So my battle with SCALE has hit another snag. I have a test system that is using the hardware from my second ESXi host (running 1 host currently). I have gutted this system and all it has are a pair of M.2 boot disks and 2 SAS controllers. I put 2 SSDs in there just to be able to make a test pool.
As virtualization is borked on 25.04.01, I thought I would do some testing of other things. One such thing was iSCSI. After restoring my CORE config to SCALE, and re-arranging all of the networking to work properly, I tried to setup a new iSCSI share to test if it worked as expected. I have used the wizard and I have done it manually and I keep getting a Dead status:

I added the dynamic Portal connection in ESXi:
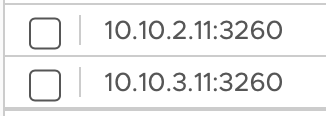
and the static links show up:

(I renamed the portal during testing - made no difference)
On the SCALE side, I have a simple setup:

(yes, it is nested in a datastore - tried it this way and in the root and it made no difference - it is a zvol)
You can see in TrueNAS that the ESXi system is connecting to the target:
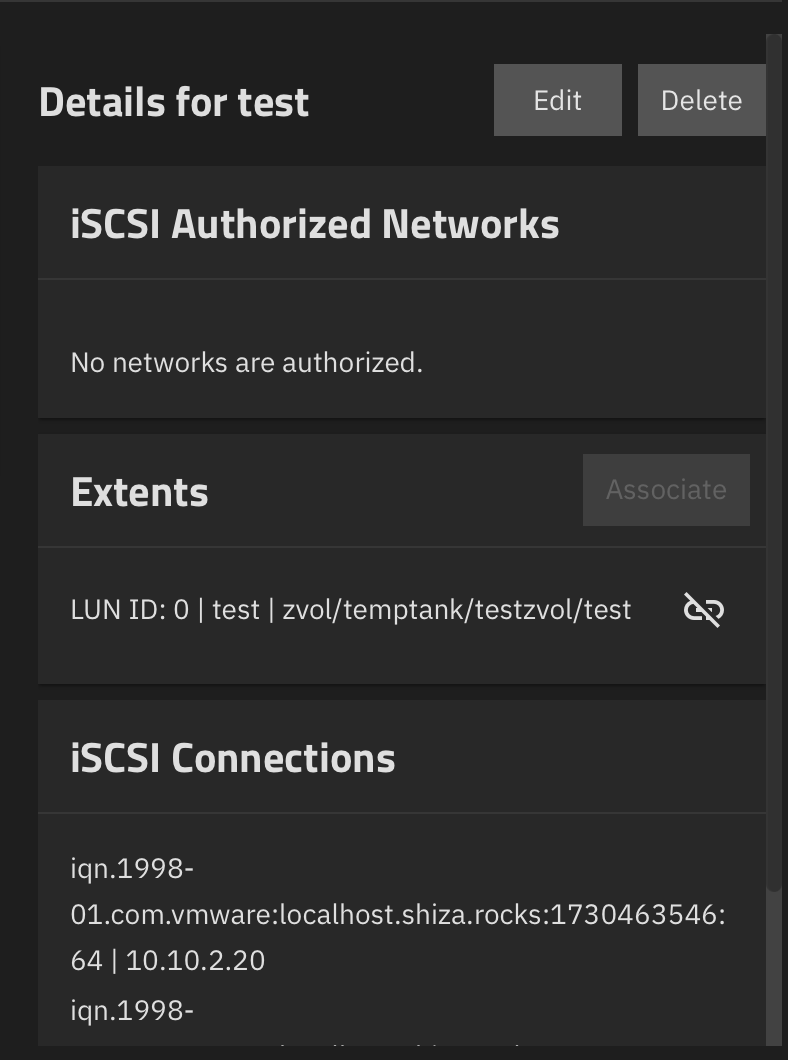
but in ESXi it is showing as dead:
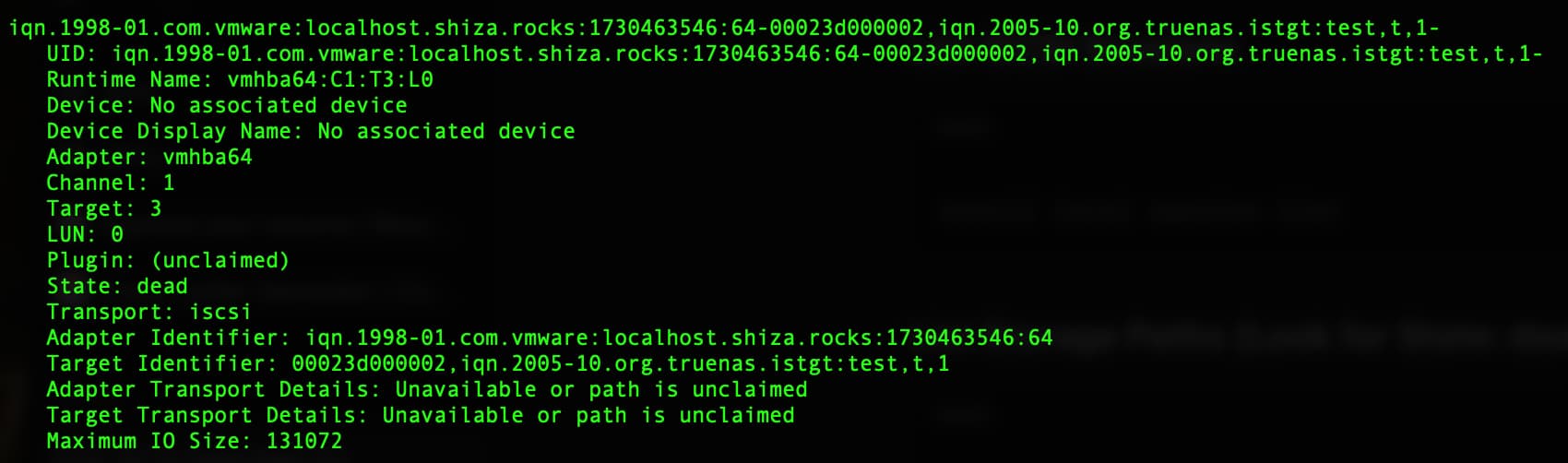
But TrueNAS things things are swell…
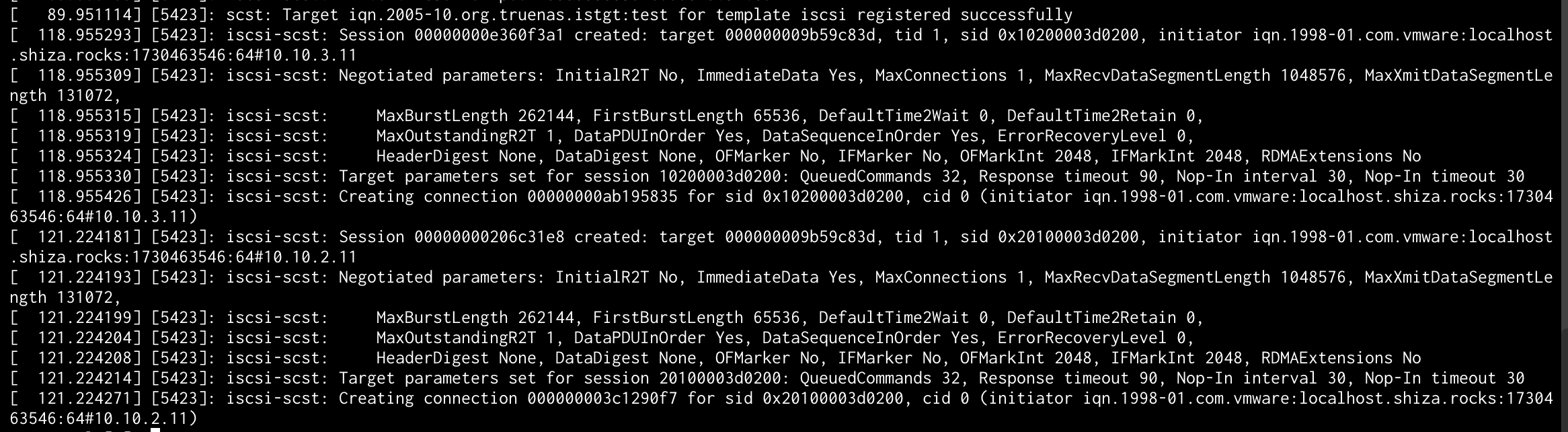
I am so stumped currently. I have rebooted SCALE (a number of times) and tried over and over with no luck. The iSCSI networks can ping between ESXi/SCALE of course. 2 NIC ports, all 10G through a 3850X. Each subnet is on a separate VLAN. This setup works fine with CORE:
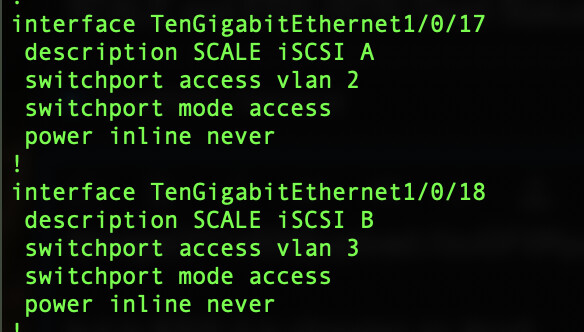
and here is SCALE’s network:
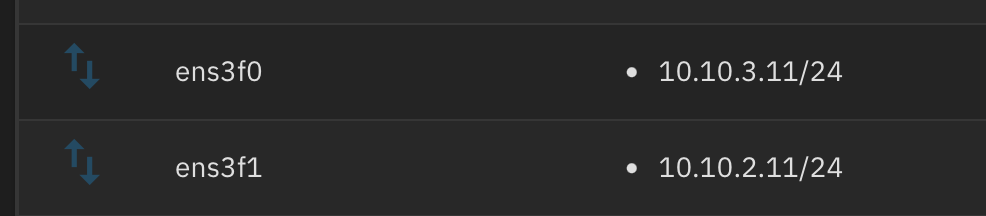
Finally, here is what SCALE is reporting:
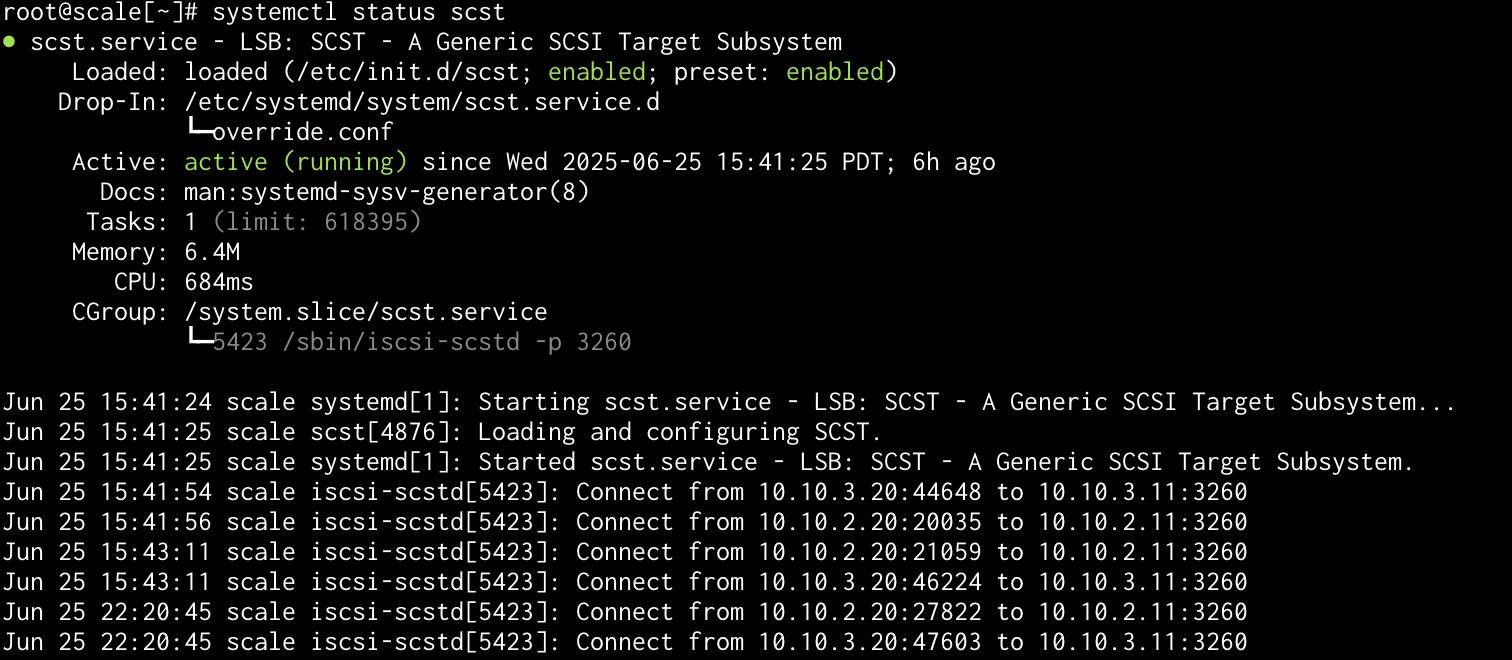
So, yeah, I am stumped. I really cannot reboot ESXi right now without an outage. May punt this SCALE back to default settings and start over - see if there is something coming from the CORE restore.
Any help at all would be FANTASTIC - I sure hope that I did not make some rookie mistake here…
Cheers,