About a year and a half ago, I set up my NAS to replicate the OS pools from my Proxmox hosts. I wrote up the process here:
For the sake of simplicity (or at least so I thought), I set up zfSnap on each of the Proxmox hosts to manage the snapshots there (take 1 every hour, retain for five days), and set up a pull replication task on the NAS to replicate those over.
It’s mostly been working well–zfSnap has been handling the snapshots on the PVE hosts, TrueNAS has been replicating them, all good. Except…
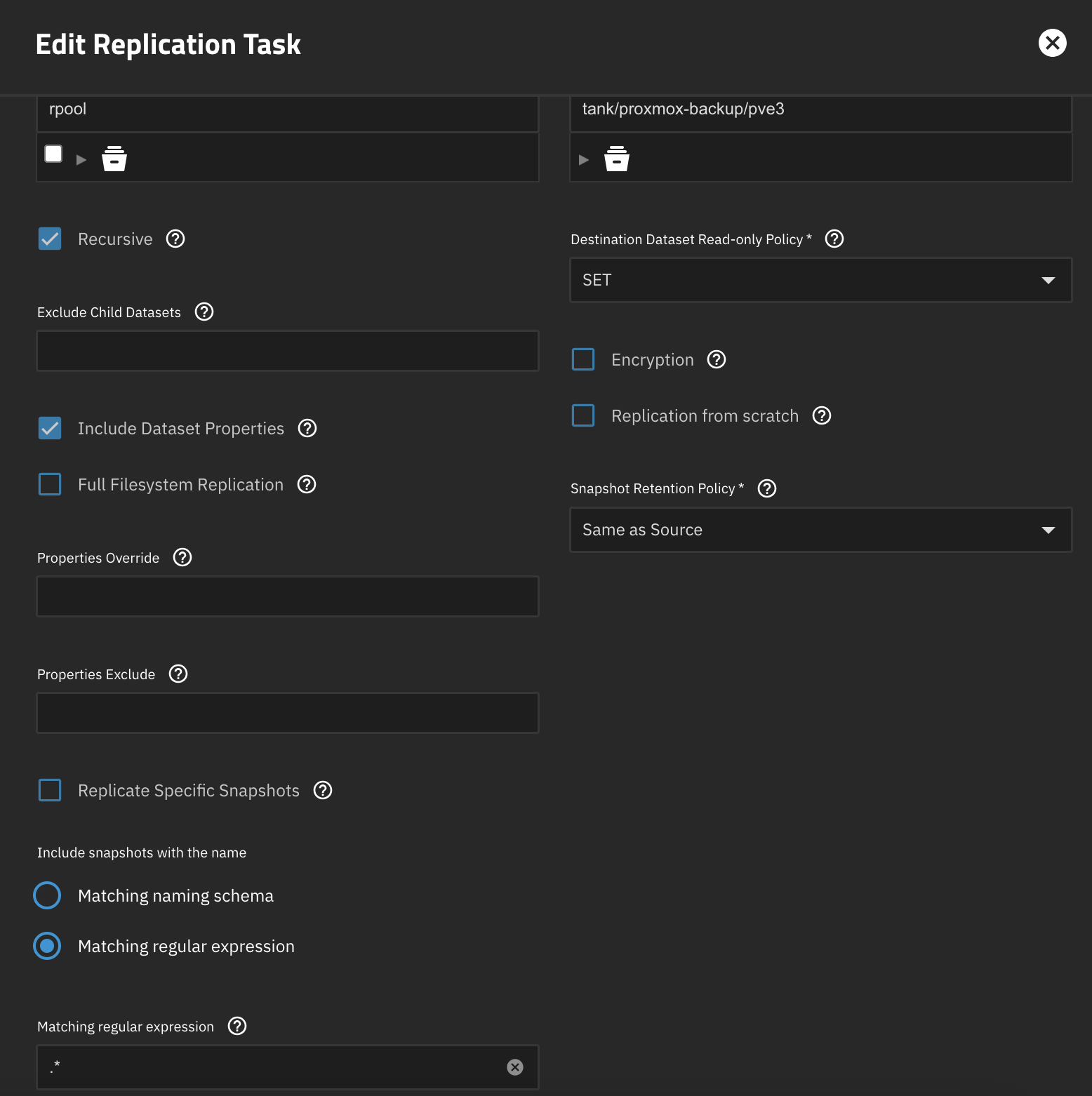
I’d been getting–and ignoring–alerts from my NAS that it has too many snapshots. Today, I decided to investigate. And I had ~175k snapshots, 173k of which were from these replication tasks, going back almost a year. Clearly, the “quick and dirty” setup I did is missing something, that being the part that only keeps on the NAS the snapshots that are on the source. It looks to me as though the replication settings should do that:
but clearly that isn’t the case–the retention policy of “same as source” doesn’t mean that when a snapshot’s gone on the source system, it’s removed on my NAS.
I’m suspecting the naming convention of the snapshots is playing into this, but I’m not quite sure what to do about it. The snapshot names zfSnap is generating look like rpool/data@2025-05-06_13.58.01--5d.
Any thoughts on how to get this working as expected?
I could be wrong, but I’ll chime in until someone with better understanding of TrueNAS’ internals jumps in.
I believe “Same as Source” only applies if the source (local if “Push”, remote if “Pull”) is also a TrueNAS server and/or uses zettarepl in the backend.
EDIT: Never mind. I was thinking of the -F flag on the zfs recv side, which it appears TrueNAS’ GUI does not expose.
This was incorrect. Disregard.
You could try “Full Filesystem Replication”.
What this should do is outright destroy any snapshots on the target that do not exist on the source. (I use this feature myself for my command-line replications, and it works as intended. The flag it invokes is -R.)
I see that I’ve set the task to include snapshots matching a regex of .*, or everything. I’m wondering if setting it to “Schema” would make a difference. As an experiment, I’ve set one of the tasks to use a schema of %Y-%m-%d_%H.%M.%S--5d. I wonder if that will convey the “retention policy” to the middleware–I’ll see when the next replication task finishes.
Without the -F on the zfs recv side, and without zettarepl on the source, then I don’t believe there’s anything that communicates a retention policy for the system pulling in snapshots.
Let’s hope your change works.
Maybe there’s a way to invoke -F on the receiver’s side? I don’t see any option in the GUI that would suggest this, though.
It doesn’t seem it should be too difficult to do “keep all, and only, the snapshots that are on the source.” But there’s a lot I don’t know about the internals of TrueNAS, obviously.
I’m not, in principle, opposed to using a different tool on the PVE boxen to manage the snapshots, and it looks like zettarepl can do this–but from what I can see from the README (https://github.com/truenas/zettarepl), it looks like it pretty much runs as a daemon without actually being a daemon, or something.
This is possible with the -F flag on the zfs recv side. (I use it myself, and can confirm with a verbose -v flag that it destroys datasets/snapshots on the receiving side that are missing from the source.)
It’s a matter of exposing this option in the GUI.
I don’t think iX will implement it in TrueNAS, since it sidesteps around zettarepl and its management of expired snapshots.
So the schema is the solution. That now leaves the question of why. It’s obvious TrueNAS isn’t limiting its own snapshots to those on the source. So it must be the case that it’s parsing the schema and determining from that how long snapshots should be kept. That isn’t what I’d expect.
How does it know how long the snapshots should be kept?
There is no snapshot task on the local TrueNAS server that zettarepl uses to determine expiration.
The replication task does not specify a retention time.
You chose “Same as Source”. Well, where does the source specify this? I’d guess that zfSnap manages this itself. So how does zettarepl (locally on the TrueNAS side) know about this?
My only guess would be that there is some fallback logic where zettarepl parses the -5d at the end of the snapshot name and interprets this as its lifespan. (i.e, 5 days)
Therefore, if a snapshot is named “@backup-2025-05-01-5d” and zettarepl runs today on May 6, it will be pruned by zettarepl if it is not part of any Periodic Snapshot Task that has its own expiration policy set.
That’s a good question. The naming schema does specify it (the --5d part), but does TrueNAS (i.e., zettarepl apparently) parse that? It’s kind of looking like it. And I’m not quite sure how I feel about that–on the one hand it’s clever; on the other it seems it could be dangerous.
Of course, all I have to go on right now are my observations and some (perhaps somewhat informed) speculation. But if it isn’t doing “keep whatever’s on the source” (and it isn’t), I don’t know what other explanation there is.
And BTW, destroying tens of thousands of snapshots takes quite a bit of time.
You also have to use care when setting up Periodic Snapshot Tasks, as it is possible to accidentally delete older snapshots if you have multiple tasks that use the same exact naming convention.
This makes sense in the context of “TrueNAS only”. Even snapshots that only have a creation timestamp in their name (e.g, “@2025-05-01”) will be properly pruned by a Periodic Snapshot Task that has a defined lifetime set.
There is no need to use a naming schema that appends an expiry, such as -5d or -2m. (None of my snapshots have this added to their name, yet they are all properly pruned as defined in the Periodic Snapshot Task.) zettarepl uses the lifespan set in the Periodic Snapshot Task to determine what to prune when compared against the parsed “date” in the snapshot’s name.
That’s why it’s odd that zettarepl “knows” which of @dan’s snapshots to prune. There is no expiration defined by a task on either the source or target. The source is not even TrueNAS and uses zfSnap to manage snapshots.
The only usable piece of information has to be the -5d appended to the snapshot names.
I wonder how the TrueNAS Replication Task would handle pruning these same snapshots if they did not have -5d at the end of their names?
Not only that… but it feels like we’re playing with a black box. The tooltips make no mention about adding anything to the end of a snapshot name to manage pruning.
What if someone changes their mind and they want to extend the lifespan to 3 months for all snapshots, including the ones that were already created? Are they expected to manually rename the existing snapshots from -5d to -3m to prevent their pruning? Obviously, changing anything on the other end (zfSnap) would not communicate this new expiration policy, if zettarepl is only reading the names of existing snapshots.
That’s a relatively-recent (well, it’s happened since I’ve been using Free/TrueNAS) change–at some point in the past, the lifespan of a snapshot was part of its name if it was created by a periodic snapshot task. I don’t remember when the change happened, though.
I don’t believe that was ever done (or proposed) automatically.
I just recommend it to prevent accidental unwanted pruning if multiple tasks are configured for the same dataset. It also makes it easier to review your existing snapshots.