If you use Drive-Selftest I would setup the parameters like this:
Short_Test_Mode=2 # 1 = Use Short_Drives_to_Test_Per_Day value, 2 = All Drives Tested (Ignores other options), 3 = No Drives Tested.
Short_Time_Delay_Between_Drives=1 # Tests will have a XX second delay between the drives starting testing.
Short_SMART_Testing_Order="DriveID" # Test order is for Test Mode 1 ONLY, select "Serial" or "DriveID" for sort order. Default = "Serial"
Short_Drives_to_Test_Per_Day=1 # For Test_Mode 1) How many drives to run each day minimum?
Short_Drives_Test_Period="Week" # "Week" (7 days) or "Month" (28 days)
Short_Drives_Tested_Days_of_the_Week="1,2,3,4,5,6,7" # Days of the week to run, 1=Mon, 2=Tue, 3=Wed, 4=Thu, 5=Fri, 6=Sat, 7=Sun.
Short_Drives_Test_Delay=130 # How long to delay when running Short tests, before exiting to controlling procedure. Default is 130 second should allow.
# Short tests to complete before continuing. If using without Multi-Report, set this value to 1.
### LONG SETTINGS
Long_Test_Mode=1 # 1 = Use Long_Drives_to_Test_Per_Day value, 2 = All Drives Tested (Ignores other options), 3 = No Drives Tested.
Long_Time_Delay_Between_Drives=1 # Tests will have a XX second delay between the drives starting the next test.
Long_SMART_Testing_Order="Serial" # Test order is either "Serial" or "DriveID". Default = "Serial"
Long_Drives_to_Test_Per_Day=1 # For Test_Mode 1) How many drives to run each day minimum?
Long_Drives_Test_Period="Week" # "Week" (7 days) or "Month" (28 days)
Long_Drives_Tested_Days_of_the_Week="1,2,3,4,5,6,7" # Days of the week to run, 1=Mon, 2=Tue, 3=Wed, 4=Thu, 5=Fri, 6=Sat, 7=Sun.
Now let me tell you what this does. First you must setup a CRON Job to run once everyday. This will perform a SHORT test on all drives within a 1 week period (7 days).
It will test Mon, Tue, Wed, Thu, Fri, and Sat. You could change Short_Drives_Tested_Days_of_the_Week="1,2,3,4,5,6,7" to “1,2,3,4,5” if you do not want to test Saturday and Sunday. You still want the CRON to run daily.
There is a 130 second delay, it’s purpose is to let any Short tests complete so they can be reported in Multi-Report. If you are using Drive-Selftest as stand-alone, you can change this value to “0”.
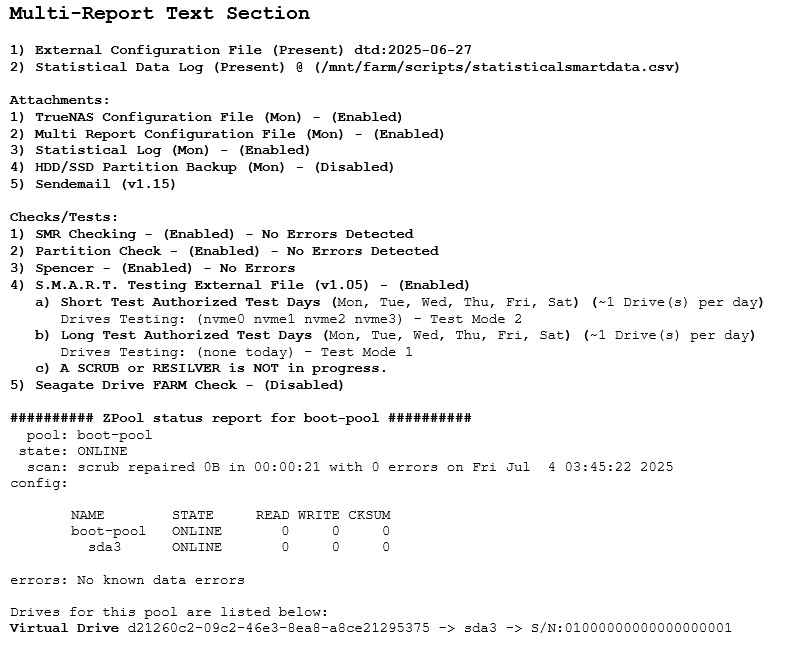
Here is the beauty of this script, you don’t have to tell it how many drives you have. It will do them all. And if a SCRUB is going on, any drives scheduled for a LONG test would be changed to a SHORT test to cause minimal impact to the system. If a RESILVER is going on, no drives are tested.
To answer your question above, SHORT every day, LONG once a week but space the drives out two a day. If using the GUI, that is one entry for the SHORT tests, plus four more entries for the LONG test. My script, one CRON Job.
You have 8 drives, this means my script would automatically run a SHORT test on all drives everyday, and a automatically run a LONG test on two drives a day until all drives were tested. Mon (2 drives), Tue (2 drives), Wed (2 drives), Thu (the last two drives).
If you decide to use this script, I am more than happy to help you configure it, but the default settings are Short every day, Long once a week.
Hopefully that more than answers your question. I know it was overkill, sorry about that. I know what it is like to lose a lot of data, several times and all due to hardware failure.