I’'m a complete beginner when it comes to building a NAS and TrueNAS.
- I created a RAIDZ1 pool (2x 20 TB drives) via the CLI and imported it into the UI.
- Then I extended it with another 20TB drive.
- After the expansion the pool was degraded and my third drive available, so I replaced the unavailable drive in the pool.
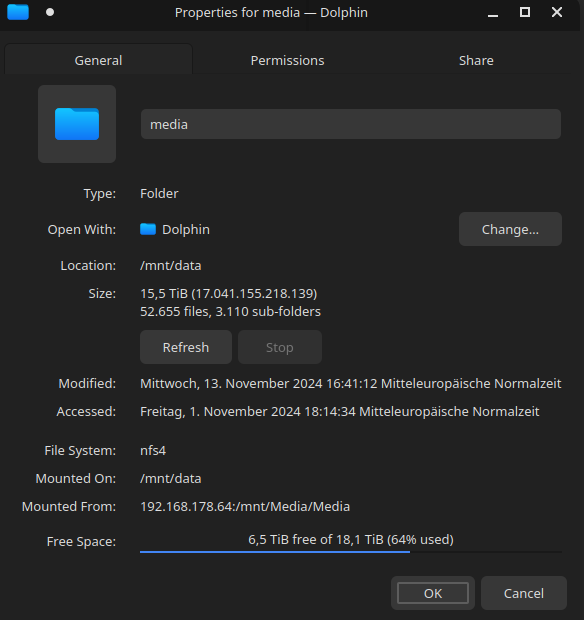
- Afterwards the usable capacity was 18,06 TB and the usage was almost 85%.
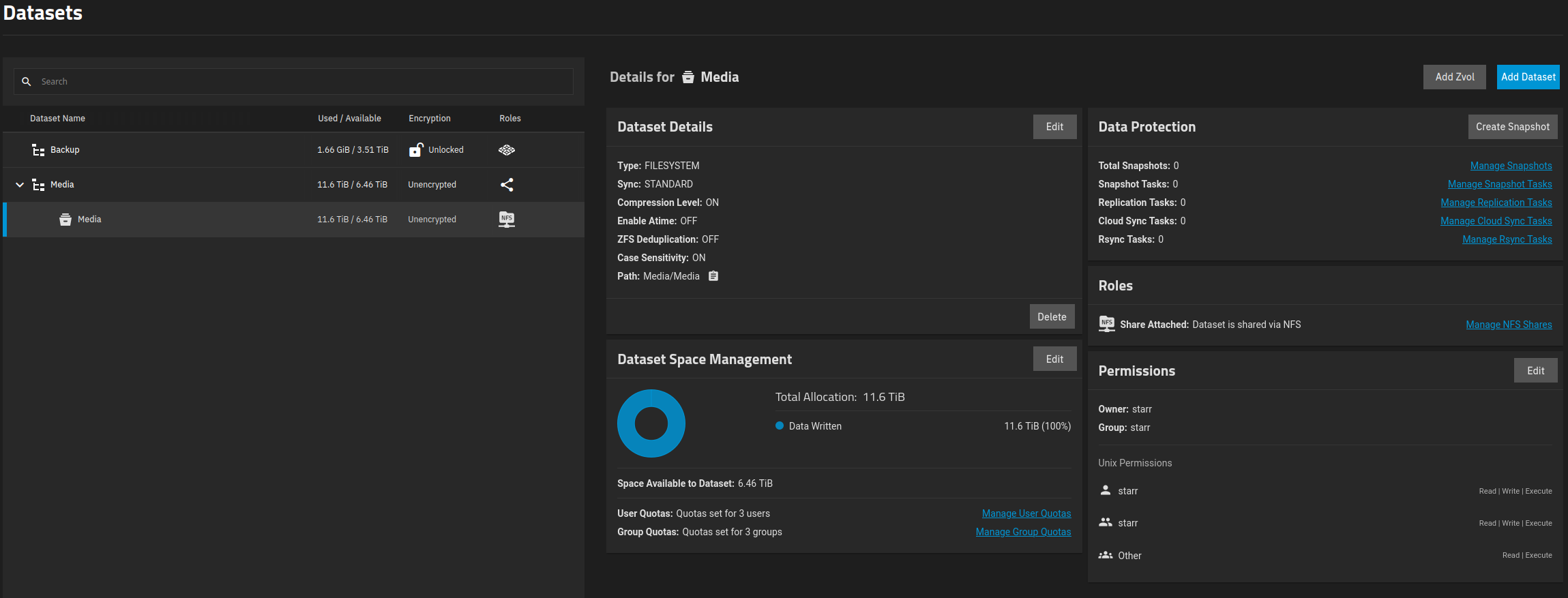
- I ran the rebalancing script and ended up with used capacity of 11,6 TB and 6,46 TB available (64,2% usage).
- The size of the data is actually shown as 15,5 TB (NFS share).
I’m at a bit of a loss what to do now. Is my pool set up correctly and the capacities are just incorrect?
Can I “fix” it in some way?
Some advice would be appreciated
Some info:
zpool status
pool: Media
state: ONLINE
scan: resilvered 10.5T in 13:11:58 with 0 errors on Mon Nov 11 02:18:33 2024
expand: expanded raidz1-0 copied 31.4T in 5 days 23:41:18, on Fri Nov 8 22:53:02 2024
config:
NAME STATE READ WRITE CKSUM
Media ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ata-TOSHIBA_MG10ACA20TE_5430A1JXF4MJ ONLINE 0 0 0
ata-TOSHIBA_MG10ACA20TE_5430A1JMF4MJ ONLINE 0 0 0
a5dcef47-d63c-4462-92cf-af0de65dc1c7 ONLINE 0 0 0
errors: No known data errors
zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
Media 36.4T 23.2T 13.2T - 18.2T 0% 63% 1.00x ONLINE /mnt
lsblk (one disk has no PTTYPE? sdb1 exists?)
NAME MODEL PTTYPE TYPE START SIZE PARTTYPENAME PARTUUID
sda TOSHIBA MG10ACA20TE disk 20000588955648
sdb TOSHIBA MG10ACA20TE gpt disk 20000588955648
└─sdb1 gpt part 2048 20000586858496 Solaris /usr & Apple ZFS a5dcef47-d63c-4462-92cf-af0de65dc1c7
sde TOSHIBA MG10ACA20TE disk 20000588955648
Storage

Datasets
NFS Share size