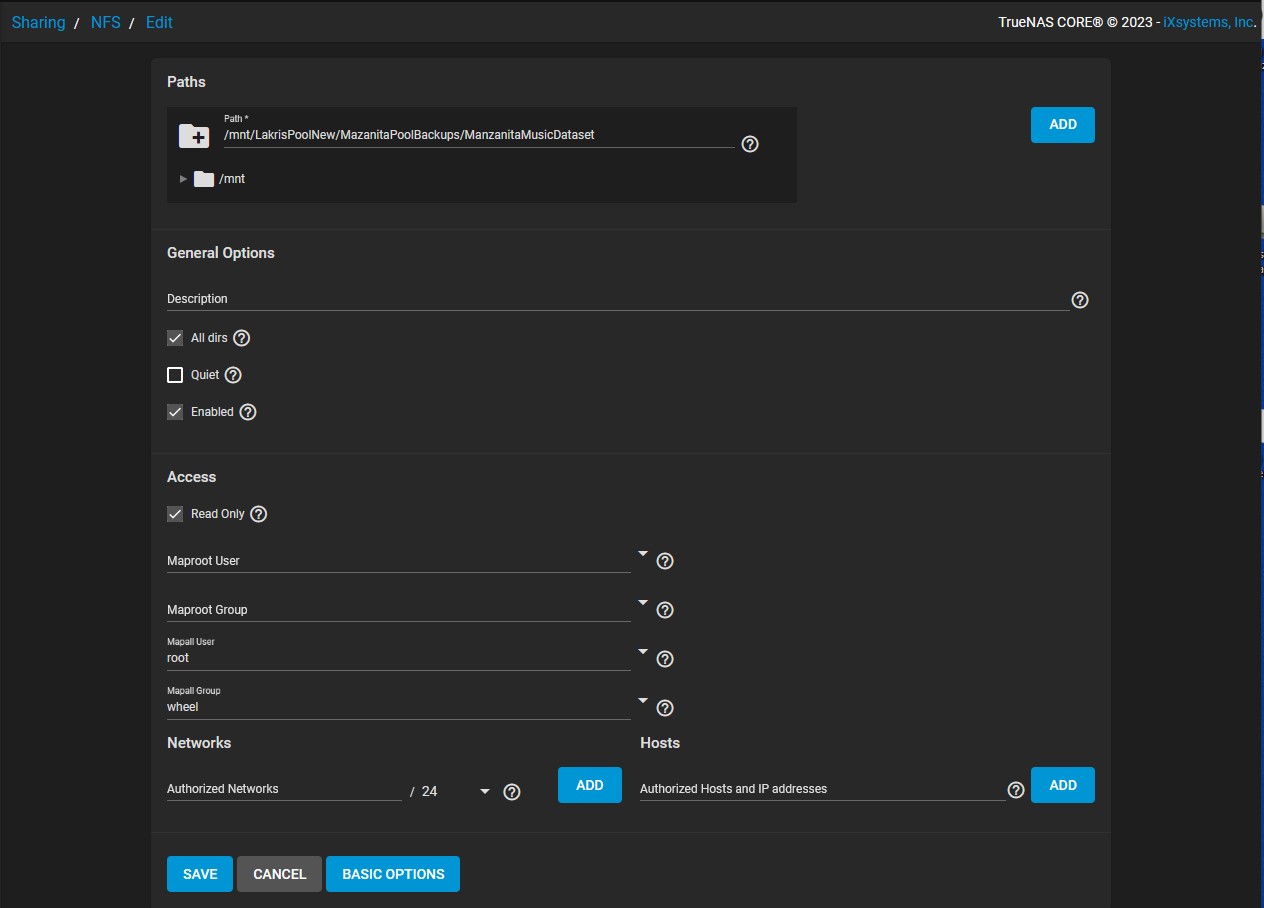
I have a TrueNAS box at the end of a replication chain that shares a read-only NFS mount of a read-only replicated filesystem. I share this directory to a Raspberry Pi running Rasbian, and for a while it works.
Then, minutes or hours later, possibly after a replication with new data (but I’m far from sure), the share drops off and stops working. I can detect the failure from Rasbian, but I can’t successfully remount so far without rebooting the TrueNAS box offering the share.
Flare is our Raspbian box. Here it is working:
root@flare:/mnt# ls -alg
total 24
drwxr-xr-x 4 root 4096 May 19 14:09 .
drwxr-xr-x 18 root 4096 Mar 15 07:12 …
drwxrwxrwx 2 root 4096 Apr 14 05:30 LocalPlaylists
drwxrwxr-x 10 root 12 May 18 09:54 ManzanitaMusic
root@flare:/mnt#
And here it is once it stops working:
root@flare:/mnt# ls -alg
ls: cannot access ‘ManzanitaMusic’: Input/output error
total 12
drwxr-xr-x 4 root 4096 May 19 14:09 .
drwxr-xr-x 18 root 4096 Mar 15 07:12 …
drwxrwxrwx 2 root 4096 Apr 14 05:30 LocalPlaylists
d??? ? ? ? ? ManzanitaMusic
root@flare:/mnt# cd ManzanitaMusic
bash: cd: ManzanitaMusic: Input/output error
Here’s the relevant part of /etc/fstab on Flare (Raspbian client):
192.168.0.111:/mnt/LakrisPoolNew/MazanitaPoolBackups/ManzanitaMusicDataset /mnt/ManzanitaMusic nfs defaults,retry=60 0 0
I run the following script at regular intervals on Flare because the TrueNAS server takes longer to boot than the Raspberry Pi, and so after a power failure the share may not initially not be available. This corrects for that:
root@flare:~# cat ./MountLakrisMusicIfNeeded.sh
if mountpoint -q /mnt/ManzanitaMusic ; then
echo ManzanitaMusic was already mounted
else
echo ManzanitaMusic not yet mounted, mounting…
mount /mnt/ManzanitaMusic
fi
root@flare:~#
Here’s the script in action when we are mounted properly:
root@flare:/mnt# /root/MountLakrisMusicIfNeeded.sh
ManzanitaMusic was already mounted
root@flare:/mnt# umount /mnt/ManzanitaMusic/
root@flare:/mnt# umount /mnt/ManzanitaMusic/
umount: /mnt/ManzanitaMusic/: not mounted.
root@flare:/mnt#
root@flare:/mnt# /root/MountLakrisMusicIfNeeded.sh
ManzanitaMusic not yet mounted, mounting…
root@flare:/mnt# /root/MountLakrisMusicIfNeeded.sh
ManzanitaMusic was already mounted
root@flare:/mnt#
root@flare:/mnt# ls -alg
total 24
drwxr-xr-x 4 root 4096 May 19 14:09 .
drwxr-xr-x 18 root 4096 Mar 15 07:12 …
drwxrwxrwx 2 root 4096 Apr 14 05:30 LocalPlaylists
drwxrwxr-x 10 root 12 May 18 09:54 ManzanitaMusic
root@flare:/mnt#
And here’s what it looks like once the share has fallen off. We can’t repair the issue from the client side, as you can see it doesn’t work:
root@flare:~# ./MountLakrisMusicIfNeeded.sh
ManzanitaMusic not yet mounted, mounting…
mount.nfs: mount system call failed
root@flare:~# umount /mnt/ManzanitaMusic
root@flare:~# umount /mnt/ManzanitaMusic
umount: /mnt/ManzanitaMusic: not mounted.
root@flare:~# ./MountLakrisMusicIfNeeded.sh
ManzanitaMusic not yet mounted, mounting…
mount.nfs: access denied by server while mounting 192.168.0.111:/mnt/LakrisPoolNew/MazanitaPoolBackups/ManzanitaMusicDataset
root@flare:~#
So, what does the TrueNAS server (Lakris) have to say about this?
I see two errors:
1:
console.log:May 17 20:00:17 lakris 1 2024-05-17T20:00:17.798983-07:00 lakris.doodle.local mountd 1264 - - can’t change attributes for /mnt/LakrisPoolNew/MazanitaPoolBackups/ManzanitaMusicDataset: MNT_DEFEXPORTED already set for mount 0xfffffe00dd4c2040
2:
daemon.log:May 19 14:46:55 lakris 1 2024-05-19T14:46:55.088950-07:00 lakris.doodle.local mountd 1291 - - mount request denied from 192.168.0.112 for /mnt/LakrisPoolNew/MazanitaPoolBackups/ManzanitaMusicDataset
I am making changes to the original filesystem this is a read-only replication of, and so snapshots are likely arriving and are my best guess as to what’s going wrong here. But I’m far from sure, and would welcome any suggestions.