I tried with jira but they ignored me saying that it’s not their problem and that I should try with the community ![]() After many restarts I came to the conclusion that my problem is too many containers (too many? I don’t know what that means
After many restarts I came to the conclusion that my problem is too many containers (too many? I don’t know what that means ![]() and it seems to me that truenas can’t wait enough time for the application manager to start with the containers. At the moment I have a little less than 60 containers
and it seems to me that truenas can’t wait enough time for the application manager to start with the containers. At the moment I have a little less than 60 containers
Can you send your Jira ticket number so I can take a look at it?
For what it’s worth, we haven’t seen this issue come up in any of our internal testing but will be trying to see if we can reproduce it in the next round of manual tests. It does seem like there might be a common thread emerging, pointing toward some kind of time out on systems with 50+ containers running, but we’ll have to investigate further.
Thank you very much in advance for your support, here is the thread - https://ixsystems.atlassian.net/browse/NAS-132921 , today I had another fun with starting docker after updating Scale to version ElectricEel-24.10.2, unfortunately no attempts to restart docker or ususet/choose pool gave good results, only I turned off all containers, turned off docker and restarted truenas. after all this the manager started itself. Last time it was similar - I uninstalled some containers to less than 40 and everything started up
1 Like
NAS-133304
48 containers
Found a solution from this thread:
Just go in Apps > Configuration >settings and change Base ip address from 172.17.0.0 to 172.16.0.0
That’s it ![]() now it works
now it works
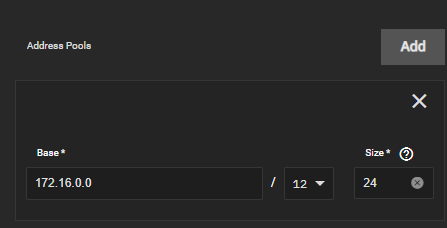
Edit: still does not work after restart ![]()
2 Likes
Hello,
I just had this problem, I just unset / set the pool and they are all back.
Thanks for the tip
In my case, I followed ChatGPT’s advice and made the following changes, which resolved the issue.
Original Error message from
journalctl -xeu docker.service
Feb 08 12:51:31 truenas dockerd[6902]: failed to start daemon: Error initializing network controller: error creating default “bridge” network: all predefined address pools have been fully subnetted
ChatGPT’s advice
Cause:
Your home router and Docker network are using the same subnet (e.g., 192.168.3.0/24), causing network collisions and routing issues.
Solution:
Choose a subnet that does not overlap with your router.
Edit /etc/docker/daemon.json:
{
“default-address-pools”: [{“base”: “192.168.200.0/24”, “size”: 24}]
}
Looks like the issue is related to docker apps running from HDD based pool.
And they will solve it in 25.04
Source: Jira
1 Like
I was like “huh HDD?” – 120s hard-coded timeout. That makes sense.
And explains why I’ve had zero issues - three apps, SSD mirror pool for them. Overkill? For sure. They don’t need the SSD. But - what is TrueNAS if not a fun hobby where we get to stick hardware into a server ;).
I cannot fathom 40+ apps. More power to you! I have a media app (Plex), a gaming app (Foundry VTT), and a dns updater app. I can see nextcloud plus office solution - but then again no, that’s not worth it for my use case. If I wanted to run more than one Foundry (no thanks), or went for something like nextcloud after all, then an ngnix app would make sense.
I can see the value in a WiFi controller app for those that use Ubiquity.
All that rambling aside: It’s good this case was found and will be fixed in 25.04. TrueNAS CE should work with 40+ apps on HDD.
Also, with 40+ apps, maybe do the nerdy thing and have some fun with a 9200/9300 Broadcom HBA in IT mode with a couple Intel SATA SSDs from eBay as a mirror pool. The data bits can be on HDD (Plex media for me somewhat obviously is), but the apps will be a little happier on SSD.
Nobody could debug this, but i found a workaround. All you have to do is after the system boot go to CLI and restart middlewared
sudo service middlewared restart
And all goes to normal.
1 Like
Thanks for that - this worked for me!
I’m getting this issue after rebooting for the first time in about a month. None of the above suggestions are working for me.
Version: ElectricEel-24.10.1
“None of the above suggestions” - how does it behave when your apps are on SSD? Caution that there isn’t a UI way to just move them over, you’ll have to make sure the contents of ix-apps move with all permissions, manually from CLI
If you want to stick to HDD, the suggestion was to try 25.04, which removes the hard coded timer. How does it behave there?
Can you confirm that the timer is the issue? Are there so many apps that they take longer than 120s to start, and then you get the error?
I am running my apps on HDDs. I saw the jira item regarding the hard coded timer issue, I’ll consider running the 25.04 beta to see if it solves the issue.
Can you confirm that the timer is the issue? Are there so many apps that they take longer than 120s to start, and then you get the error?
How would I confirm this?
The easy button is to change that. Run apps on an SSD mirror pool (those are truly cheap) and hand in app data via a host mount from HDD.
Now with 40+ apps, granted, that “easy button” may need some manual work, depending on where the data the apps access is now. If it’s already on host mounts (separate datasets from ix-apps) then it’s truly easy.
Sure 25.04 will solve this for you, RC1 out shortly. But solve in the sense of it won’t fail - it’ll still take longer than 120s to start them all because HDD.
Apps on SSD sounds so much nicer all around.
Works better than docker restart ! Thank You!
I don’t think enterprises use the Apps feature to be honest. I’m actually interested in seeing the metrics for Apps usage in enterprise deployment if anyone knows where to look.
Hello. I found this thread while trying to debug my truenas scale apps issues.
Gist is I have a pool that is currently slowly dying. I have created a new pool and replicated data from my backup onto it. I tried to change the selected pool for apps to my new pool, but docker fails to start. I have tried restarting middleware, unseating/rechoosing the pool multiple times. The journal does help much as it said docker exited with error code 1
Any help identifying the issue would be super helpful. I am on the latest release version of Scale EE.
Oh also forgot to mention. When I choose my original pool with my existing apps, it starts without error.
I found the issue. For some reason the entire pool was set to read-only.
1 Like