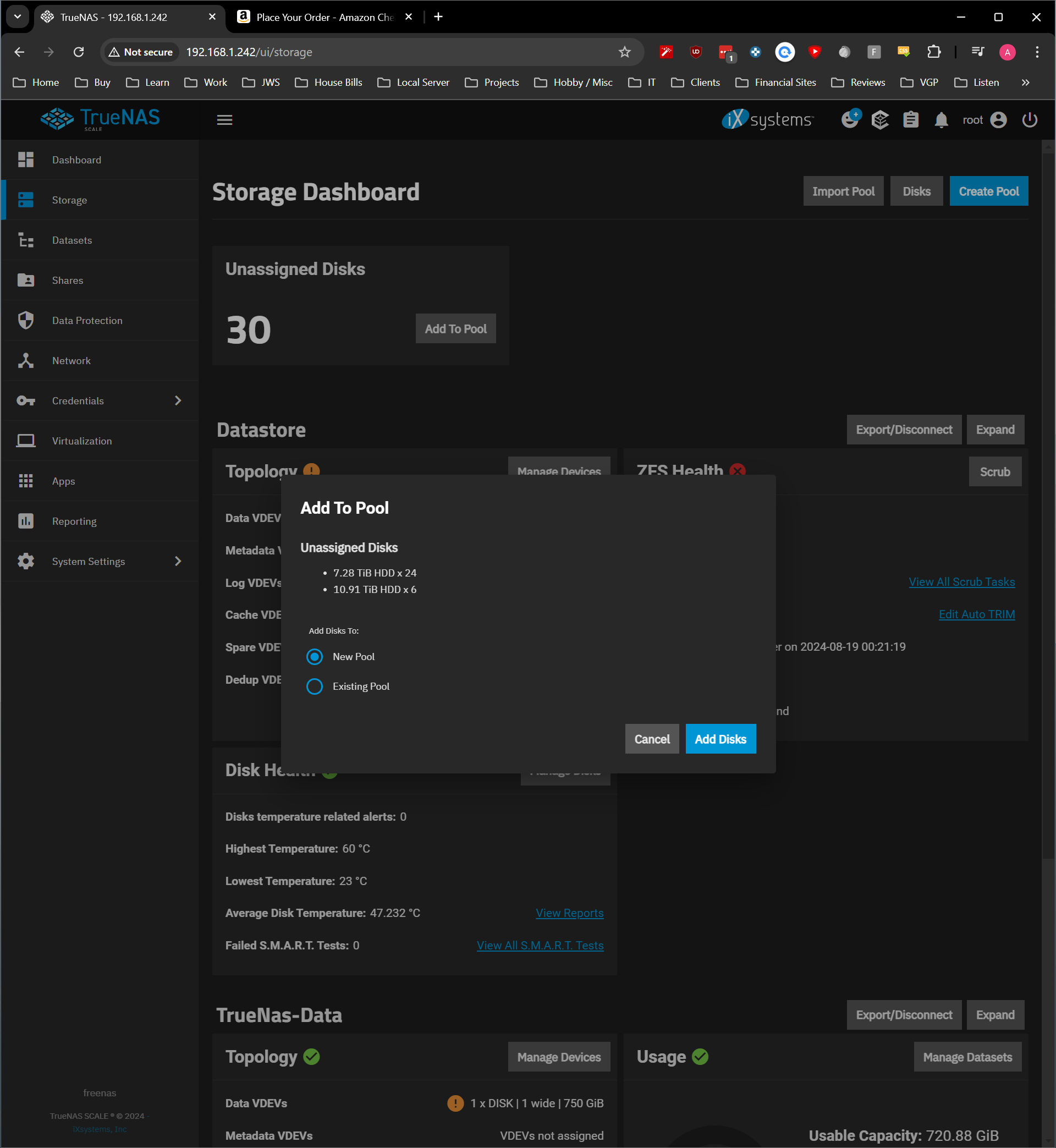
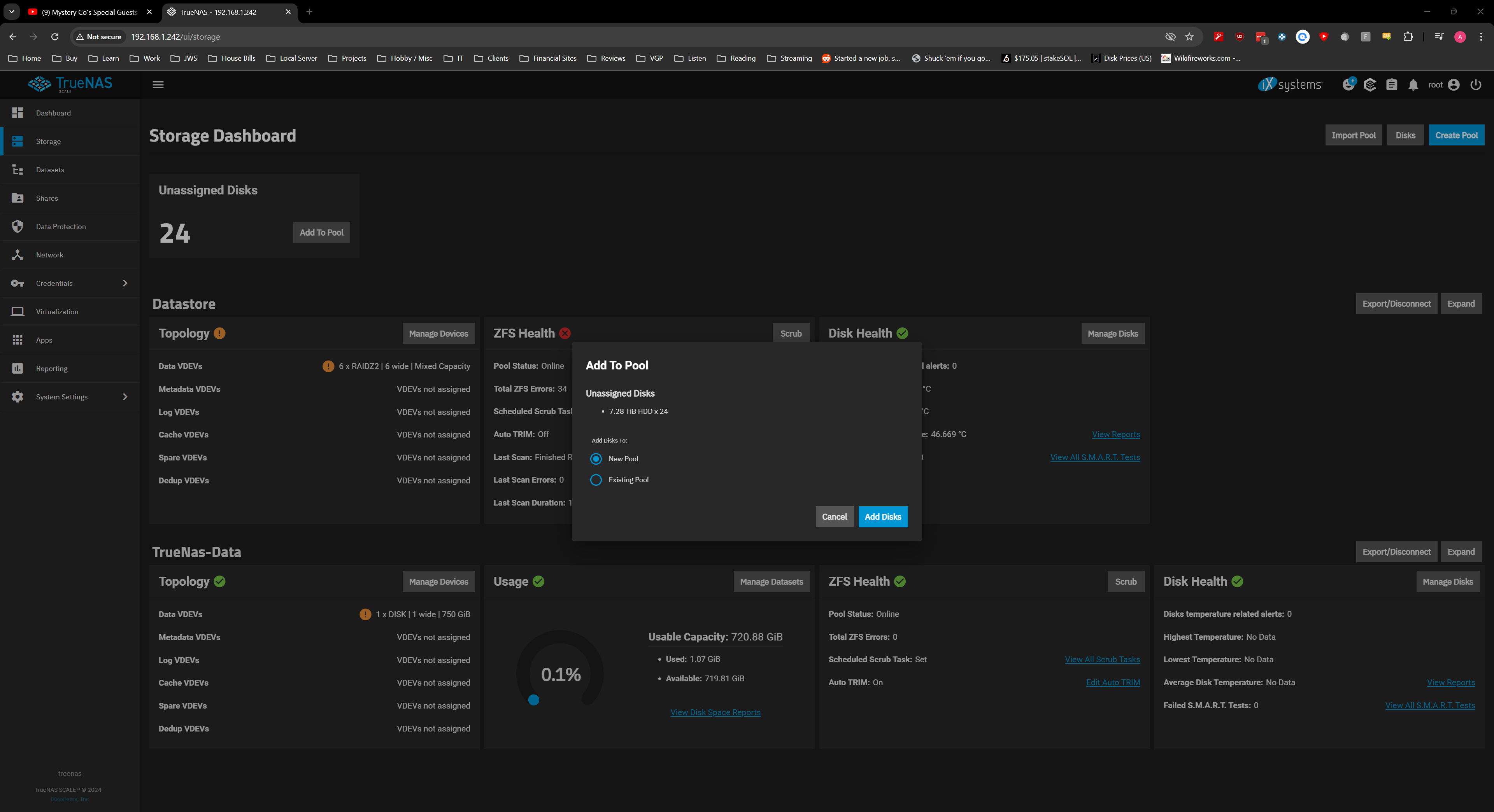
Still showing the 8TB drives as unassigned but if I go to Zpool Status they now show as online.
Doing a zpool clear to see what happens
Still showing the 8TB drives as unassigned but if I go to Zpool Status they now show as online.
Doing a zpool clear to see what happens
Same thing. Tried both IOM6’s in the DAS.
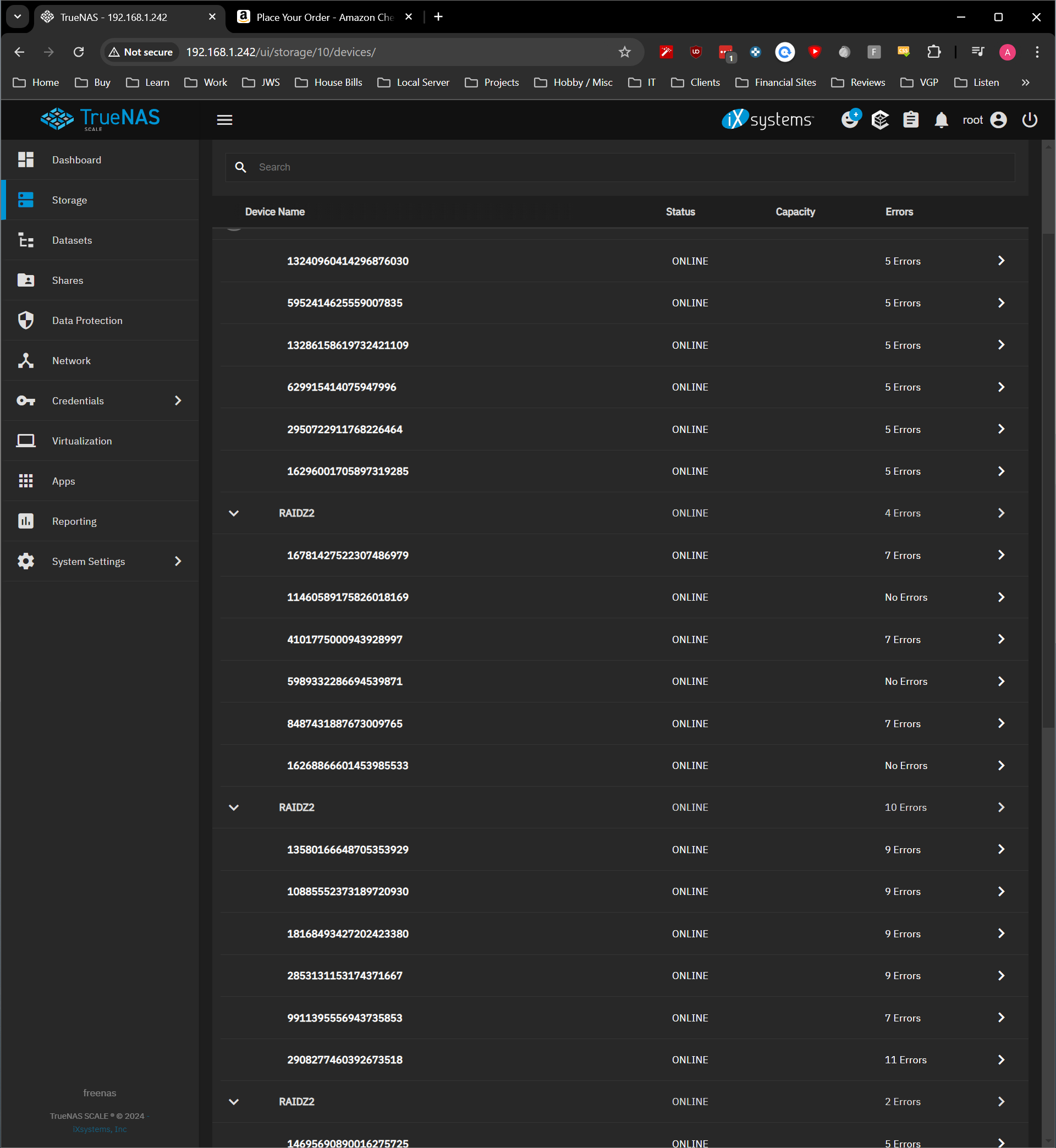
Disks all appear to be showing up but when I go to the “devices” tab in the pool some of the disk still show up like this:
Some of the disk will be added to the pool (Mostly the last 2 set of 12TB and 16 TB drives but not always.
Any advice?
Things I have tried:
Swapped the cables to the other port on the LSI controller
Swapped the cables from the top shelf to the bottom
Swapped the cables and ports on the shelfs
Turned everything off, let it sit, turned it all back on again
Powered off the shelf and turned it back on with Truenas on
Swapped both “new” IOM6 Controllers in
Tried zpool clear and zpool clear -F
Swapped IOM6 over to another slot and connected
Blacklisted the driver for the LSI card and rebooted
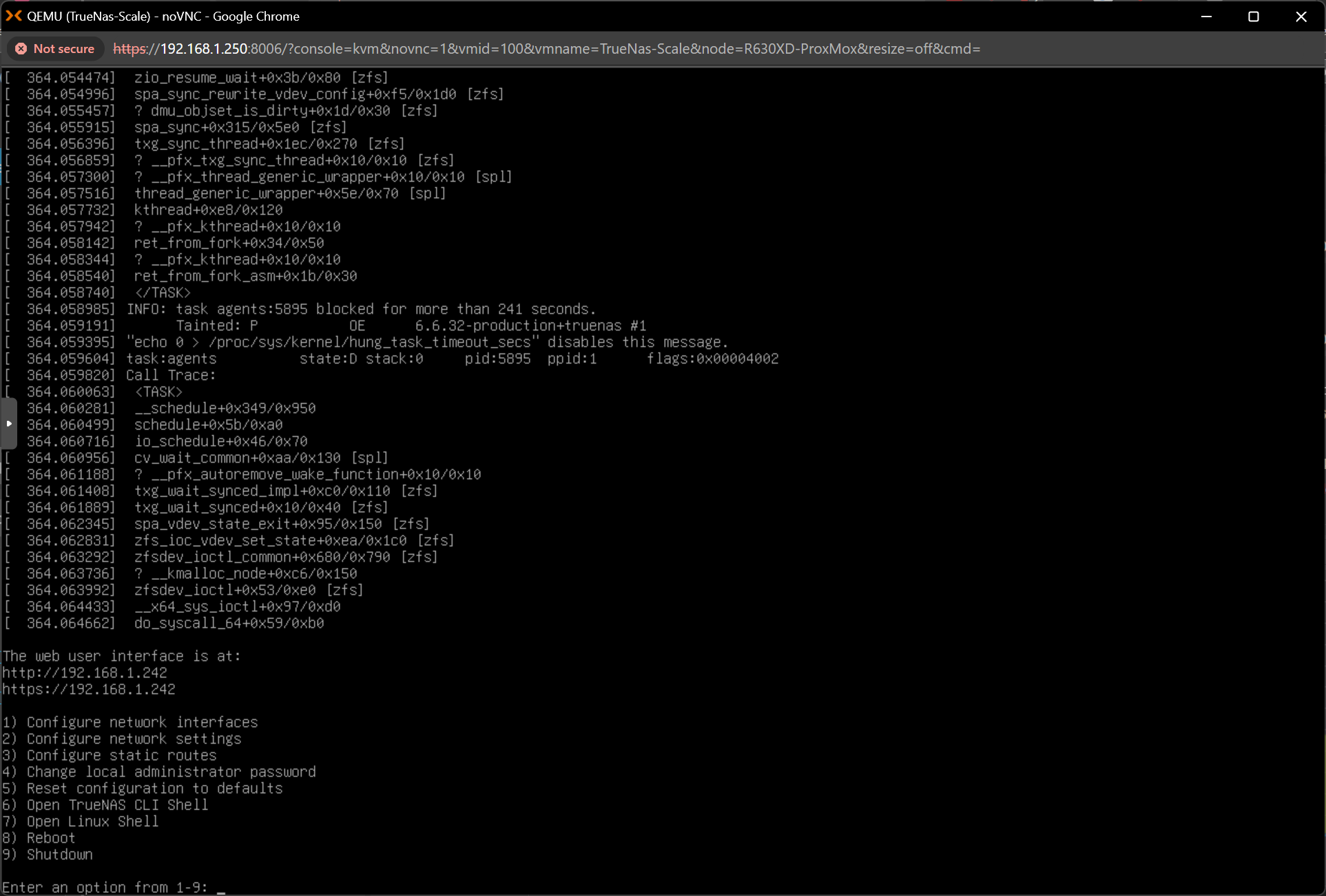
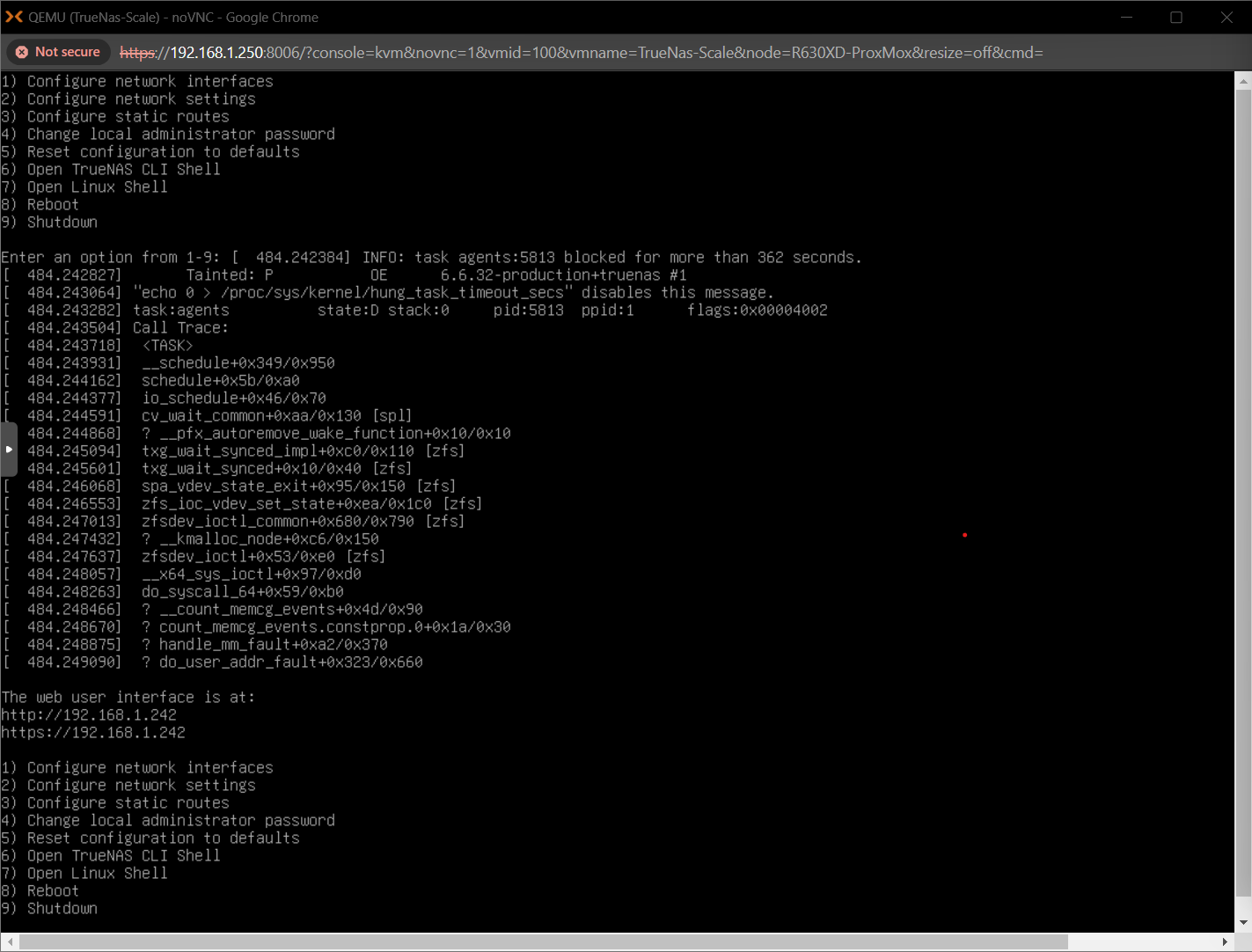
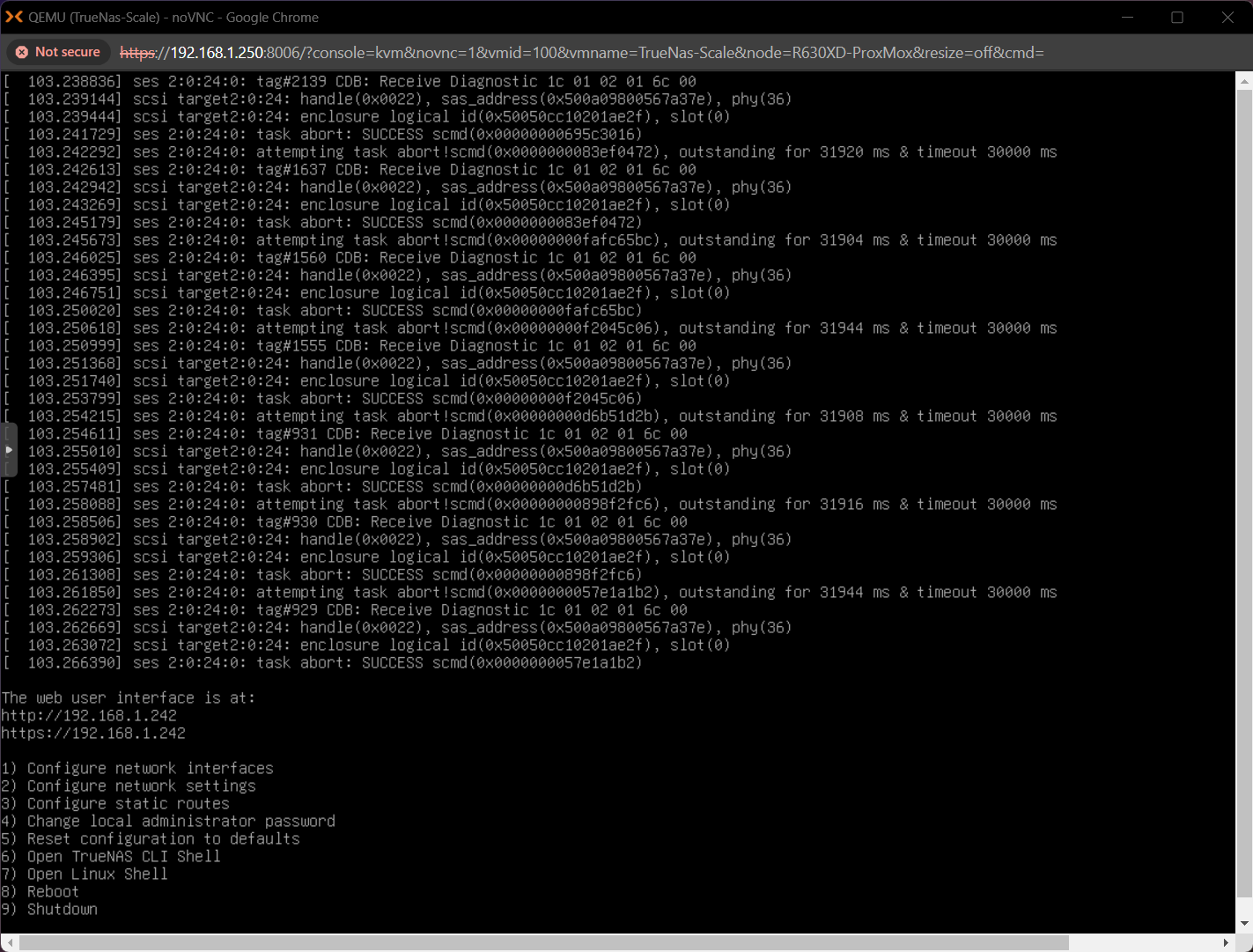
So interesting update, looks like after a fresh reboot of everything.
Its all come back online and boots but the NetApp reboots and gives me those error messages in my last message.
Is there any way to grab all those messages?
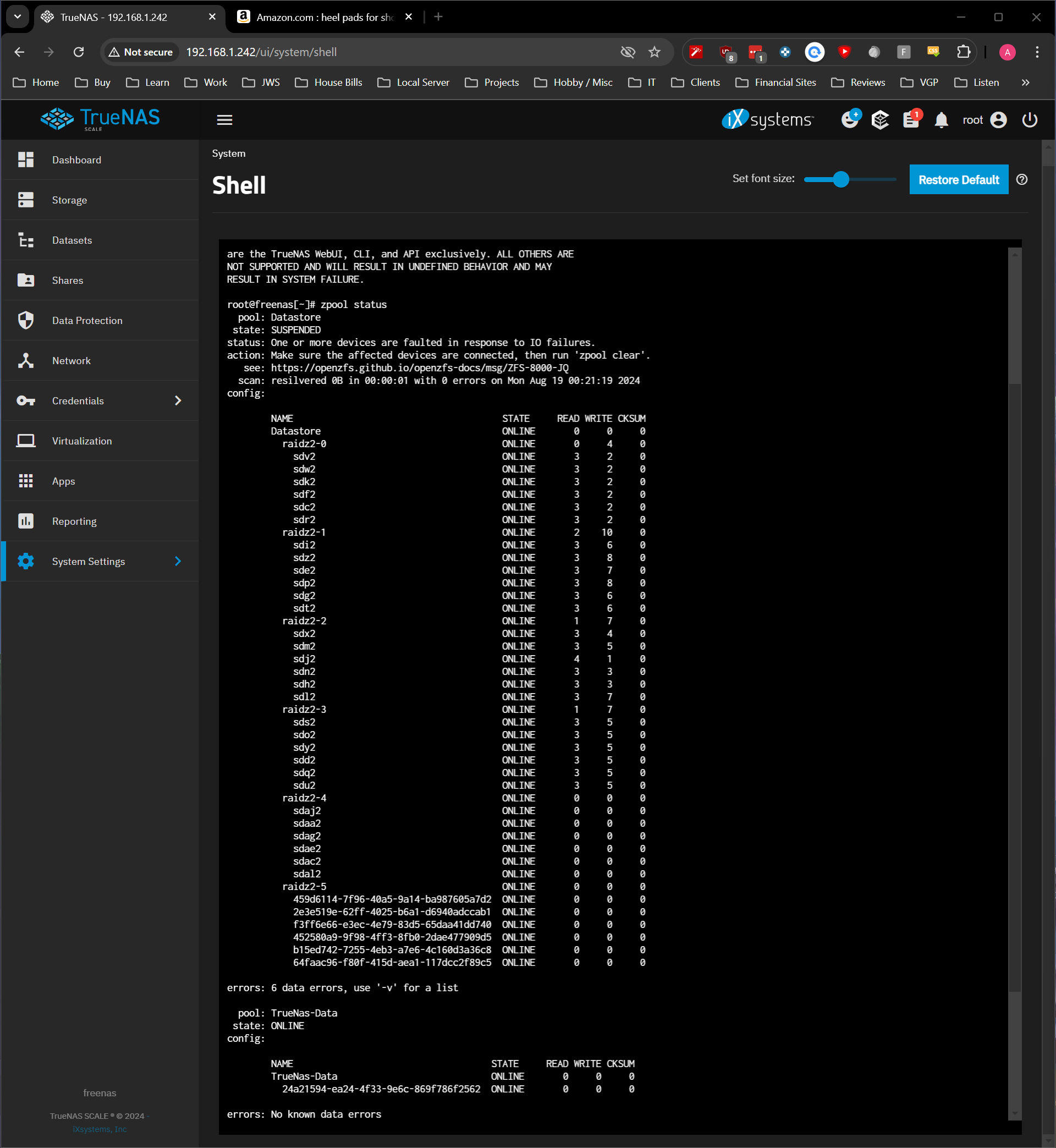
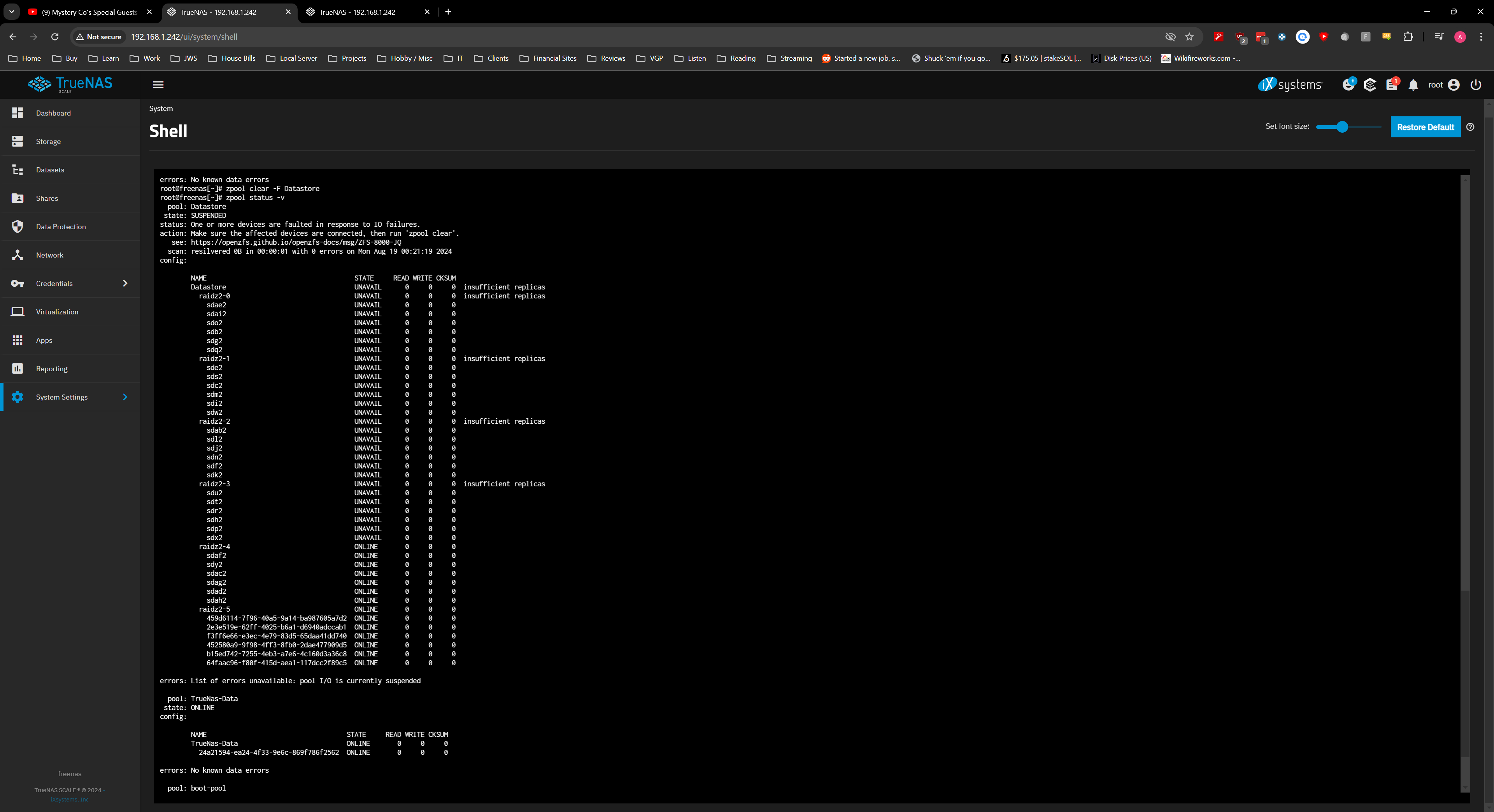
So right now it seems like the disk are there, and they are known to TrueNas that the are suppose to go to the pool:
But they are in the unassigned disk area:
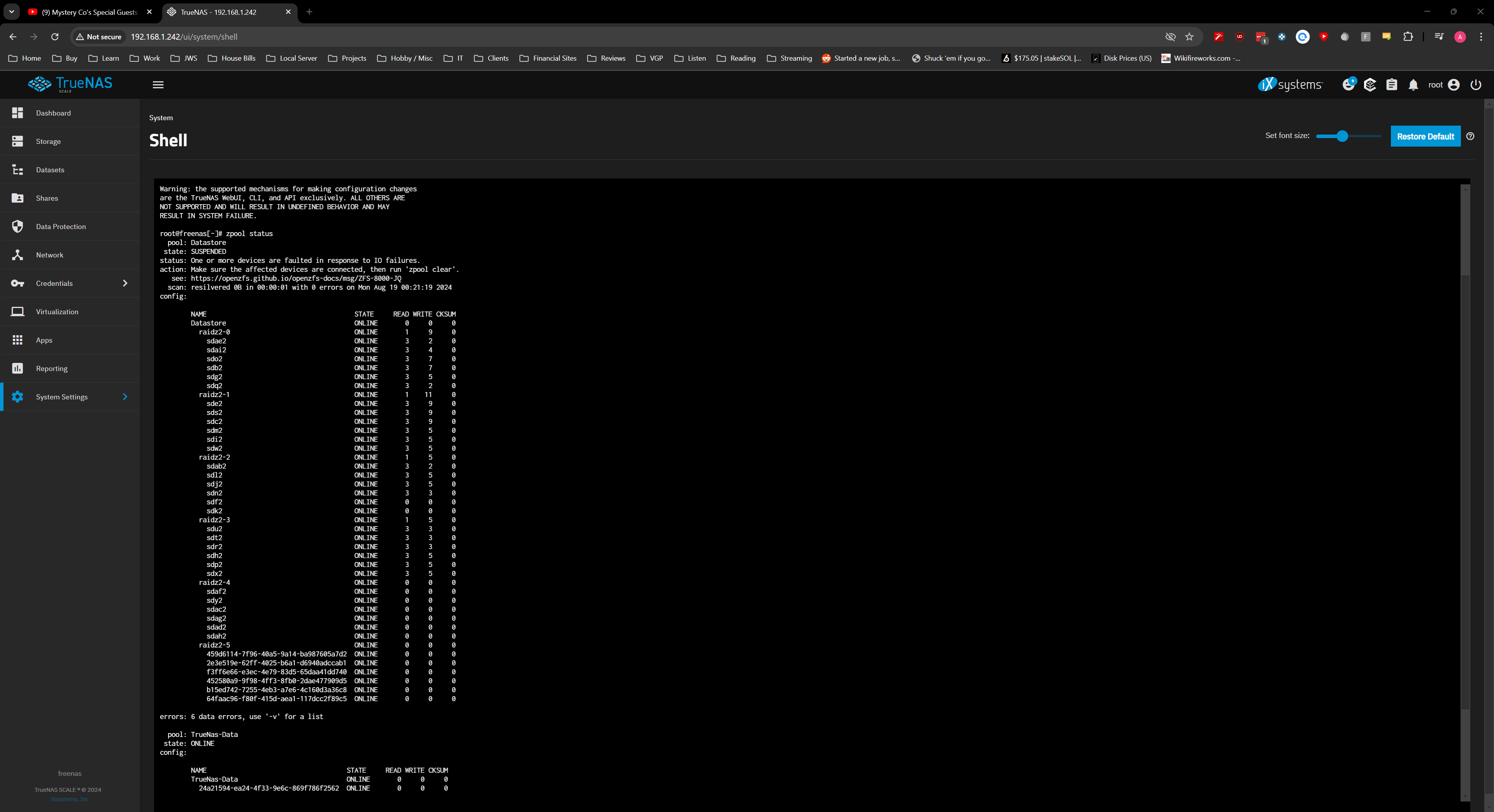
" zpool status " shows the disk assigned to the pool and online but shows that the devices are faulted in response to IO failures.
and a -v gives
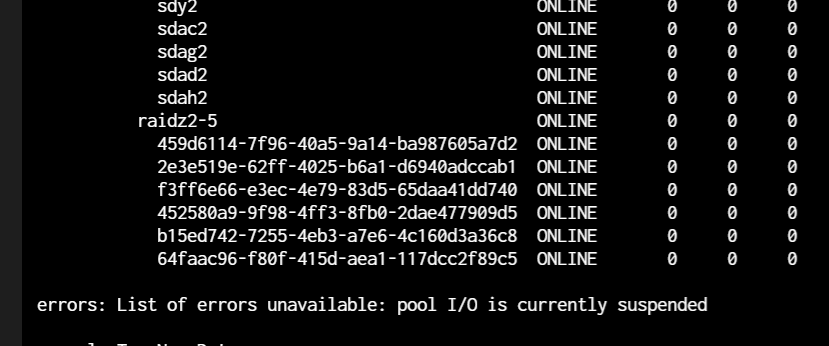
if I run a “zpool clear” it gives me this:
Yeah.
This is what it can be like when you suffer a catastrophic hardware failure… like tripping over a SAS cable… etc.
Pools get suspended, all hell breaks loose…
But then you re-attach everything… shutdown… reboot… things go nuts…
and then its like … “what? everything’s fine.”
…until it’s not. ![]()
Suggesting dropping a nuke there if you have backup.
Nah, if it scrubs good, it is good.
Thank you and @Davvo for the replies.
This was maybe in the 20-25 reboot and then it fixes itself area… so its really a head scratcher.
1.) I do have an offsite backup that was only 2 days old at the time on Backblaze. Never had to rip it all down so no idea how long that will take.
2.) The plan before it blew up & during was to rebuild. All these drive are sucking down power so I have 12 22TB drives arriving today to replace them all. We will see how that goes.
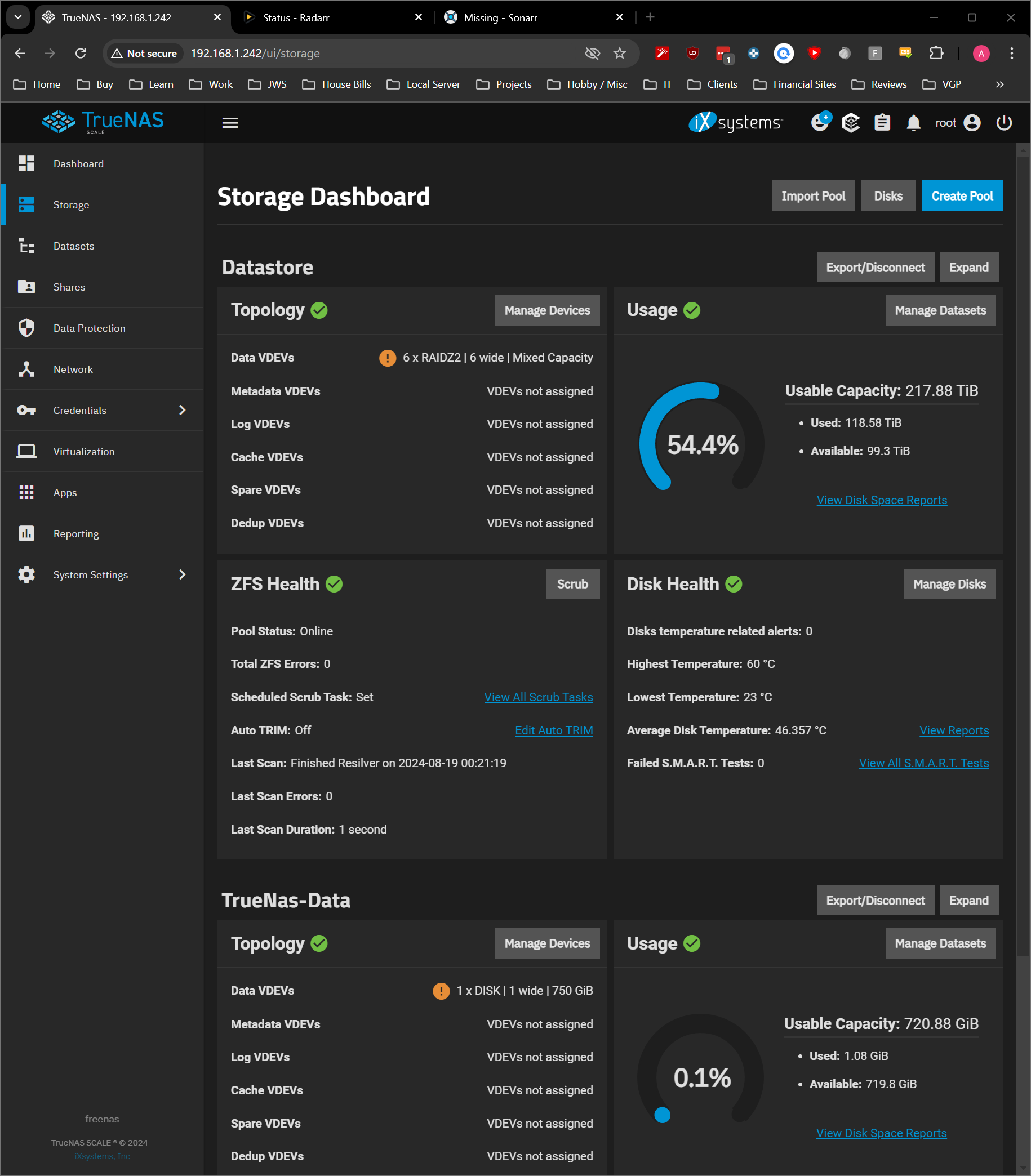
Let it sit over night to make sure it was stable.
Started a scrub not too long ago and will see how it responds.
Still running good.
Scrub is at 61%. No problems since then
Current plan is to migrate all the data to a new pool and revert back to one disk shelf once complete.
Does anyone have any advice on the best way to accomplish that?
How much data are we talking about?
Right now, 120TB
Waiting on the rest of the drives to show up
Since you have a backup I would totally make sure the drives and everything between them and the motherboard is in working condition[1], then I would:
Do note that this might not be required, but it’s what I would feel compelled to do if I were in your situation. A good old wipe gives me peace of mind.
including testing to make sure things don’t get messy as soon as you illude yourself you have achieved stability. ↩︎
Well, I posted this a at some point in this thread, but I have been working on migrating to 22TB drives from the mismatched pairs I have to save on power draw and complexity.
I’m 50/50 on destroying the whole thing and even more so on restoring from cloud backup.
Right now my plan is:
1.) Setup new pool with new drives
2.) Transfer all data over to new drives
3.) Remove but NOT delete old pool and see how it all runs.
Yay, science! Let us know how the old pool will behave.