Hello,
I have a pool of 12 HDs of various storage capacity, ZFS reports some HDs as degraded, but currently none of these have read, write or checksum errors.
I would not like to replace 5 HDs apparently without errors, I tried to change controllers but without success.
Is it possible to “reset” the status?
Attached is the pool status.
Using the “-xv” option I get the affected files, if I delete them can I “recover” the pool status?
Thanks
truenas_admin@lp-truenas-ge[~]$ sudo zpool status -v
[sudo] password for truenas_admin:
pool: HD8
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: Message ID: ZFS-8000-8A — OpenZFS documentation
scan: scrub paused since Sun Nov 3 13:57:56 2024
scrub started on Sun Nov 3 08:18:09 2024
0B / 52.7T scanned, 0B / 52.7T issued
0B repaired, 0.00% done
remove: Removal of /dev/disk/by-partuuid/1f0c5b1d-05a8-4a3b-b44b-bb87774bddb2 canceled on Thu Oct 31 11:59:52 2024
config:
NAME STATE READ WRITE CKSUM
HD8 DEGRADED 0 0 0
58393e90-f55e-4781-9d42-438e189d5297 DEGRADED 0 0 0 too many errors
93ba1c8b-7665-4001-87c2-e8956352d3a2 ONLINE 0 0 0
a66b0299-7679-4547-89bb-cc41f717d5d4 ONLINE 0 0 0
b65b6595-e676-45c5-b0ed-e238186029ee ONLINE 0 0 0
ea333c0c-45f5-4844-9059-269265d23197 ONLINE 0 0 0
a9de848e-53e2-4da8-97e7-0eb5efd4ca9e DEGRADED 0 0 0 too many errors
971229d2-a7be-4624-bc93-5e95b7f388b8 DEGRADED 0 0 0 too many errors
02ba4089-43fe-4019-ba0e-fdfc440bbff9 DEGRADED 0 0 0 too many errors
3d8aee2e-5e2d-4bcc-ba19-6605d188a887 ONLINE 0 0 0
623a217e-25e3-4553-b44e-d20c87720740 ONLINE 0 0 0
c4b394cc-0c65-48cb-be5f-8aafa1455fba DEGRADED 0 0 0 too many errors
1f0c5b1d-05a8-4a3b-b44b-bb87774bddb2 ONLINE 0 0 0
You only provided part of the entire printout, why? The other parts matter as well especially for the error message you have.
The zpool clear will likely not clear the error as these are different from Read/Write/Cksum errors. This error message is telling you that you are missing too much data in those drives.
Run zpool scrub HD8 and let it finish. Then run zpool status -v HD8 and report the entire output of the command. You can also check the status of the scrub with that same second command.
Also, are you running a STRIPE of all those drives?
Thanks,
i perform this, now error on HD are clear but i have the message “Pool is not healty”
All HD are without error.
The controller is bare metal, it can manage 16 HD SATA
Hello, thanks
This is the command :
sudo zpool status -v
truenas_admin@lp-truenas-ge[~]$ sudo zpool status -v
[sudo] password for truenas_admin:
pool: HD8
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: scrub paused since Sun Nov 3 13:57:56 2024
scrub started on Sun Nov 3 08:18:09 2024
0B / 52.7T scanned, 0B / 52.7T issued
0B repaired, 0.00% done
remove: Removal of /dev/disk/by-partuuid/1f0c5b1d-05a8-4a3b-b44b-bb87774bddb2 canceled on Thu Oct 31 11:59:52 2024
config:
NAME STATE READ WRITE CKSUM
HD8 DEGRADED 0 0 0
58393e90-f55e-4781-9d42-438e189d5297 DEGRADED 0 0 0 too many errors
93ba1c8b-7665-4001-87c2-e8956352d3a2 ONLINE 0 0 0
a66b0299-7679-4547-89bb-cc41f717d5d4 ONLINE 0 0 0
b65b6595-e676-45c5-b0ed-e238186029ee ONLINE 0 0 0
ea333c0c-45f5-4844-9059-269265d23197 ONLINE 0 0 0
a9de848e-53e2-4da8-97e7-0eb5efd4ca9e DEGRADED 0 0 0 too many errors
971229d2-a7be-4624-bc93-5e95b7f388b8 DEGRADED 0 0 0 too many errors
02ba4089-43fe-4019-ba0e-fdfc440bbff9 DEGRADED 0 0 0 too many errors
3d8aee2e-5e2d-4bcc-ba19-6605d188a887 ONLINE 0 0 0
623a217e-25e3-4553-b44e-d20c87720740 ONLINE 0 0 0
c4b394cc-0c65-48cb-be5f-8aafa1455fba DEGRADED 0 0 0 too many errors
1f0c5b1d-05a8-4a3b-b44b-bb87774bddb2 ONLINE 0 0 0
For scrubbing HD8, the system run for about 56 hours (!!!), so i try next time …
All drive are stripes non RAID / redundance
Please use the code tags “</>” to insert any screen captures into. I change the format to make it look correct. That is what was confusing me before.
Since the last scrub said no bytes repaired, you can give the zpool clear HD8 a try. The problem with no redundancy is one drive goes bad, the entire thing is gone.
In the meantime you can run a SMART Long self-test on all of the drives. The command is smartctl -t long /dev/sda for example. I’m making an assumption that you are using SCALE. Do this command for all your drives. The smaller drives should finish faster than the larger drives. What you want to do is when you issue the command, you will get a message to wait XXX minutes for the test to complete. After that time has passed then run smartctl -a /dev/sda and you should be looking for Test Description Status and you want to see the Extended Test Completed without error. If there is a failure, that is not good as your drive is failing.
Hello,
i perform a scrubbing now, from yesterday night and for about 50 hours
Some disk have error (one have at now (5%) 156 error)
At the end i rewrite here the result
Thanks very much !
Since you have a STRIPE (highly advised against), I would caution you to backup whatever data you have before complete failure. If one drive drops out, your data is for the most part gone. You may be able to recover some of it but that is a process for the folks who really need that data back. Not something I would ever want to try.
Posting your hardware would be a good idea, it has been asked for before and allows us to help you better vice making assumptions.
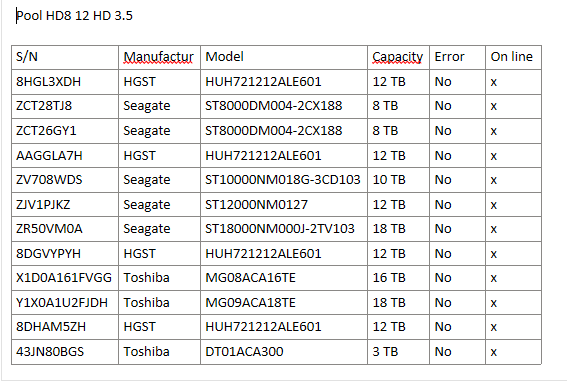
S/N Model Capacity Error On line
8HGL3XDH HGST 12 TB No x
ZCT28TJ8 Seagate 8 TB No x
ZCT26GY1 Seagate 8 TB No x
AAGGLA7H HGST 12 TB No x
ZV708WDS Seagate 10 TB No x
ZJV1PJKZ Seagate 12 TB No x
ZR50VM0A Seagate 18 TB No x
8DGVYPYH HGST 12 TB No x
X1D0A161FVGG Toshiba 16 TB No x
Y1X0A1U2FJDH Toshiba 16 TB No x
8DHAM5ZH HGST 12 TB No x
43JN80BGS Toshiba 3 TB No x
Need the model numbers. The serial numbers are good to see if the drive is under warranty, but the model numbers allow us to see what drive type you have.
It is a minor concern at this point as you need to save any data you want to retain somewhere, but then if there are any drive models which are SMR for example, we can warn you about those.
Your drives may be failing, your PSU may be failing. Your cabling may be flaky. Your SATA card may be overheating, or just flaky. Your drives may be overheating. Or it could be memory errors.
But you have no redundancy.
So any error may result in a failure, corruption or total loss of the pool.
Suggest backing up what you can save and rebuilding your pool with at least one drive of redundancy, and then you can try and work out the cause of your errors.
6 ASM1064 SATA controllers (PCIe 3.0x1) behind a 24-lane PCIe 2.0 switch…
This may not be as bad as I though when I saw the contraption, but it’s certainly not a recommendable or supportable configuration. Do not use that!
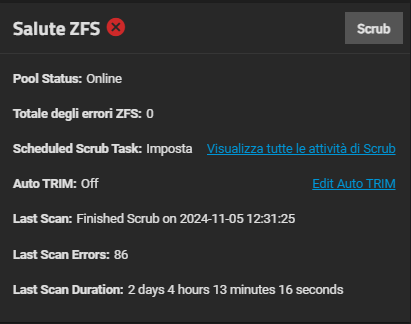
At now after scrub of 2 days have no error but ZFS Health is “bad” see after attached, and i don’t understand why.
So next time i transfer all data to other external NAS (58 TB !) reconfigure pool with a little change and re-copy all data to the new pool.
About 1 week of “work” …
The system has 5 pools, total of 29 HD / SSD / NVMe, 32 GB RAM, CPU an old AMD 9590 , MB Crosshair Formula
Thanks
Please post the output of zpool status -v HD8
If there are any errors at all, run zpool clear HD8 and see if that clears the status alert.
Also, what does the TrueNAS GUI ‘Alert’ say?