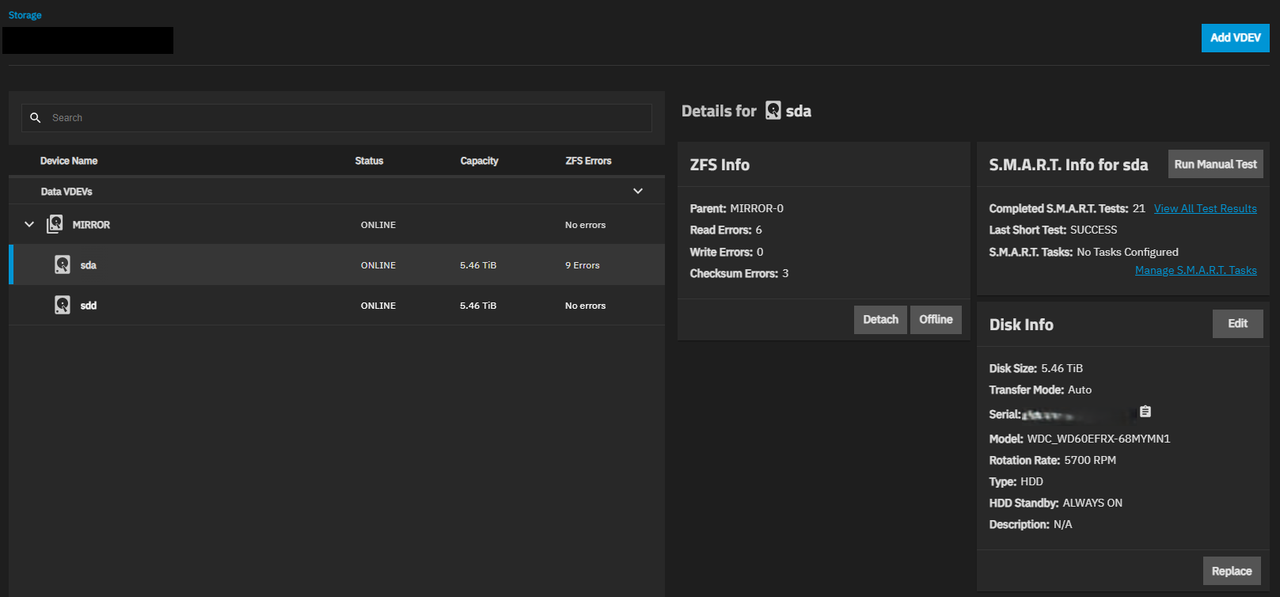
I’m new to TrueNAS and is currently having issue with one of my drive.
I am currently on TrueNAS SCALE Fangtooth 25.04 [release].
There’s one drive showing Read Error & Checksum Error after the last scheduled scrub test.
My system has 2vdevs with
2x 4TB mirrored drives
2x 6TB mirrored drives
I have did the following troubleshooting:
Detached the errored drive
Extend the vdev using the same detached drive and resilver
Run manual scrub test and got the exact same errors as per above screenshot
Detached the errored drive again
Did a clean on the errored drive on windows using diskpart
re-attached the drive to the vdev and did another resilvering
Currently i’m waiting for the next weekly scrub to check whether the errors will occur again.
However, what is the issue that i could be looking at? I looked up the forums and it found some says that this might also be an issue of the motherboard / sata ports.
Appreciate if i could have some feedbacks and tips on how to check what the issue is.
Hmmm… I don’t know for sure, but how about the most obvious one?
A broken drive?
That could also be.
Normal procedure would be to swap the affected drive with a NEW one and then if the errors persist, there might be a SATA, Power, Mobo, controller, whatever problem.
Do not wait, start another scrub, verify it passes. Waiting “could” be putting your data at risk.
There are many things which could have caused this, until you see this repeatedly then you will not know for sure.
Please give my Drive Troubleshooting Flowchart a try. I can see you missed some steps, or you just didn’t mention them (smart long test for example). I also can see that with Fangtooth, I may need to update the flowcharts slightly. I like the screen format you posted, it provides good data but does not clearly tell you if the drive is bad or not.
In terms of root cause, if the errors do not persist (after a zpool clear and a zpool scrub the errors do not return) you are dealing with a intermittent issue. That could be anything from a very brief power glitch (your TN box is on a UPS, right?), to a memory DIMM starting to go (are you using ECC RAM?), to a cable / backplane issue that was triggered by an odd vibration as someone walked by. If the errors do not recur, I consider myself lucky I use ZFS and don’t worry about it.
If the errors occur again, then you need to find the culprit. It could be a drive starting to fail, substituting a known good drive is a good start. I also look at cables to the drives, both data and power supply, and try wiggling them during a scrub, do error rates go up? Since you are seeing this on one drive out of four I would not expect the cause to be memory or HBA, that should hit all the drives.
I once had a power connector walk out of a Supermicro backplane just far enough to break one of the power connections. 4 drives dropped off all at once. I visually spotted the connector issue, shutdown the TN, reseated the connector (insuring it was fully seated), and brought the system back up. When the pool was imported it resilvered the 4 drives that had dropped out (yes, we got lucky, this was a mirror pool and each drive was part of a different vdev), and things were fine from then on.
Thanks for the feedback. If you see room for improvement, keeping in mind that the main focus is drive health and to assist slightly with ZFS, to not let someone think there is a drive issue, than please let me know. I may expand the ZFS flowchart, I’m just not 100% certain I want to, but I am evaluating it.
Thanks for the feedback for my issue guys, really appreciated that. I checked the scheduled scrub that was ran over the weekend and the drive errors are gone for now. I suspect that my issue is mostly with the drive. Just wanna reach out as i read from other posts that not only the drive will cause the read and checksum errors.
Hope not as i was only running this for a few months but i suspect so as well.
This is a very nice flowchart. I’ll definitely use this as a guide. Bookmarked it for future use!
I did click on the test but doesn’t seems like it did anything. Is there a console for this in the web interface?
Nope, it’s running on desktop pc with normal Ram modules. Which is why i think it might cause the errors. But it seems fine after the diskpart and clean on the drive in windows. I’ll be monitoring this further as now i suspect is my drive issue.