You can create snapshots on the destination dataset of a replication, but they will have to be destroyed before anotehr replication from the source can be performed.
end of story.
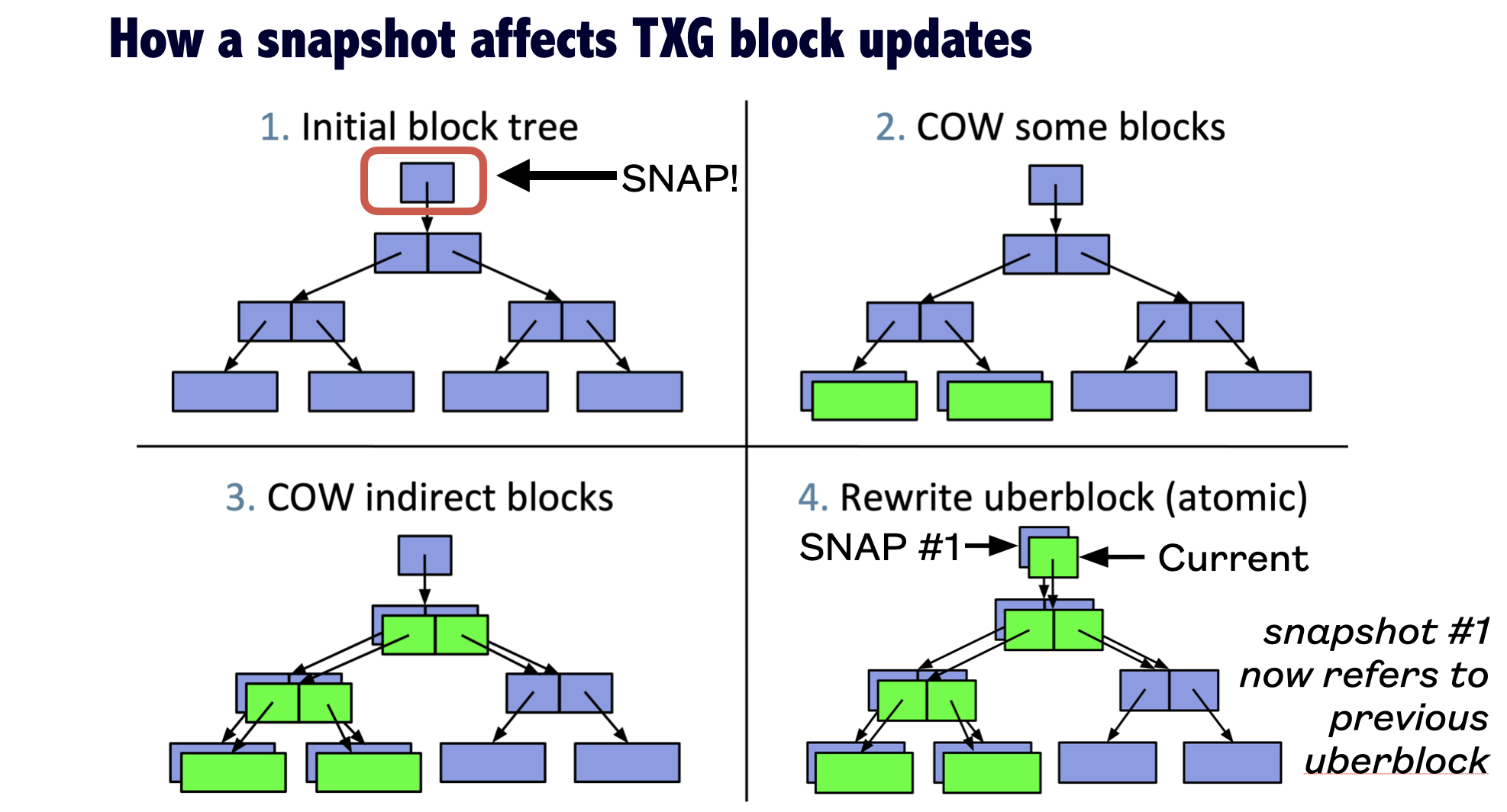
The low down technical reason is that each snapshot requires an uber-block update, and the destination has to be rolled back to the previous uber-block (ie snapshot) in order to roll forwards with the updated sequence of blocks in the replication.
(to be fair, I’m actually not 100% clear on how this actually works with respect to datasets, but basically, a snapshot is a reference to a specific uberblock)
Ergo, if you rollback the source, and then were to replicate that change to the destination, it would rollback the destination too.
That could irretrievably lose the data that was “backed up” to the destination, ergo, once you rollback the source, which irretrievably loses data on the source, it requires manual intervention to replicate that rollback to the destination.
If you create a snapshot on the destination, even if there are no changes, then the next replication to that destination (doesn’t matter if its pull or push) will only be able to proceed, once the destination is rolled back to the most recent snapshot that both the source and destination have in common, which is what the “replicate from scratch” checkbox does
the “same as source” option means that when the replication completes, any snapshots that are part of the replication set (ie based on schema etc) will be deleted from the destination if no longer present on the source.
Now, you can configure a custom deletion policy for a schema, not sure if this is supported in the replication ui, but that would allow you to customize when a certain snapshot scheme is deleted. And you could then add a snapshot task to take those snapshots… which expires very quickly… BUT if the replication task is set to hold pending snapshots, and use a custom expiry on the destination, then that accomplishes the ephemeral snapshot on the source, but long retention on the destination, while allowing other ephemeral snapshots to have shorter retentions.

 by Matt Ahrens")