sfatula:
I would only comment that swap is normal and used widely in Debian and derivatives. If swap is actually itself causing the issue, then, there’s still a bug somewhere in Truenas. Seriously doubt there is a bug in swapping code, though there certainly has been and obviously new versions of things are on Scale and could be introduced.
Evidence seems to be that there are two safe modes:
ARC=50%… Swap can be enabled
ARC = 9x%… Swap should be disabled
The 3rd mode
This makes some sense… ZFS ARC hogs the RAM & forces apps and middleware into Swap space.
3 Likes
What about this, which we’re still waiting to hear some experiences:
ARC Max = “FreeBSD-like” (Dragonfish default, RAM - 1 GiB) + swap enabled + “swappiness” set to “1”
EDIT: Or maybe not. It’s already not looking like a viable option .
I have swap enabled and at 70% or so (memory fails me), the “safe modes” would be system dependent of course but I get your point. That’s how it’s always been done outside of Truenas. Admin picks number. But you wanted to improve that to let it handle on it’s own. Without swap, I don’t see how you can have 0 OOM errors though when under memory pressure with arc filling ram. You must have a way to avoid that. It’s always been a problem in the old days .
ZFS does hog the ram of course. If ZFS takes it first, and something else needs it (which in the past was rare except for things like VMs), ZFS can’t evict fast enough meaning swap. If your swap space is on HDD, then, not fast at all. I know they made changes such as this and others with the arc:
openzfs:master ← amotin:arc_evict
opened 05:39PM - 07 Jan 23 UTC
Traditionally ARC adaptation was limited to MRU/MFU distribution. But for years… people with metadata-centric workload demanded mechanisms to also manage data/metadata distribution, that in original ZFS was just a FIFO. As result ZFS effectively got separate states for data and metadata, minimum and maximum metadata limits etc, but it all required manual tuning, was not adaptive and in its heart remained a bad FIFO.
This change removes most of existing eviction logic, rewriting it from scratch. This makes MRU/MFU adaptation individual for data and metadata, same as the distribution between data and metadata themselves. Since most of required states separation was already done, it only required to make arcs_size state field specific per data/metadata.
The adaptation logic is still based on previous concept of ghost hits, just now it balances ARC capacity between 4 states: MRU data, MRU metadata, MFU data and MFU metadata. To simplify arc_c changes instead of arc_p measured in bytes, this code uses 3 variable arc_meta, arc_pd and arc_pm, representing ARC balance between metadata and data, MRU and MFU for data, and MRU and MFU for metadata respectively as 32-bit fixed point fractions. Since we care about the math result only when need to evict, this moves all the logic from arc_adapt() to arc_evict(), that reduces per-block overhead, since per-block operations are limited to stats collection, now moved from arc_adapt() to arc_access() and using cheaper wmsums. This also allows to remove ugly ARC_HDR_DO_ADAPT flag from many places.
This change also removes number of metadata specific tunables, part of which were actually not functioning correctly, since not all metadata are equal and some (like L2ARC headers) are not really evictable. Instead it introduced single opaque knob zfs_arc_meta_balance, tuning ARC's reaction on ghost hits, allowing administrator give more or less preference to metadata without setting strict limits.
Some of old code parts like arc_evict_meta() are just removed, because since introduction of ABD ARC they really make no sense: only headers referenced by small number of buffers are not evictable, and they are really not evictable no matter what this code do. Instead just call arc_prune_async() if too much metadata appear not evictable.
### How Has This Been Tested?
Manually simulating different access pattern I was able to observe expected arc_meta, arc_pd and arc_pm changes.
### Types of changes
- [ ] Bug fix (non-breaking change which fixes an issue)
- [x] New feature (non-breaking change which adds functionality)
- [x] Performance enhancement (non-breaking change which improves efficiency)
- [x] Code cleanup (non-breaking change which makes code smaller or more readable)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
- [ ] Library ABI change (libzfs, libzfs\_core, libnvpair, libuutil and libzfsbootenv)
- [ ] Documentation (a change to man pages or other documentation)
### Checklist:
- [x] My code follows the OpenZFS [code style requirements](https://github.com/openzfs/zfs/blob/master/.github/CONTRIBUTING.md#coding-conventions).
- [ ] I have updated the documentation accordingly.
- [ ] I have read the [**contributing** document](https://github.com/openzfs/zfs/blob/master/.github/CONTRIBUTING.md).
- [ ] I have added [tests](https://github.com/openzfs/zfs/tree/master/tests) to cover my changes.
- [ ] I have run the ZFS Test Suite with this change applied.
- [x] All commit messages are properly formatted and contain [`Signed-off-by`](https://github.com/openzfs/zfs/blob/master/.github/CONTRIBUTING.md#signed-off-by).
There are still lots of OOM happening in openzfs. A partial list of interesting ones below (not ones about corruption as that is different), but, the proof of course is your distribution base and if swapoff resolves all of the issues without OOM, then, that’s ok I guess. You have allowed ARC to grow to almost memory size so this is much different than the way people have typically run zfs. Time will tell for sure!
While your enterprise customers who have no issues and all have plenty of memory, my concern would be for the armchair Plex/converted home 10 year old computer guys with very little memory. They can be the ones with plenty of overuse. I guess guidelines can be changed, etc. If swap is simply now incompatible with zfs that allows filling ram with arc, then, your installer shouldn’t be adding it or asking to add it anymore. But other than telling people here, what about the people who don’t use the forums, how will they know to disable swap or maybe you can make it part of an update?
opened 02:47PM - 20 Feb 24 UTC
Component: Memory Management
Type: Defect
### System information
Ubuntu 22.04 running 6.2.0-1018-aws #18\~22.04.1-Ubuntu.…
zfs-2.1.5-1ubuntu6~22.04.2
zfs-kmod-2.1.9-2ubuntu1.1
on AWS u-12tb1.112xlarge x86_64 instance.
### Describe the problem you're observing
We are getting these message in dmesg:
```
[883114.230457] usercopy: Kernel memory exposure attempt detected from vmalloc (offset 975108, size 249596)!
[883114.240825] ------------[ cut here ]------------
[883114.240828] kernel BUG at mm/usercopy.c:102!
[883114.244737] invalid opcode: 0000 [#1] SMP NOPTI
[883114.248736] CPU: 87 PID: 3614547 Comm: python Tainted: P O 6.2.0-1018-aws #18~22.04.1-Ubuntu
[883114.256687] Hardware name: Amazon EC2 u-12tb1.112xlarge/, BIOS 1.0 10/16/2017
[883114.263562] RIP: 0010:usercopy_abort+0x6e/0x80
[883114.267546] Code: 76 9a a8 50 48 c7 c2 42 53 95 a8 57 48 c7 c7 50 c7 96 a8 48 0f 44 d6 48 c7 c6 f3 c7 96 a8 4c 89 d1 49 0f 44 f3 e8 f2 07 d2 ff <0f> 0b 49 c7 c1 a0 58 99 a8 4c 89 cf 4d 89 c8 eb a9 90 90 90 90 90
[883114.280934] RSP: 0018:ffffbc3498033b00 EFLAGS: 00010246
[883114.285235] RAX: 000000000000005c RBX: 0000000000000001 RCX: 0000000000000000
[883114.292197] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
[883114.299145] RBP: ffffbc3498033b18 R08: 0000000000000000 R09: 0000000000000000
[883114.306143] R10: 0000000000000000 R11: 0000000000000000 R12: ffffbc3c94605104
[883114.313346] R13: 000000000003cefc R14: 000000000003cefc R15: 0000000000000000
[883114.321434] FS: 00007fde416ff640(0000) GS:ffff990af24c0000(0000) knlGS:0000000000000000
[883114.329637] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[883114.334776] CR2: 00007fde38c8c000 CR3: 00000004a5036005 CR4: 00000000007706e0
[883114.342569] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[883114.350493] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[883114.358410] PKRU: 55555554
[883114.361890] Call Trace:
[883114.365554] <TASK>
[883114.368916] ? show_regs+0x72/0x90
[883114.372913] ? die+0x38/0xb0
[883114.376655] ? do_trap+0xe3/0x100
[883114.380867] ? do_error_trap+0x75/0xb0
[883114.384984] ? usercopy_abort+0x6e/0x80
[883114.389183] ? exc_invalid_op+0x53/0x80
[883114.393509] ? usercopy_abort+0x6e/0x80
[883114.397773] ? asm_exc_invalid_op+0x1b/0x20
[883114.402215] ? usercopy_abort+0x6e/0x80
[883114.406467] check_heap_object+0x149/0x1d0
[883114.410559] __check_object_size.part.0+0x72/0x150
[883114.414874] __check_object_size+0x23/0x30
[883114.418884] zfs_uiomove_iter+0x63/0x100 [zfs]
[883114.423666] zfs_uiomove+0x34/0x60 [zfs]
[883114.427620] dmu_read_uio_dnode+0xaf/0x110 [zfs]
[883114.431812] dmu_read_uio_dbuf+0x47/0x70 [zfs]
[883114.435988] zfs_read+0x13a/0x3e0 [zfs]
[883114.440063] zpl_iter_read+0xa3/0x110 [zfs]
[883114.444165] vfs_read+0x219/0x2f0
[883114.447724] __x64_sys_pread64+0x9e/0xd0
[883114.451556] do_syscall_64+0x59/0x90
[883114.455217] ? __rseq_handle_notify_resume+0x2d/0xf0
[883114.459653] ? exit_to_user_mode_loop+0xf1/0x140
[883114.463971] ? exit_to_user_mode_prepare+0xaf/0xd0
[883114.468577] ? irqentry_exit_to_user_mode+0x17/0x20
[883114.472852] ? irqentry_exit+0x21/0x40
[883114.476599] ? exc_page_fault+0x92/0x190
[883114.480376] entry_SYSCALL_64_after_hwframe+0x73/0xdd
[883114.484631] RIP: 0033:0x7fe0b511278f
[883114.488275] Code: 08 89 3c 24 48 89 4c 24 18 e8 7d e2 f7 ff 4c 8b 54 24 18 48 8b 54 24 10 41 89 c0 48 8b 74 24 08 8b 3c 24 b8 11 00 00 00 0f 05 <48> 3d 00 f0 ff ff 77 31 44 89 c7 48 89 04 24 e8 bd e2 f7 ff 48 8b
[883114.501858] RSP: 002b:00007fde416feaa0 EFLAGS: 00000293 ORIG_RAX: 0000000000000011
[883114.509142] RAX: ffffffffffffffda RBX: 00000000002cf224 RCX: 00007fe0b511278f
[883114.516220] RDX: 00000000002cf224 RSI: 00007fde38c88f00 RDI: 0000000000000014
[883114.523184] RBP: 00007fde38c88f00 R08: 0000000000000000 R09: 0000000000400000
[883114.530148] R10: 0000000000000004 R11: 0000000000000293 R12: 0000000000000004
[883114.537162] R13: 0000000000000014 R14: 0000000000000000 R15: 00000000002cf224
[883114.544125] </TASK>
[883114.547193] Modules linked in: netlink_diag rpcrdma rdma_cm iw_cm ib_cm ib_core nfsd nfs_acl xt_tcpudp rpcsec_gss_krb5 auth_rpcgss nfsv4 nfs lockd grace fscache netfs xt_conntrack nft_chain_nat xt_MASQUERADE nf_nat nf_conntrack_netlink nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xfrm_user xfrm_algo xt_addrtype nft_compat nf_tables libcrc32c nfnetlink br_netfilter bridge stp llc tls nvme_fabrics overlay sunrpc binfmt_misc intel_rapl_msr intel_rapl_common intel_uncore_frequency_common zfs(PO) zunicode(PO) isst_if_common zzstd(O) zlua(O) nfit zavl(PO) crct10dif_pclmul icp(PO) crc32_pclmul polyval_clmulni polyval_generic ghash_clmulni_intel zcommon(PO) nls_iso8859_1 sha512_ssse3 ppdev znvpair(PO) aesni_intel crypto_simd spl(O) cryptd rapl input_leds psmouse i2c_piix4 ena serio_raw parport_pc parport mac_hid dm_multipath scsi_dh_rdac scsi_dh_emc scsi_dh_alua sch_fq_codel msr drm efi_pstore ip_tables x_tables autofs4
[883114.602863] ---[ end trace 0000000000000000 ]---
[883114.606941] RIP: 0010:usercopy_abort+0x6e/0x80
[883114.611011] Code: 76 9a a8 50 48 c7 c2 42 53 95 a8 57 48 c7 c7 50 c7 96 a8 48 0f 44 d6 48 c7 c6 f3 c7 96 a8 4c 89 d1 49 0f 44 f3 e8 f2 07 d2 ff <0f> 0b 49 c7 c1 a0 58 99 a8 4c 89 cf 4d 89 c8 eb a9 90 90 90 90 90
[883114.624735] RSP: 0018:ffffbc3498033b00 EFLAGS: 00010246
[883114.629096] RAX: 000000000000005c RBX: 0000000000000001 RCX: 0000000000000000
[883114.636129] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
[883114.643193] RBP: ffffbc3498033b18 R08: 0000000000000000 R09: 0000000000000000
[883114.650197] R10: 0000000000000000 R11: 0000000000000000 R12: ffffbc3c94605104
[883114.657247] R13: 000000000003cefc R14: 000000000003cefc R15: 0000000000000000
[883114.664244] FS: 00007fde416ff640(0000) GS:ffff990af24c0000(0000) knlGS:0000000000000000
[883114.671730] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[883114.676214] CR2: 00007fde38c8c000 CR3: 00000004a5036005 CR4: 00000000007706e0
[883114.683232] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[883114.690268] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[883114.697324] PKRU: 55555554
```
opened 11:10PM - 05 Dec 23 UTC
Component: Memory Management
Type: Defect
### System information
Type | Version/Name
--- | ---
Distribution Name | Deb… ian
Distribution Version | Bookworm (12)
Kernel Version | 6.1.0-13-amd64
Architecture | x86_64
OpenZFS Version | zfs-2.1.14-1~bpo12+1
### Describe the problem you're observing
Since upgrading to Debian 12 a small system I run as rsync target and rsnapshot host went from a flat 50% RAM usage (out of 2GB total) to constantly OOM'ing even after an upgrade to 8GB. I initially raised the issue as question in https://github.com/openzfs/zfs/discussions/14986 but had too many variables in place to precisely pin the source of the issue (various external processes writing on it, some old zpools which used to have dedup enabled, a ton of snapshots, etc).
I've now managed to reproduce what I think is some sort of memory leak on a simple/vanilla setup, described below, by only using a single data source and rsnapshot. At this point though I'm at a loss and can't go any deeper - any help would be much appreciated.
Due to the (relative) simplicity of the setup I managed to replicate this on, I'm really surprised it's only me reporting.
### Describe how to reproduce the problem
1 - I have a sample dataset composed as follows on a remote host 100 GB size, 100k directories, 250k files
2 - The zpool (hosted on a 4 vCPU, 8GB RAM VM) is relatively simple (`zpool create -m /mnt/tank tank /dev/sda`) and the FS on top of it is `zfs create -o encryption=on -o keylocation=prompt -o keyformat=passphrase -o compression=on tank/secure` (note both compression and encryption are on)
3 - rsnapshot is configured to backup the remote (see "1") to `/mnt/tank/secure`
4 - The source is _never_ changed across iterations, so the rsync step of rsnapshot doesn't actually sync anything
5 - I run 10 iterations back to back, and see ARC filling up to its target 3/4GB size, as one would expect. Additionally, every iteration leaves about 600mb of "abandoned" used RAM
Here is what I'm left with:
```
total used free shared buff/cache available
Mem: 7951 7140 462 0 625 810
Swap: 0 0 0
Active / Total Objects (% used) : 13869528 / 15195981 (91.3%)
Active / Total Slabs (% used) : 629764 / 629764 (100.0%)
Active / Total Caches (% used) : 144 / 207 (69.6%)
Active / Total Size (% used) : 5961935.63K / 6291859.64K (94.8%)
Minimum / Average / Maximum Object : 0.01K / 0.41K / 16.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
1259468 1259468 100% 1.12K 44981 28 1439392K zfs_znode_cache
1262688 1262688 100% 0.97K 78918 16 1262688K dnode_t
1614144 1358737 84% 0.50K 100884 16 807072K kmalloc-512
43460 43460 100% 16.00K 21730 2 695360K zio_buf_comb_16384
1387428 1351895 97% 0.38K 66068 21 528544K dmu_buf_impl_t
2478084 2024503 81% 0.19K 118004 21 472016K dentry
39580 39580 100% 8.00K 9895 4 316640K kmalloc-8k
1259472 1259472 100% 0.24K 78717 16 314868K sa_cache
```
The same test, on the same system, with an ext4 over luks as destination works as intended and only results in 600mb of RAM used in total.
### Include any warning/errors/backtraces from the system logs
Nothing relevant I can spot.
opened 04:29PM - 11 Sep 23 UTC
Type: Feature
### Describe the feature would like to see added to OpenZFS
Add a non-fractio… nal configuration parameter which limits the memory used by the scrub command to some specified amount. Choose some reasonable default value for this amount.
Currently, memory is limited by the `zfs_scan_mem_lim_fact` and `zfs_scan_mem_lim_soft_fact` parameters. These default to 20, which corresponds to 100/20 = 5% of total system memory. For boxes with a lot of RAM, it might be desirable to add an additional limit expressed as a fixed amount of memory. This limit could be set to a few GB by default.
### How will this feature improve OpenZFS?
For a system with a very large amount of memory, allowing 5% to be used by scrubs may be excessive. The following monitoring graph shows slab usage during two scrubs conducted against a ~2TB zpool on a machine with 1TB RAM. (The y axis is in GB.)

During the first scrub, the default values of `zfs_scan_mem_lim_fact = 20` / `zfs_scan_mem_lim_soft_fact = 20` were used. These were then set to `100` and the box was rebooted before the second scrub was carried out.
Both scrubs completed in approximately the same amount of time, but the first scrub used a lot more memory.
### Additional context
The fact that ZFS scrubs can, by default, use up to 5% of system memory was discovered by the author when a scrub ran on a heavily loaded production database with 1TB RAM. The vast majority of RAM on this system is dedicated to postgres caches, and there is not 5% (50GB) of slab to spare. The scrub therefore caused the OOM killer to activate, and brought the system down. (Aside: by default, Ubuntu schedules scrubs for 0024 on the second Sunday of each month, so the production crash happened around at 0100 on a Sunday morning.) Examining the OOM killer logs showed a large value for `sio_cache_0`, which led to issue https://github.com/openzfs/zfs/issues/8662.
For me, the issue is now effectively managed by setting a larger value for `zfs_scan_mem_lim_fact` and `zfs_scan_mem_lim_soft_fact`, as the comments on the linked issue suggest. However, it might be nice for other ZFS users not to discover the same behaviour in the same way, especially since (at least on this system) the extra RAM used by the scrub does not actually appear to speed it up.
2 Likes
We haven’t concluded on the issue. When we have, we’ll work out short term guidance and a technical solution for longer term safety.
1 Like
Davvo
May 8, 2024, 6:44pm
65
Not on FreeBSD though, so… how old?
1 Like
Right, so, we are on the Tag labelled SCALE, lol.
Davvo
May 8, 2024, 6:56pm
67
Yeah, but BSD and Linux share common origins… hence my question about how exactly old your “in the old days” referred.
Davvo
May 8, 2024, 6:59pm
69
Linux being inspired by Unix and BSD being originally based on Unix means they somehow have a common origin.
Anyway, my question was a masked “how far back was this happening?”.
That was more to play into me mocking myself earlier. But to answer, I am speaking before Linux systems allowing filling the arc to max memory instead of 50%. I see these pop up in ZFS discussion groups. So, not very old. While they have a common origin, as you know, memory management and zfs not even close to the same.
To clarify, still ambiguous, for those using > 50% manually (but obviously too much).
2 Likes
Stux
May 9, 2024, 4:07am
71
I thought it might be nice to have a possible good news story… which is also an interesting data point…
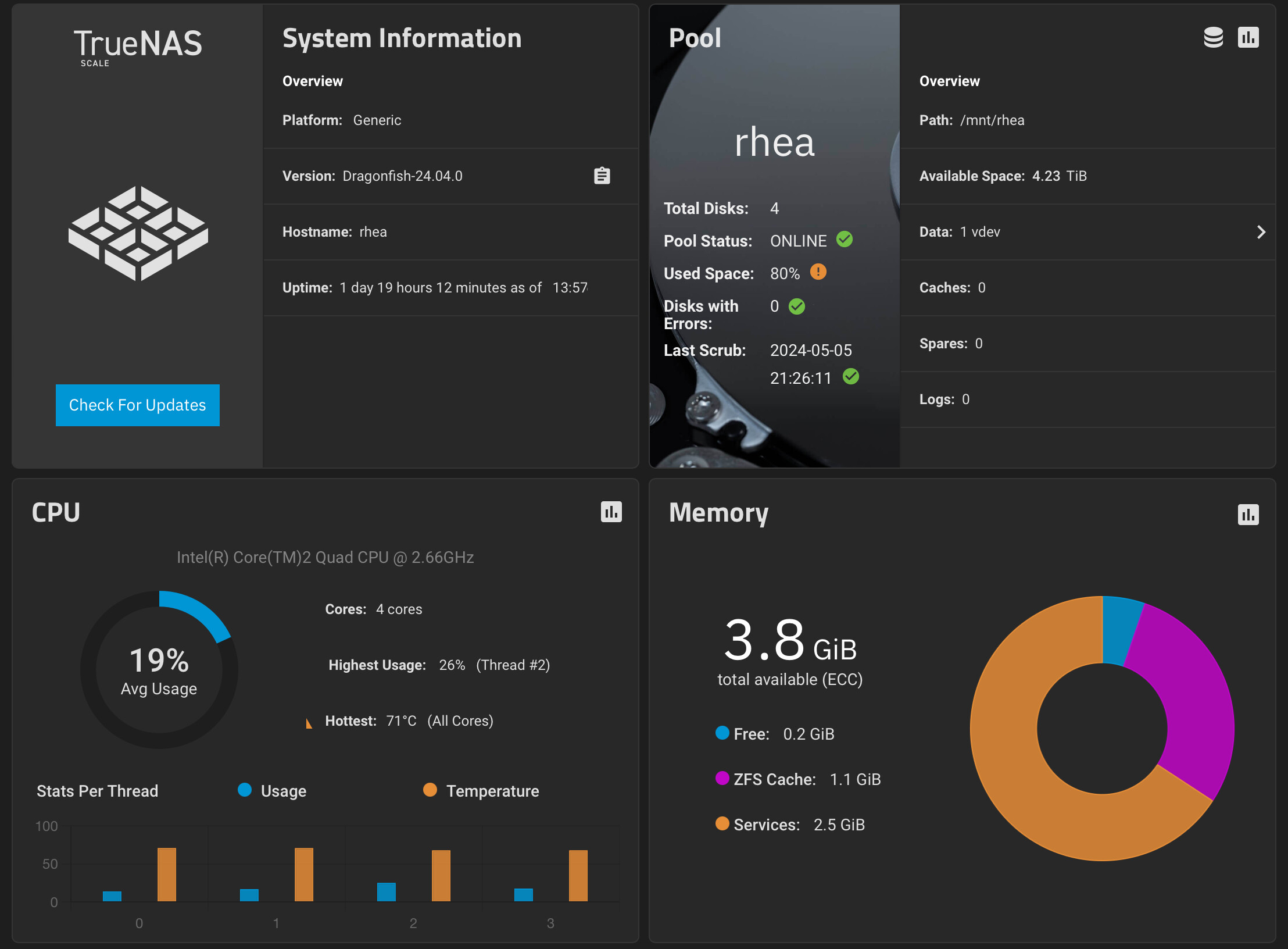
I have a very low end… very much below minimum specs backup server running TrueNAS Scale.
It’s an Intel Core 2 Quad with 4GB of RAM running off a pair of USB disks. Yes. I’m naughty, and don’t deserve any cookies.
Its been working well since upgrading to DragonFish 24.0.4 final.
Previously with Cobia you could see swap was always in use… after boot… but since upgrading to Dragonfish… 0 bytes. Heh.
Maybe its too early too say… hard to tell… since TrueNAS Scale only keeps 1 weeks worth of reporting (at least in Cobia)
Will keep an eye on this system… over time. It receives replications every hour.
The curious thing is that I do not have SMB or NFS services active on this system, only SMART and SSH.
It’s a replication target, that is all.
2 Likes
That’s really weird! I presume it’s a backup target system? Maybe you don’t have enough arc to cause the issue, what does the arc reporting look like?
I’m putting in Prometheus to capture data so I can keep what I want. Even with IX expanding the retention supposedly, I want more useful info like VM resources, Kubernetes app resources, etc.
Stux
May 9, 2024, 4:55am
73
yes, its a backup target.
ARC is still growing… we shall see
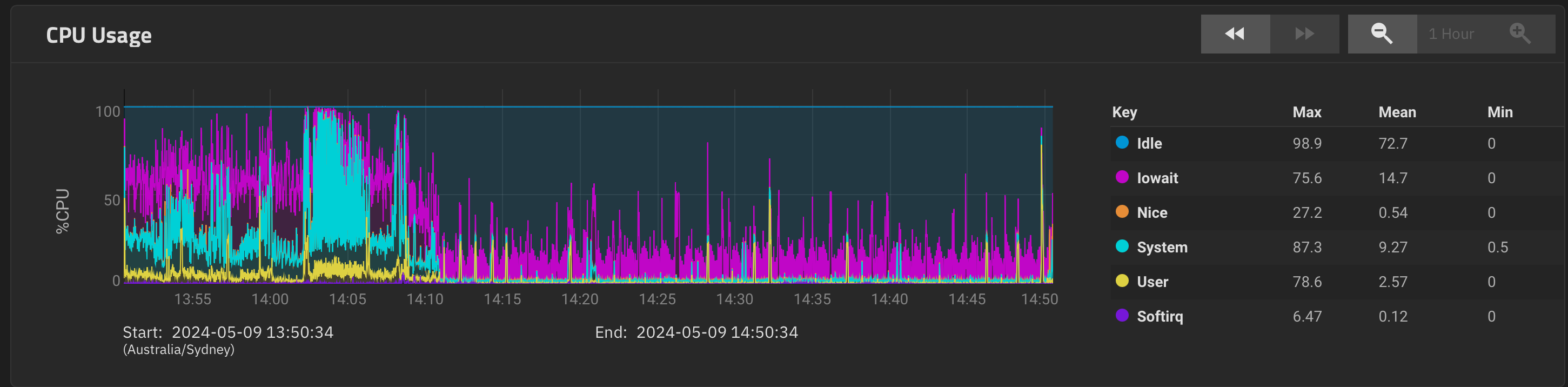
The 1 hour CPU chart to show it does experience some load
Impressive it survived the backup, assuming that’s what I see. So, the solution to the problem isn’t more memory, it’s less!
I have a 3GB backup ZFS target, but, it’s not Scale, just Debian.
2 Likes
Stux
May 9, 2024, 6:17am
75
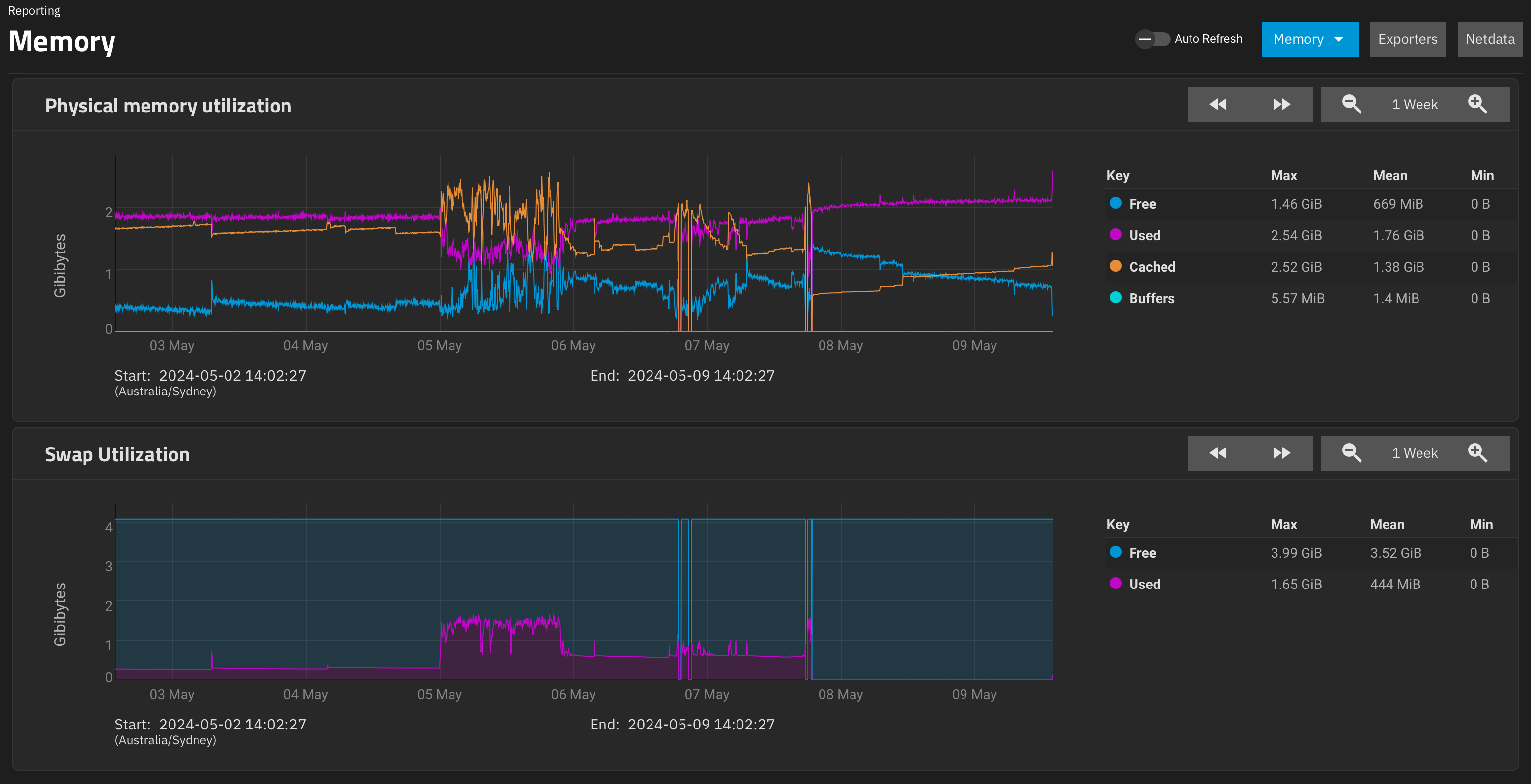
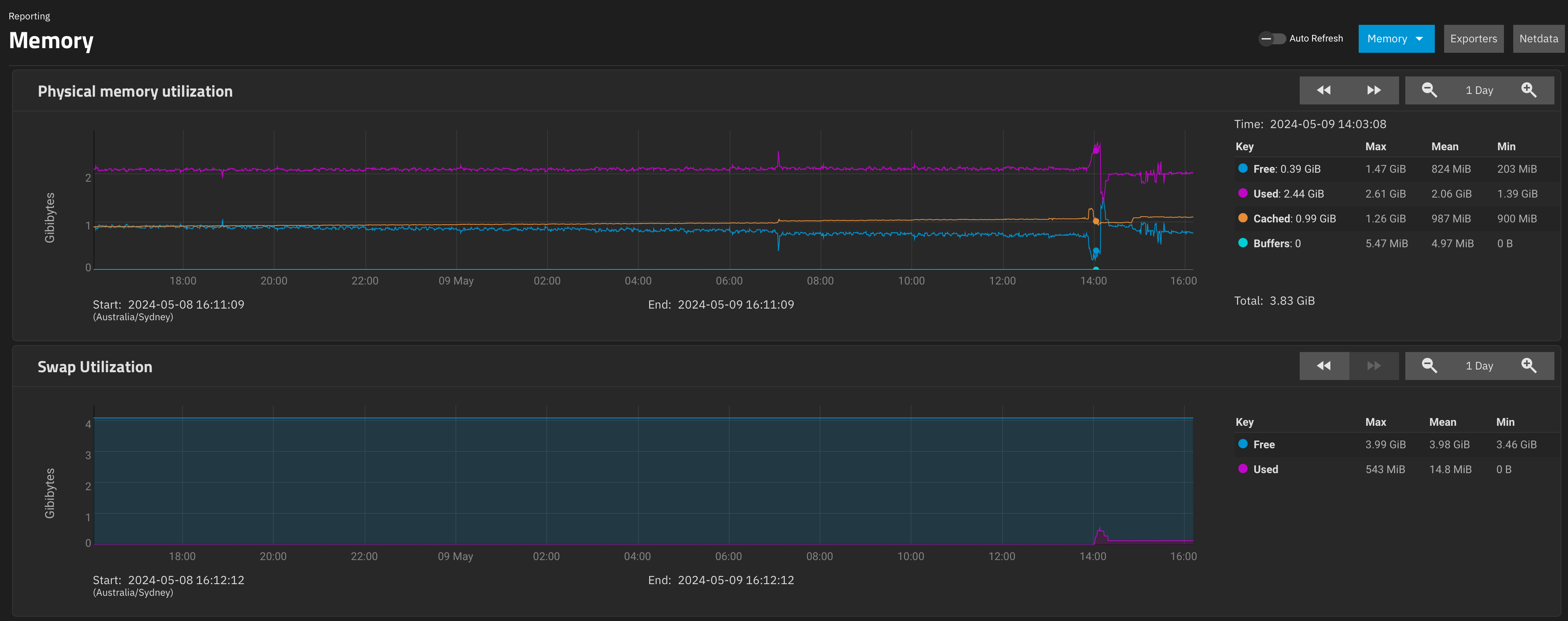
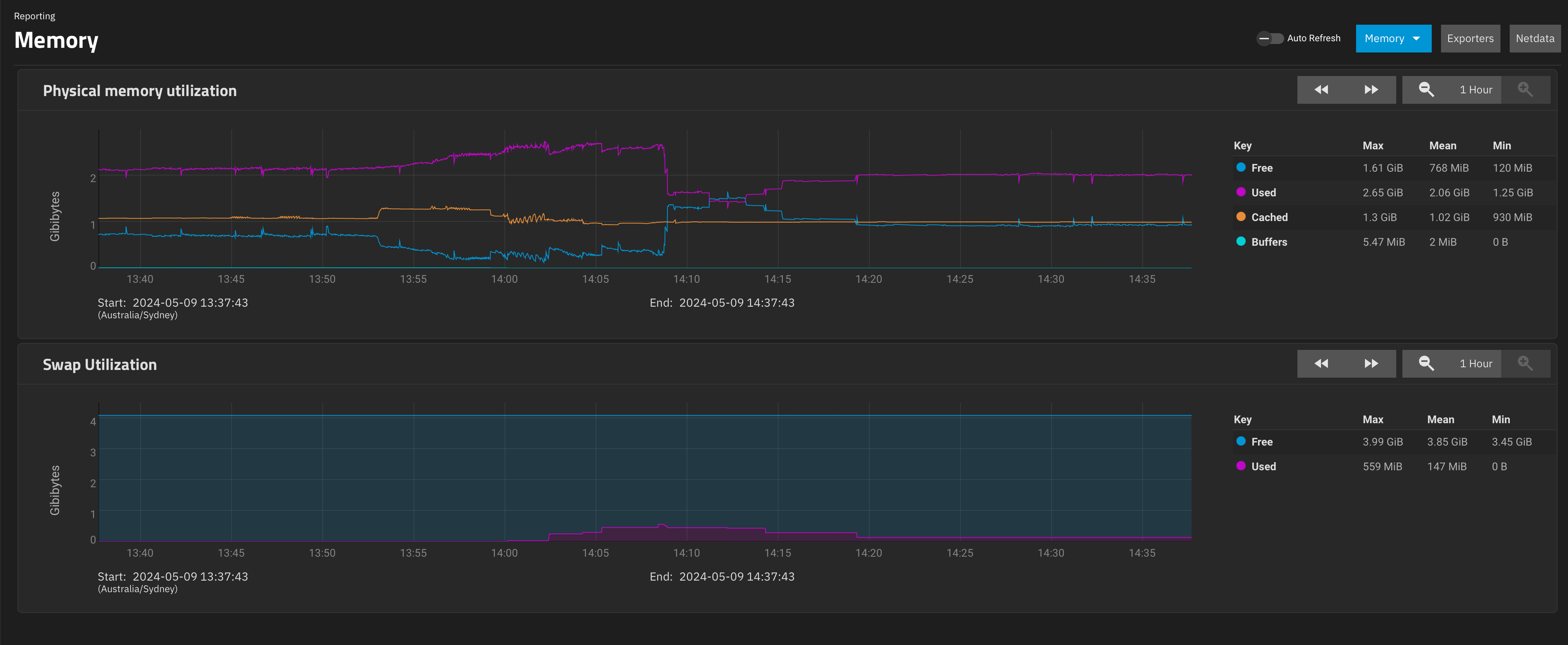
So, I went into the UI of this backup system, and I started interrogating snapshots etc, sorting them, deleted a bunch of snapshots for the .system dataset that I’d taken accidentally, etc.
This triggered a bit of swap. Looking out at 1day view, it peaks at 543MB then drops to 130MB.
What I think is interesting is what the memory usage looked like when this happened. ARC didn’t really recede much, forcing “used” to get paged out as “free” dropped.
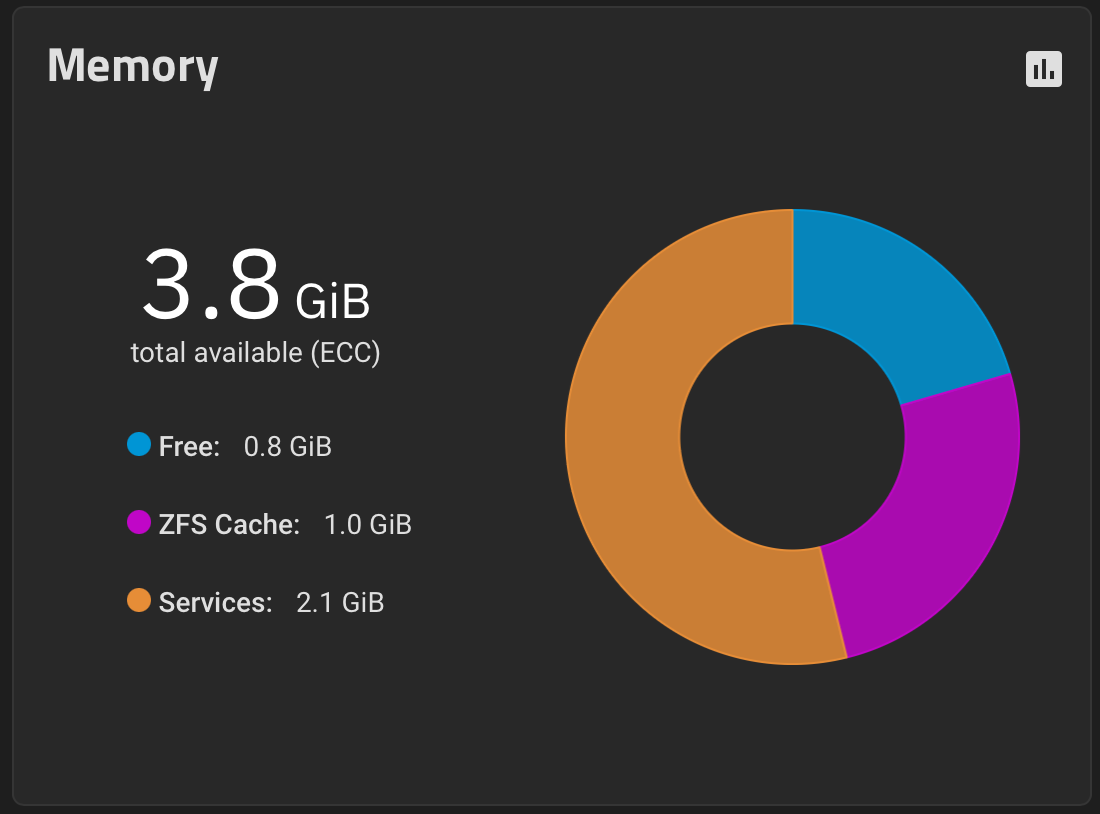
And zoom in on peak and after peak
“Cached” appears to be ARC, according to the dashboard numbers
It looks to me like it prefers to swap out than to lower cache. or the swapping occurs faster than the cache drops.
Don’t get me wrong, as it is, I don’t really care, the system was working fine, but if the issue is that cache is forcing swap to be used as the memory is full and the cache is not making way…
1 Like
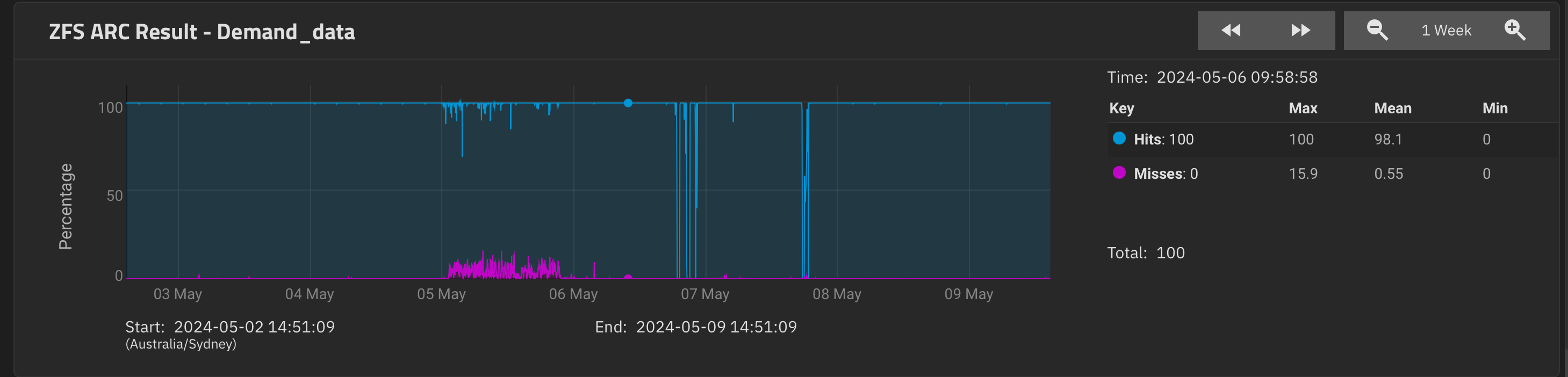
Stux
May 9, 2024, 6:39am
76
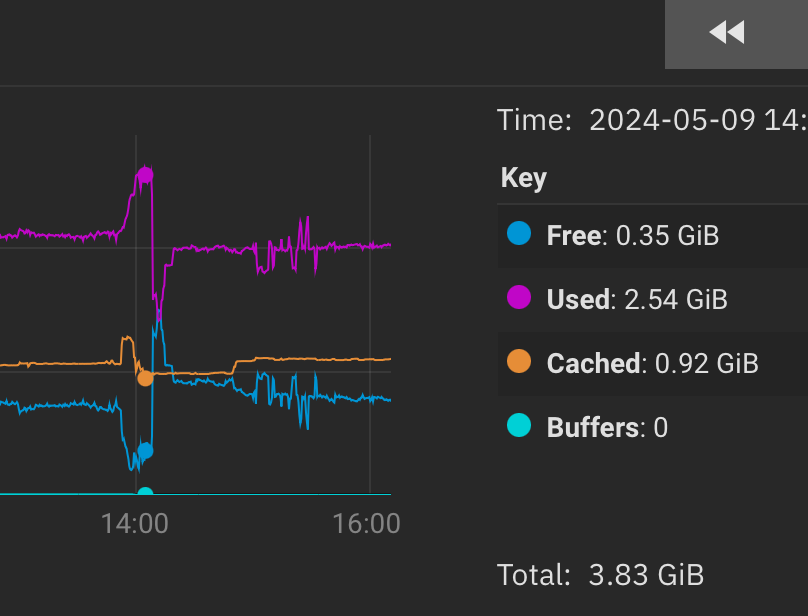
at 1hr zoom, going back to the event…
Cached didn’t really budge… did it
Stux
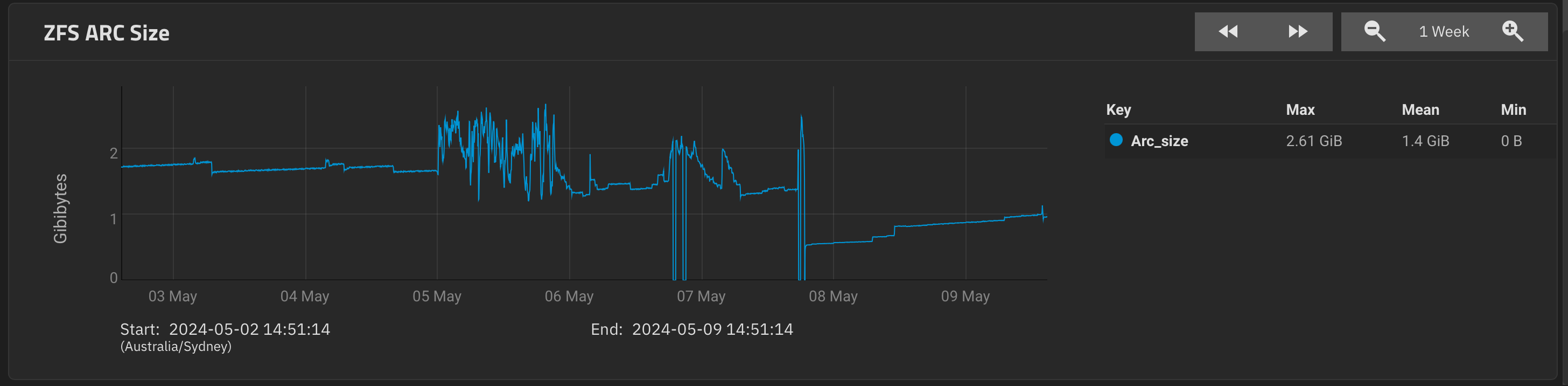
May 9, 2024, 6:50am
77
ARC size (current): 34.5 % 999.4 MiB
Target size (adaptive): 36.9 % 1.0 GiB
Min size (hard limit): 4.2 % 122.6 MiB
Max size (high water): 23:1 2.8 GiB
Anonymous data size: < 0.1 % 132.5 KiB
Anonymous metadata size: 0.1 % 796.5 KiB
MFU data target: 37.7 % 346.6 MiB
MFU data size: 30.8 % 283.3 MiB
MFU ghost data size: 59.0 MiB
MFU metadata target: 14.1 % 129.7 MiB
MFU metadata size: 13.6 % 125.5 MiB
MFU ghost metadata size: 146.8 MiB
MRU data target: 36.0 % 331.2 MiB
MRU data size: 9.8 % 90.5 MiB
MRU ghost data size: 54.5 MiB
MRU metadata target: 12.2 % 112.2 MiB
MRU metadata size: 45.6 % 419.5 MiB
MRU ghost metadata size: 199.7 MiB
Uncached data size: 0.0 % 0 Bytes
Uncached metadata size: 0.0 % 0 Bytes
Bonus size: 0.5 % 4.9 MiB
Dnode cache target: 10.0 % 289.9 MiB
Dnode cache size: 12.1 % 35.0 MiB
Dbuf size: 0.8 % 7.9 MiB
Header size: 1.8 % 17.9 MiB
L2 header size: 0.0 % 0 Bytes
ABD chunk waste size: 1.4 % 14.0 MiB
Where does the “Target size (adaptive): 36.9 % 1.0 GiB” come from? 25% of RAM? A hard floor?
It’s a game of juggling, constantly changing based on total RAM, free memory, non-ARC memory, ARC data/metadata requests, etc, to provide the best balance of efficiency (reading from RAM rather than the physical storage of the pool itself) vs. flexibility (enough slack for system services, processes, and other non-ARC memory needs.)
That target size can fluctuate anywhere between the min/max allowable values. ZFS is usually pretty good at actually storing in the ARC the amount of data defined by its target size. (As seen in your example.)
Another way to think of the target size: “If this is the general state of my system, then ZFS will aim and work for an ARC to be this stay that way .” Meaning that you’ll have more data/metadata evictions the smaller the target size is, and fewer evictions the larger the target size is. You can think of it as a “separate RAM stick with a defined capacity”. Of course, this imaginary “RAM stick” can also dynamically adjust based on many variables.
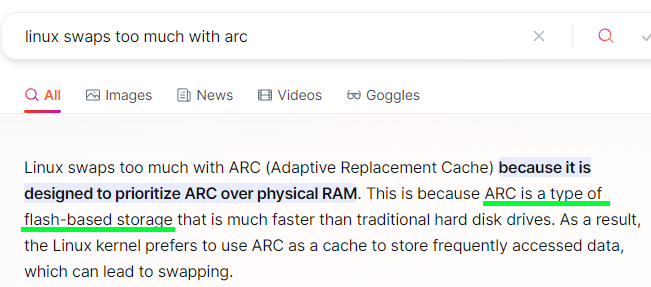
I figured it out, thanks to the power of A.I.!
Why does TrueNAS SCALE use flash-based storage to hold the ZFS cache?! Are you kidding me? You’re supposed to keep the ARC in RAM . Now everything makes sense.
A.I. saves the day, once again!
3 Likes
FYI.
TrueNAS Engineering team is making progress on this issue and is testing some scenarios.
We expect to be able to recommend best mitigation and plans for a fix, on Friday.
5 Likes