Had some problems with my TrueNas instance and noticed it after about a day.
From what I could tell, I had over allocated RAM and it was running in swap for a while and caused everything to go into ultra slow mode.
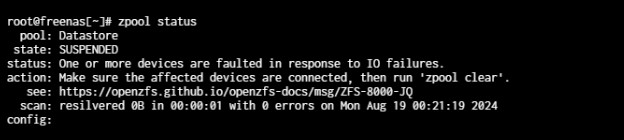
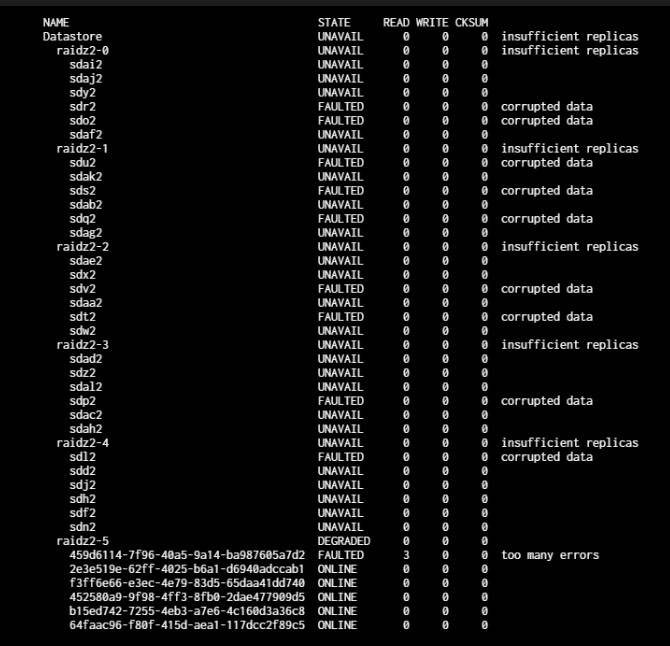
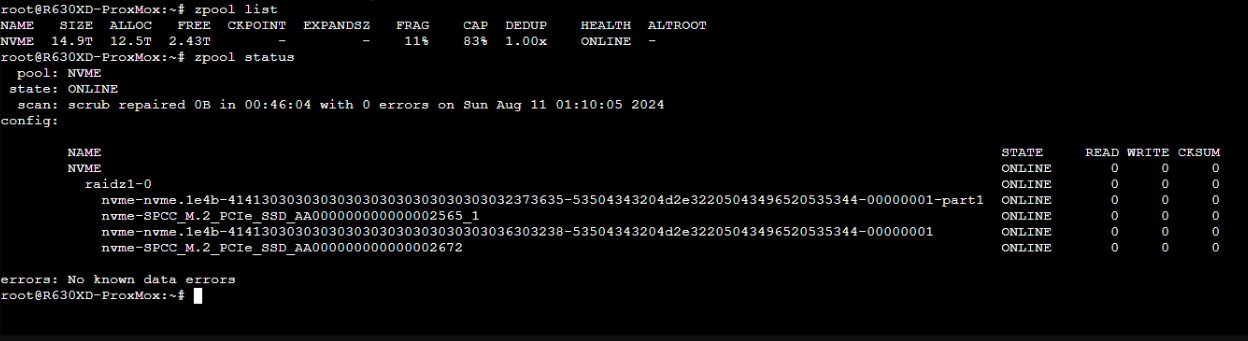
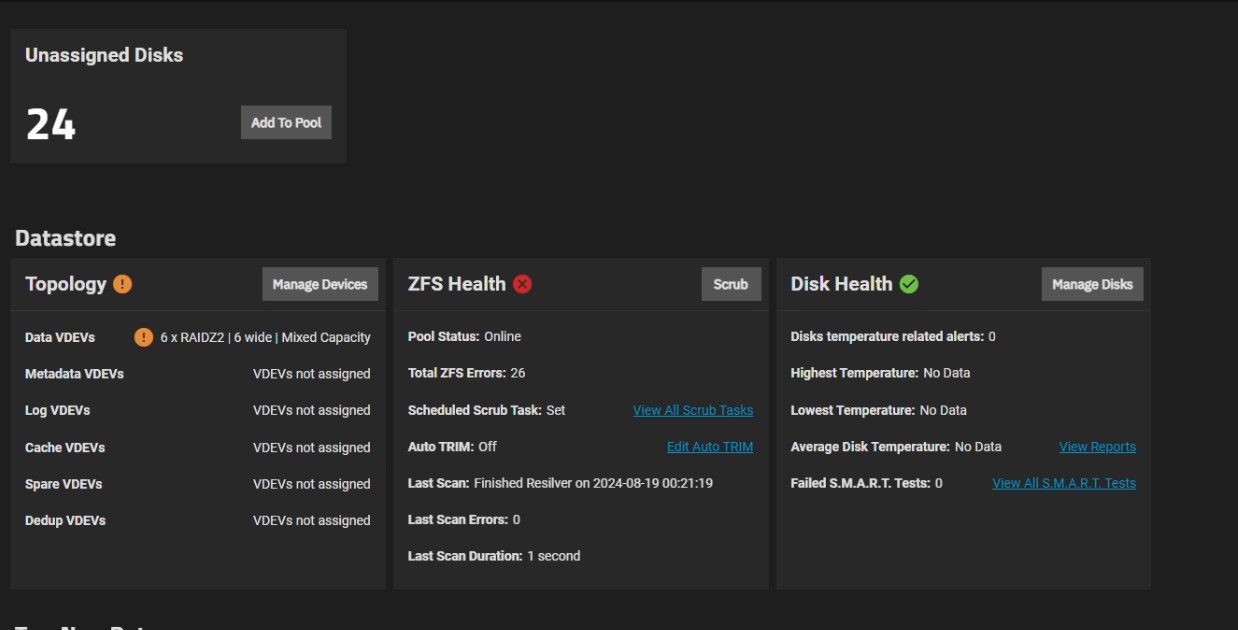
Assume this state for a while caused issues with the pool. This is the current state of the pool.
@Poetart does your Proxmox host OS show the pool under a zpool list or zpool status command? HBA passthrough should be enough to keep it separated (as both host and guest can’t simultaneously attach to the physical PCIe device) but I’d like to make sure it’s properly doing that and not using a raw device passthrough instead.
A pool with suspended I/O - especially if it also holds the system dataset - can well be blocking the regular shutdown process.
Do you by any chance have multipath SAS configured from your head unit to your SAS shelves? I believe the top controller in your NetApp shelves is the primary module - do you have anything cabled to the secondary (lower) controller in each shelf?
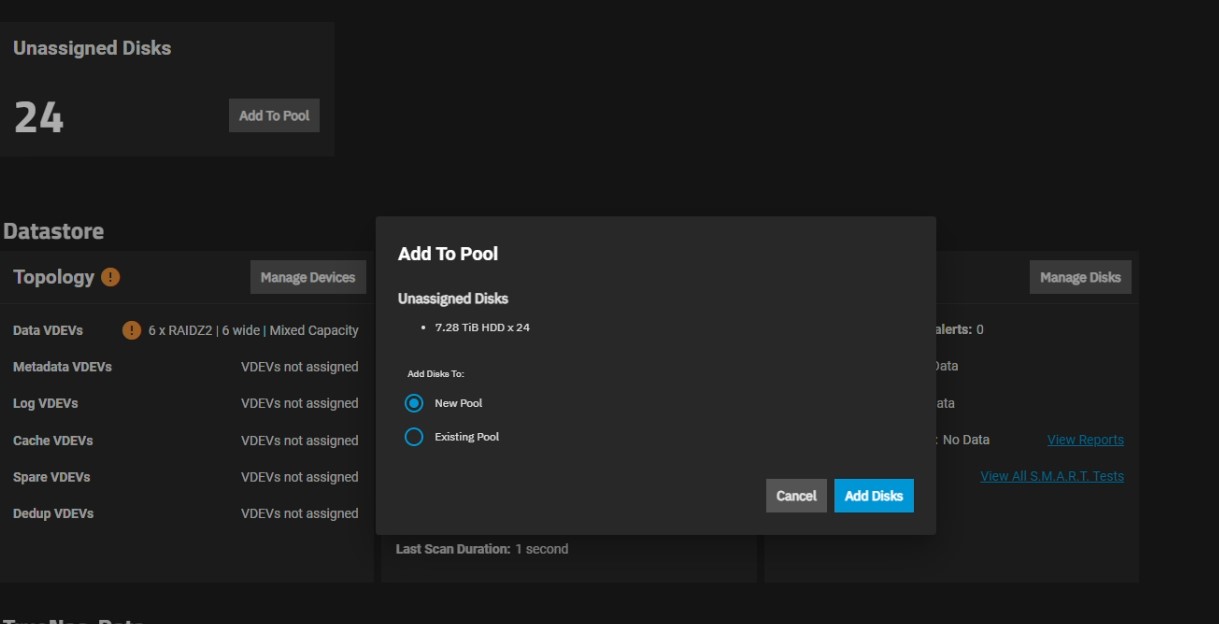
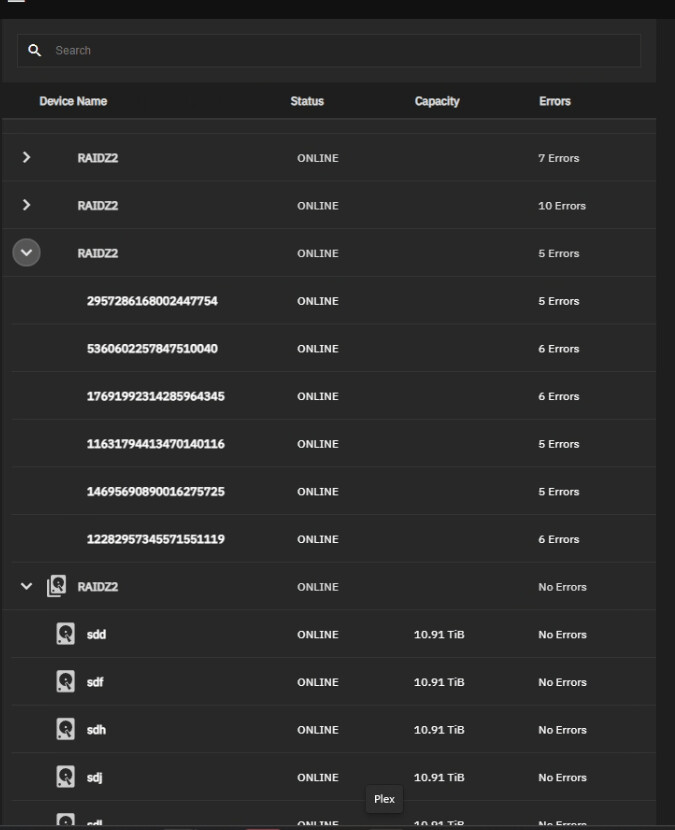
Sounds like no multipath, which is good; but your 24 unassigned disks makes me think a controller may have failed in the 24-bay unit.
In your shoes, I’d shut down the system, swap the controllers (not the cables, the controllers) in your top 24-bay system, and see if the disks are detected properly.