The only container I run now is the latest version of plex.
This has happened before, where a new container or new version of a container causes the server to crash. I fixed it previously by simply removing the TRUECHARTS container that was causing it and it stopped crashing
Is there a way to revert to an older version of plex presuming you deleted your previous container and started from scratch? (ie: rollback not an option)
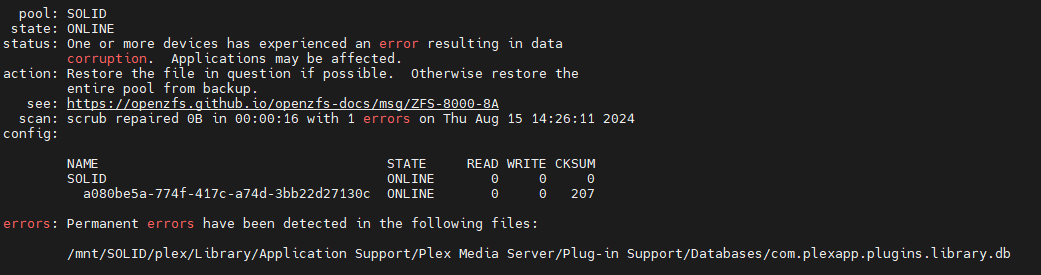
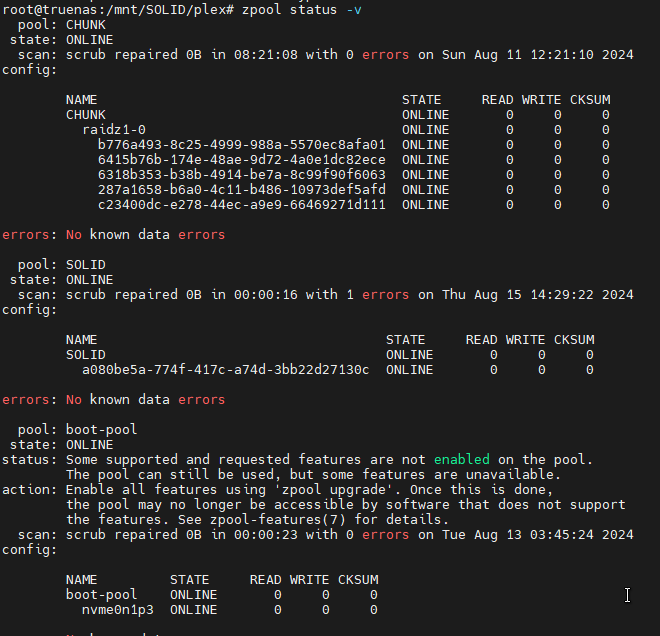
Scale crashing should have nothing to do with your plex app. You have 207 checksum errors on your pool, 207 too many. That’s very bad and not a Plex issue.
You seem to be confusing cause and effect. A Plex data file has data errors resulting from the lack of redundancy on your single-disk pool–the Plex file didn’t cause those data errors.
Is the SSD the cause of the “blocking state” entries in messages?
and if so why then does the server stay up with zero issues if I stop and remove the plex container?
ie; no more blocked states entries, no more crashes for HOURS. spin up plex ? scan media, BOOM crash, with those blocking state messages. Every single time like clockwork
Checksum errors can, among other things, be due to a failing drive, a defective cable or a bad motherboard/HBA controller.
Wouldn’t surprise me if it could also happen if you experience memory errors (but don’t quote me on that).
Your first priority ought to be to find what’s causing the checksum errors.
It’s not Plex, the issues with Plex are, as other have stated here, just another symptom of whatever is causing the checksum errors.
Try another cable, try another port on your motherboard/HBA, try a different drive. Memtest your RAM.
Sure, but it can’t do a thing about it. He’s been ignoring the errors likely for some time. It could have been corrupted on write, maybe due to memory or other issues, who knows.