recent generations more CPUs support ECC (i5, i7, i9), but still require the workstation chipsets.
In AMD land the Ryzen desktop CPUs support ECC, but there’s only one vendor who consistently implements support: AsRock.
For ECC to work, the CPU has to support it, the chipset has to support it, the motherboard vendor has to put the traces down, and the motherboard vendor has to support it in BIOS/UEFI.
ECC is not a given and takes building for it, deliberately.
I use it in my main TrueNAS and our PCs; I don’t have it on the backup TrueNAS.
Ruling out RAM failure without ECC is alas a pain. Boot from memtest86+ (the FOSS one) and run for 5 days in continuous loop. That doesn’t rule out memory failure but makes it very very unlikely. A few runs, or even a day without errors, is not conclusive.
For my backup TrueNAS I did a 14 day memory test to be reasonably sure the memory was good at least at the point of testing.
All that ECC does is remove the guesswork and lengthy troubleshooting. You’ll know when it goes bad.
For drives, I use the HDD burn in / badblocks script that’s floating around these forums, from an Ubuntu Live USB, before placing a drive into a pool. I haven’t found any bad drives this way, but others have found bad drives after placing them into a pool, when they didn’t test ahead of time. Ouch. It adds a little bit of time but it’s not bad: The last test I did was for 8TB HDD and took about 4 days.
3 Likes
Apps are about small transactions, for which raidz# is highly inefficient and mirrors are recommended. iXsystems further recommends to put apps on SSDs rather than HDD.
TrueNAS does automatically moves the system dataset from the boot pool to the first created pool, which might not be optimal if one begins with the “bulk storage” pool but it is always possible to move the system dataset through the GUI. The app/instances/VM pool, as far as I know, one has to declare it, TrueNAS does not choose—and in any case it can be moved.
Sh!t happens. That’s what resiliency aims to address.
As soon as expansion was initiated, the vdev had an extra member taking part in the redundancy scheme. Losing this disk was a second drive incident and a second lost drive.
Long expansion might be a consequence of excessive width.
Had you burnt the drive in before adding it?
This was not normal and should have been investigated…
Possibly, when used according to recommended practices.
ZFS was designed for enterprise use, and as most professional tools it can be a very efficient way to shoot oneself in the foot when used without proper care.
Yes, through the command line. Note that dRAID cannot be extended and relies on having suffcient spares. And “beyond an effective width of 40, dRAID3 gets pretty wacky” (read all posts by @jro in the thread).
If you haven’t shut down the NAS yet and can still access the pool, I’d strongly suggest looking for extra storage and backing up anything critical, as there’s no guarantee this pool will ever mount back. (Yes, it’s not my money here, but it’s also not my data…)
1 Like
You should be able to configure dRAID through the web UI now as well.
2 Likes
Hello ^^)
cool new option jiro ![]()
just made the update to 25.4 and what I see it’s that it does not cure any of the problems I had ![]()
so, I’ve done a totally new install instead and this time I see that the cpu, hdd, hdd temp , etc reports are working again, cool ![]()
so I’ve imported my saved prefs and rebooted and… all is broken again ![]()
there is something really wrong here.
I had to redo the new install to get all back working.
BTW, I don’t really get why updating the system would break so many stuff ??? never get this when upgrading my Debian machines.
Now a new problem rose : I get watchdog crashes alot, and that is freezing the operations of the nas ![]()
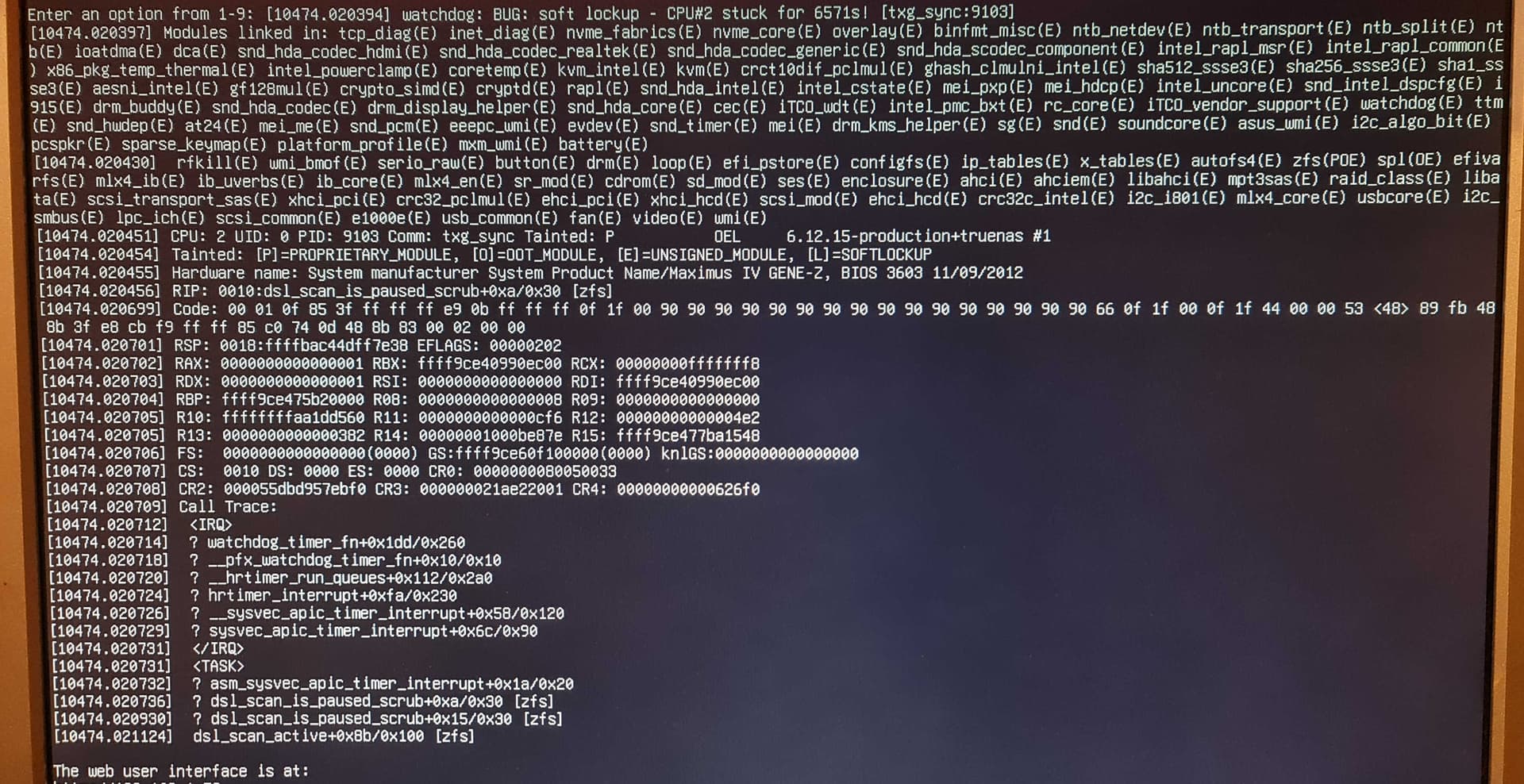
and see that ix-etc.service fails too (was getting this with last 24.10 version too before )
about 1 min after been run, it fails to generate the truenas etc files and die.
btw the boot continue and the menu is shown.
the watchdog bug shows in the hour that follow.
look at the pic…
now why can happen that this damn’ watchdog stays stuck and bring down the nas ?
any clues ?
Ho! a question : would it be possible in a near future to have the possibility to choose what prefs to import back in a newly install system ? aka I would like to import the datasets prefs with their acl, smb and nfs stuff, etc, passwords and users, and apps prefs, letting all the other stuff not imported. as the zpools prefs comes with importing it that would suffice and possibly not break anything…
can it be done ?
Hello Folks ! ^^)
Huge 2026 update to the thread : PROBLEM SOLVED ! (almost ![]() )
)
I’ve ditched the old shitty Int*l platform (mobo and cpu) as it was the real reason for all my problems !
and replaced it by a shinny speady Gigabyte Ryzen 5 Pro one with ECC mem ^^) just look at my updated setup below ![]()
The effect of this has been immediate : resilvering the whole 120 TB NAS took ONLY 1 Day 6 Hours instead of nearly 15 Days with the old stuff ! What a HUGE improvement !!! I’m on cloud 9 there ^^)
I recovered ALL my files despite the annouced dead disks and zillions of irecoverable errors before !
only 1 on 16 disks shows 1 bad block.
In fact, after the resilver and poping out the 2 ‘dead disks’ I’ve found it to be perfectly sane and am using it in another machine without issues since.
All I’ve lost is the 3 last installed apps (youtube downloader, PDF editing stuff and another I don’t remind)
so the only problem (as the ‘almost’ resolved says) is that my zpool is importable and mounted in the right place, but the apps stuff is unavailable due to these errors.
I think I can just do a ‘zpool clear’ stuff to get rid of this, and get the Zpool ‘usable’ again, what do you think ?
should I ?
Doing this clear should be enough to get the shares available again over network… am I right ?
Look at this :
Status Report
Linux VoxelNas 6.12.33-production+truenas #1 SMP PREEMPT_DYNAMIC Wed Dec 17 21:17:21 UTC 2025 x86_64
TrueNAS (c) 2009-2025, iXsystems, Inc. dba TrueNAS
All rights reserved.
TrueNAS code is released under the LGPLv3 and GPLv3 licenses with some
source files copyrighted by (c) iXsystems, Inc. All other components
are released under their own respective licenses.
For more information, documentation, help or support, go here:
http://truenas.com
Warning: the supported mechanisms for making configuration changes
are the TrueNAS WebUI, CLI, and API exclusively. ALL OTHERS ARE
NOT SUPPORTED AND WILL RESULT IN UNDEFINED BEHAVIOR AND MAY
RESULT IN SYSTEM FAILURE.
Last login: Wed Feb 11 07:09:02 CET 2026 on pts/0
truenas_admin@VoxelNas[~]$ sudo zpool import -fFX -R /mnt VoxelZ2
truenas_admin@VoxelNas[~]$
truenas_admin@VoxelNas[~]$ zpool status
pool: VoxelZ2
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: Message ID: ZFS-8000-8A — OpenZFS documentation
scan: resilvered 12.7T in 1 days 06:09:28 with 46 errors on Fri Jan 23 00:43:30 2026
expand: expansion of raidz2-0 in progress since Thu Feb 27 15:19:37 2025
5.28T / 118T copied at 188K/s, 4.48% done, paused for resilver or clear
config:
NAME STATE READ WRITE CKSUM
VoxelZ2 DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
aab036a6-7e2b-4632-b16d-cd7866845e5e ONLINE 0 0 0
7a8f8da1-836b-4a4c-9eaa-2aa29da2beb7 ONLINE 0 0 0
a10d9ac9-ef2c-4ede-9e6b-eba01e901361 ONLINE 0 0 0
9f2dce88-cde7-4923-b0bb-bf4de890ea52 ONLINE 0 0 0
181fbb56-496c-4540-a107-d35504e0d61b ONLINE 0 0 0
96d445ec-e8b2-42ce-8f1a-63ca963eead9 ONLINE 0 0 0
b4dbc538-a334-417c-9b6a-7265693bc710 ONLINE 0 0 0
fd7f4ef7-237a-48c0-8a72-bebaf1cd3fb5 ONLINE 0 0 0
83e62634-a0a5-4c2f-abb8-10b763833042 ONLINE 0 0 0
ea3b911a-d478-4341-b4cd-4549385fcdde ONLINE 0 0 0
52c0cc19-1576-4186-b41f-8ee005e7ebaf ONLINE 0 0 0
ee9542ae-6266-4615-bcaa-6a0f06dafb87 ONLINE 0 0 0
0b764a40-fd5d-4631-922d-625178717347 ONLINE 0 0 0
e0df314c-cc1e-460e-9591-842264306d5b ONLINE 0 0 0
af112e1e-211c-4061-a0bf-4e7f943903ca ONLINE 0 0 0
15096135188792341576 UNAVAIL 0 0 0 was /dev/disk/by-partuuid/c2c7b568-7eff-4f85-998b-eb4e1ac51897
ebd9e063-ebb9-4bdb-9ac6-3302a748390a ONLINE 0 0 0
cache
b7523e48-e07b-4fbb-94c5-c6de97a7d33c ONLINE 0 0 0
spares
67741fad-0683-4df2-ad52-c0c30405c419 UNAVAIL
errors: 46 data errors, use ‘-v’ for a list
pool: boot-pool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
nvme0n1p3 ONLINE 0 0 0
errors: No known data errors
truenas_admin@VoxelNas[~]$ sudo zpool status -v
[sudo] password for truenas_admin:
pool: VoxelZ2
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: Message ID: ZFS-8000-8A — OpenZFS documentation
scan: resilvered 12.7T in 1 days 06:09:28 with 46 errors on Fri Jan 23 00:43:30 2026
expand: expansion of raidz2-0 in progress since Thu Feb 27 15:19:37 2025
5.28T / 118T copied at 188K/s, 4.48% done, paused for resilver or clear
config:
NAME STATE READ WRITE CKSUM
VoxelZ2 DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
aab036a6-7e2b-4632-b16d-cd7866845e5e ONLINE 0 0 0
7a8f8da1-836b-4a4c-9eaa-2aa29da2beb7 ONLINE 0 0 0
a10d9ac9-ef2c-4ede-9e6b-eba01e901361 ONLINE 0 0 0
9f2dce88-cde7-4923-b0bb-bf4de890ea52 ONLINE 0 0 0
181fbb56-496c-4540-a107-d35504e0d61b ONLINE 0 0 0
96d445ec-e8b2-42ce-8f1a-63ca963eead9 ONLINE 0 0 0
b4dbc538-a334-417c-9b6a-7265693bc710 ONLINE 0 0 0
fd7f4ef7-237a-48c0-8a72-bebaf1cd3fb5 ONLINE 0 0 0
83e62634-a0a5-4c2f-abb8-10b763833042 ONLINE 0 0 0
ea3b911a-d478-4341-b4cd-4549385fcdde ONLINE 0 0 0
52c0cc19-1576-4186-b41f-8ee005e7ebaf ONLINE 0 0 0
ee9542ae-6266-4615-bcaa-6a0f06dafb87 ONLINE 0 0 0
0b764a40-fd5d-4631-922d-625178717347 ONLINE 0 0 0
e0df314c-cc1e-460e-9591-842264306d5b ONLINE 0 0 0
af112e1e-211c-4061-a0bf-4e7f943903ca ONLINE 0 0 0
15096135188792341576 UNAVAIL 0 0 0 was /dev/disk/by-partuuid/c2c7b568-7eff-4f85-998b-eb4e1ac51897
ebd9e063-ebb9-4bdb-9ac6-3302a748390a ONLINE 0 0 0
cache
b7523e48-e07b-4fbb-94c5-c6de97a7d33c ONLINE 0 0 0
spares
67741fad-0683-4df2-ad52-c0c30405c419 UNAVAIL
errors: Permanent errors have been detected in the following files:
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/netdata-meta.db
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/dbengine/journalfile-1-0000001650.njf
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/dbengine/journalfile-1-0000001654.njf
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/dbengine/journalfile-1-0000001656.njf
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/dbengine/datafile-1-0000001660.ndf
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/netdata-meta.db-wal
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/dbengine/journalfile-1-0000001655.njf
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/dbengine/journalfile-1-0000001657.njf
VoxelZ2/.system/netdata-5a0a2a47cd884dbcbe527966286bfc29:/dbengine-tier1/datafile-1-0000000129.ndf
VoxelZ2/.system/netdata-ae32c386e13840b2bf9c0083275e7941:/netdata-meta.db-wal
VoxelZ2/.system/netdata-ae32c386e13840b2bf9c0083275e7941:/dbengine-tier1/datafile-1-0000000001.ndf
VoxelZ2/.system/netdata-ae32c386e13840b2bf9c0083275e7941:/dbengine/datafile-1-0000000001.ndf
pool: boot-pool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
nvme0n1p3 ONLINE 0 0 0
errors: No known data errors
truenas_admin@VoxelNas[~]$
As seen, expansion by 1 disk is stalled 'till clear, I’m going to forget that expansion.
Soon I will add 7 * 28 TB DataCenter Grade HDDs to this setup, create a brand new RaidZ3 pool and copy over all the old one files, then kill the old 15*10 TB disks RaidZ2 pool, pop out the disk 1 with bad block and repurpose the old disks.
Looking for your enlightments ^^)
Jeff
Looks like your hot-spare kicked in. By default hot-spares are temporary so assuming you would like to keep the hot-spare config going forward you will need to replace the failed drive and after resilver the hot-spare will go back to being a spare again.
You should be able to delete those permanent error files and do a zpool clear and then run a scrub again.
Not sure about expansion thats still voodoo to me.
True, but with a bit of research up front you could have created a pool with two 8-wide RAIDZ2 vdevs. Your single vdev is too wide for reliable and performant operation. It was your choice, not TrueNAS’ to create the pool that way.
Well, my choice, but as I see racks with 60 HDDs as 1 pool in datacenters I wasn’t aware that I couldn’t do the same here while using the same ZFS filesystem ![]()
BTW, could you please remind me of the correct syntax for the ‘clear’ stuff, and tell me if it will suffice to get rid of the problem ?
Please note that the ‘unavail’ disk isn’t part of the pool, it’s just an hotspare. as stated I don’t want to expand the pool anymore.
Thanks by advance.