From the docs, I see I can use CLI “system reporting config” to configure how long the reports are supposed to be retained, but in my system the command doesn’t seem to exist? I can only use the clear command
I reported this at NAS-128053 but ixSystems were pretty naff about it (because I mischaracterised the issue in the original ticket and I couldn’t edit it. Despite showing these exact systems in my screen shots, and despite explaining why I these mismatched the original title/description, they decided to close this ticket as “working as designed”.
Unfortunately I haven’t yet got around to relogging it as a new issue with a more accurate title - but I have this EXACT same problem.
To be fair, we did close the bug ticket and create the linked ticket to investigate a new feature for that to be set by the user. The trick is that data stored grows a lot, especially as you scale up with more drives. (Remember, we support 1200+) so we’ll probably end up with something that shows you how much disk is being consumed as well so we don’t end up with posts asking why 20GB of space is being consumed and the chart loads are now “slow”
Both are not sufficient in my opinion, and in Core it went much further back.
If it is 1 week only, is there a way to configure it?
I’d be happy with a couple of months… or whatever… but if it is a fixed span, I’d suggest that if the default is 1 week, that is too short, and if someone really is concerned with the space being used for the logs then they can shorten it.
As I said, Core had it going waaaaaay back, and I never even noticed it… not saying Scales metrics are comparable, maybe they’re far more voluminous
I agree that the user should be able to curtail the length, if necessary. But the default should be closer to a month to allow a timeline comparison re: impacts of snapshots, long SMART tests, and other recurring tasks that may have an impact on system stability / heat / power consumption / whatever. A week is way too short to show those kinds of issues.
In CORE you have an option in System>Reporting to edit the graph time showed in months (up to 60 months according to the ? widget); additionally, although as far as I know it’s not related, if you change that value or a few others the graph will break and you will only see the new data.
To be fair, I explained in detail why there was an issue, and I gave screen shots, but ixSystems decided to stick to the original title and description and ignore the extra details I provided, and cherry pick a feature request instead that I had explicitly said was NOT the issue and was not something I felt I needed.
A week’s worth of data is simply insufficient to be able to establish trends or to diagnose e.g. an intermittent heat related issue when the overheating was (say) 1.5 weeks ago.
As I said in that ticket, I fully understand the issue of log data growth, and the need to manage it actively and not let it grow excessively, but this is NOT the correct solution for home users like me with 6 drives, or enterprise users with 100s of drives or indeed anyone inbetween.
With the benefit of hindsight, it appears to me that the new reporting technology was not production ready for inclusion in Cobia. And ixSystems does not appear to be getting on top of the shortcomings of this new solution either, nor trying to understand how the reporting functionality is used to diagnose and / or prevent issues.
But readers can judge for themselves what happened by reading NAS-128053.
See also NAS-127387 for another example of a poor response and NAS-127524 for an example of a truly excellent response that went way way way beyond what a free users such as myself could possibly expect from support.
Agreed. Most of our enterprise folks that need serious data / logging retention do this off-box by exporting to external server to keep months or even years of performance data. But 7 days for home labs is clearly not enough. We’ll see if we can adjust soon.
FYI - For those curious readers, netdata stores a LOT more data than legacy collectd did. It can get heavy very quick. They have an article explaining how to calculate this out here:
The tricky part for us will be defining the tiers, how long to retain, and if the defaults need to be scaled up/down based on system configuration, I.E. number of drives, network interfaces, etc.
You could also look into compressing “older” data by eliminating the normal noise and instead focusing on major deviations for closer capture. I took that approach when it came to compressing data in a data logger application I wrote a long time ago. i.e. the usual noise of less than 1*C deserves no further review / storage and is averaged over long periods of time to minimize storage. On the other hand, events where there were major deviations were captured and kept in high-fidelity.
On a monthly basis, that’s how the data would present even if you stored it in high-fidelity. You could even give the user some input into this by allowing them to set the thresholds.
Yep, all things are possible, but will take some work either way. I think you’ll see this get tuned and adjusted in the near future, hopefully with some user controls that let folks set their own preferred methods of compressing data, reverting to low-fidelity as time passes, etc. Ticket will be updated as we go.
So if I may summarise this (as a retired IT project and programme manager of 30+ years)…
Retaining only 7 days data is indeed by intent.
This change (from 6 months data stored in Bluefin) to 7 days stored in Cobia was made without consultation with different user groups and without notifying users in the change log. Only now after the above mentioned ticket, is ixSystems starting to consider user requirements.
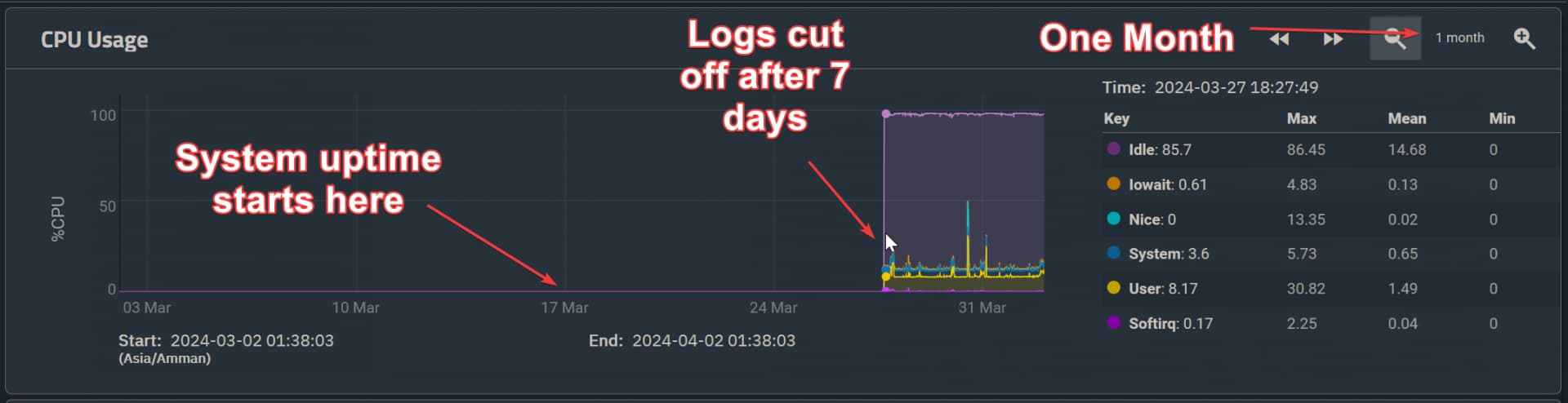
The Reporting graphs can still zoom out to 6 months, even though 7 days is the maximum that will be shown. The decision to reduce data stored to 7 days was not accompanied by a matching decision only to allow zooming out to 7 days.
Netdata already has the facilities to retain e.g. 6 months data without it growing so large by e.g. summarising data between 7 and 28 days old to (say) 15 minutes, and summarising data between 29 and 180 days old to (say) hourly data - but this wasn’t investigated or included in scope and implemented as part of its implementation of Netdata in Cobia despite being simple configuration rather than complex code development.
The choice of tiers and retention periods could, for example, have been made in such a way that 6 months data collected was approximately the same volume of data as in Bluefin.
Or functionality could have been implemented to truncate the history based on absolute space used or % of pool capacity used or % of pool capacity remaining rather than a simple 7 days.
If implementation timescales had been tight, then given that old history was lost when migrating from Bluefin to Cobia and new history was being stored from scratch, it would also have been possible to ship Cobia without this summarisation with a commitment to add it in (say) 23.10.2 in March without the data collected inbetween growing too large.
I’m super surprised that this seem to be a default behavior that was implemented without warning or announcement to end users.
I’m sure the fine people of iXsystem have their reasons to do the implementation like this, and it do seem we have a fix coming soon in version SCALE-25, but this is the kind of stuff that if it effects a large number of users, it could cause lose in trust.
For the sake of being open and transparent with the community, it would have been better that this was communicated before the implementation was applied, I would have been totally fine to reduce the logs to 7 days by default and then give us the option to increase it again, but doing the chance without giving users the option to do anything… well… not good
I am absolutely certain that the reasons that ixSystems decided to switch to Netdata were genuinely excellent ones, and I am confident that as a long-term decision that was a good one.
I genuinely wish I could say the same about the Netdata implementation, but I can’t. But in the real world not all implementations go well however much we wish they would.
Equally, the way that tickets are handled by support staff would ideally be respectful, but support staff are human.
But this is all water under the bridge - without a time-turner we cannot go back and redo history. But what we can do is try not to repeat the same mistakes in the future, and so what I hope happens is that:
Lessons are learned about asking what various types of users see as requirements (rather than making assumptions) and that plans and changes of functionality are communicated better. (For example, I am pretty certain that you will get better beta user feedback if the beta users know what has changed so that they can review it.)
Support staff are helped not to be dismissive or to trivialise or to cherry pick the reports made by home users. This does not mean that home users should get any greater priority for fixes than currently - the paying enterprise customers are the people who pay for the salaries and who keep the lights on - just that the benefits that home users bring to highlighting issues should be recognised and valued.
100% I have gotten excellent hardware support from iXsystems for my MiniXL and I am very grateful for it. I was less impressed with my Jira experience, which included a suggestion ticket being made private, thus preventing other users from being able to vote on it.
That would mean another piece of software for a functionality that is considered pretty basic and has always been in TN. Considering the proper way of spinning up TC is on another machine, this is likely not a solution for plenty of non-enterprise users.
Only 7 days worth of data logging is underwhelming coming from up to 60 months-long graphs.
Just to recap, ticket is in, we will look at how to address this in a future update. Ideally so you have some knobs to adjust up/down the retention rates or density.
Cobia reduced the report storage from 6 months (though someone above suggested 60) to 7 days without asking anyone whether this was a good idea or telling anyone that they had done it, and because no one knew anything about it and Beta testing tends to be a short-sharp activity, no one picked up that this change had happened.
Now that I raised a ticket, ixSystems are committing only to looking at how to address this at some future point i.e. no commitment to actually address it, and no indication whatsoever when it will be released. We don’t have any acknowledgement that ixSystems made a mistake with this - and that means that this 2nd attempt at delivering usable reporting is likely to get far lower priority than if there was an acceptance that they made a mistake.
And judging by the way decisions have been taken so far, and the quality of the reporting functionality in Cobia, just how confident can we be that what will be delivered “in a future update” will be what the various user groups want and of sound quality, and how confident can we be that it will be delivered in a reasonable time-scale?
Perhaps the short-term solution is to take the Netdata functionality out and put the old functionality back in, as presumably this could be done relatively quickly. Then users would have a useable and working reporting functionality, and ixSystems could take as long as they needed to redo the Netdata functionality and get it right for all the various user groups.
EDIT: I decided to edit this comment in order to note that the functionality for better Netdata support was actually committed to Github by ixSystems only a few days after I posted this comment. So, ixSystems DID give this some priority.
I can understand the frustrations from such a situation and therefore why you think that this view is a reasonable one, however let me play Devil’s Advocate for a minute or two…
Handling error workflows in the GUI is one to two orders or magnitude more complex than handling the normal workflow - because the number of possible errors and combinations of those errors is large, and you would not want to automate any fix for these issues without being 100% certain that the fix will make things better and not worse. IMO this makes providing GUI solutions to fix errors both unaffordable and unworkable. And can you imagine the outcry (and potentially the law suits) when the automated fix gets it wrong and turns an offline but recoverable set of data into a completely unrecoverable set of data?
However I do agree that the GUI would benefit from better reporting of errors and diagnostics, and that this limited additional functionality would have a more limited implementation cost.
But, being hard nosed about it, in the end the fix itself will require manual CLI actions by someone who has a reasonable idea of what they are doing and who understands what the implications and impact will be. If you have such a person working on the fix, then it is completely reasonable to assume that they will also have the expertise to diagnose the issue using the CLI too, in which case why bother with diagnosis GUI functionality.
When resources for developing GUI functionality are finite, and you therefore need to choose between providing better diagnosis functionality or using the same resources to provide completely new functionality, then I think it is a completely reasonable position to prioritise the new functionality and leave diagnostics to being performed using the CLI.