Several SATA HDDs, which I don’t believe are related to this issue
I have no GPUs or other PCIe devices other than the two NVMe drives
All of the hardware was purchased new and are less than a year old. NVMe drives are installed directly in NVMe slots on motherboard and SATA drives are plugged directly into SATA ports on the motherboard.
Sequence of Events
2025-02-01: Updated motherboard firmware to latest version (v2810)
Not convinced this is related, but worth noting
The only change I make after each update is changing the memory frequency from 4800 (default) to 5600 (factory spec), but I’ve been doing this for ~9 months now without issue
2025-03-17: System meltdown (happened overnight while sleeping, there may have been a scrub running)
2025-03-22: System meltdown (happened when awake, but nothing out of the ordinary running)
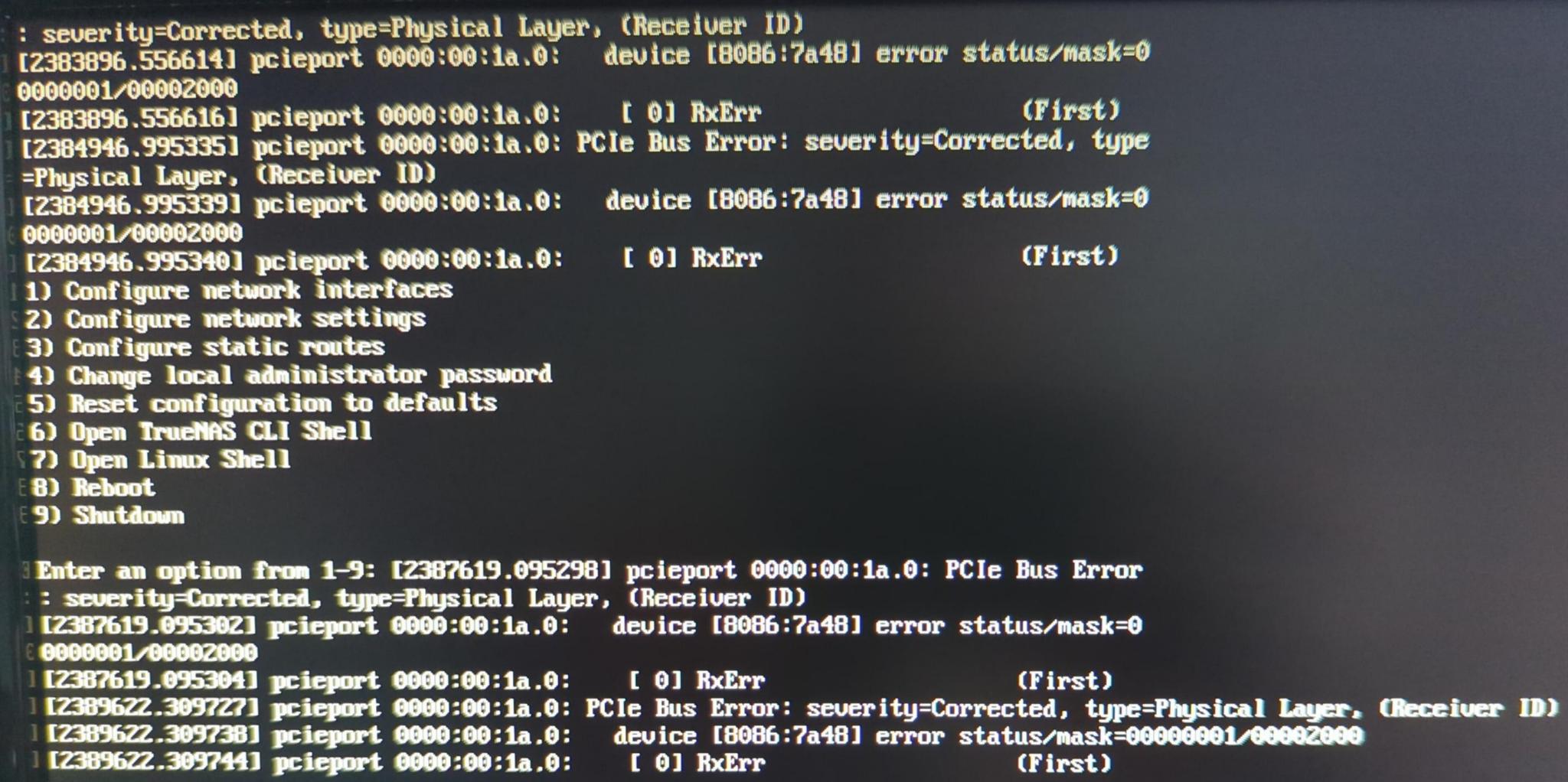
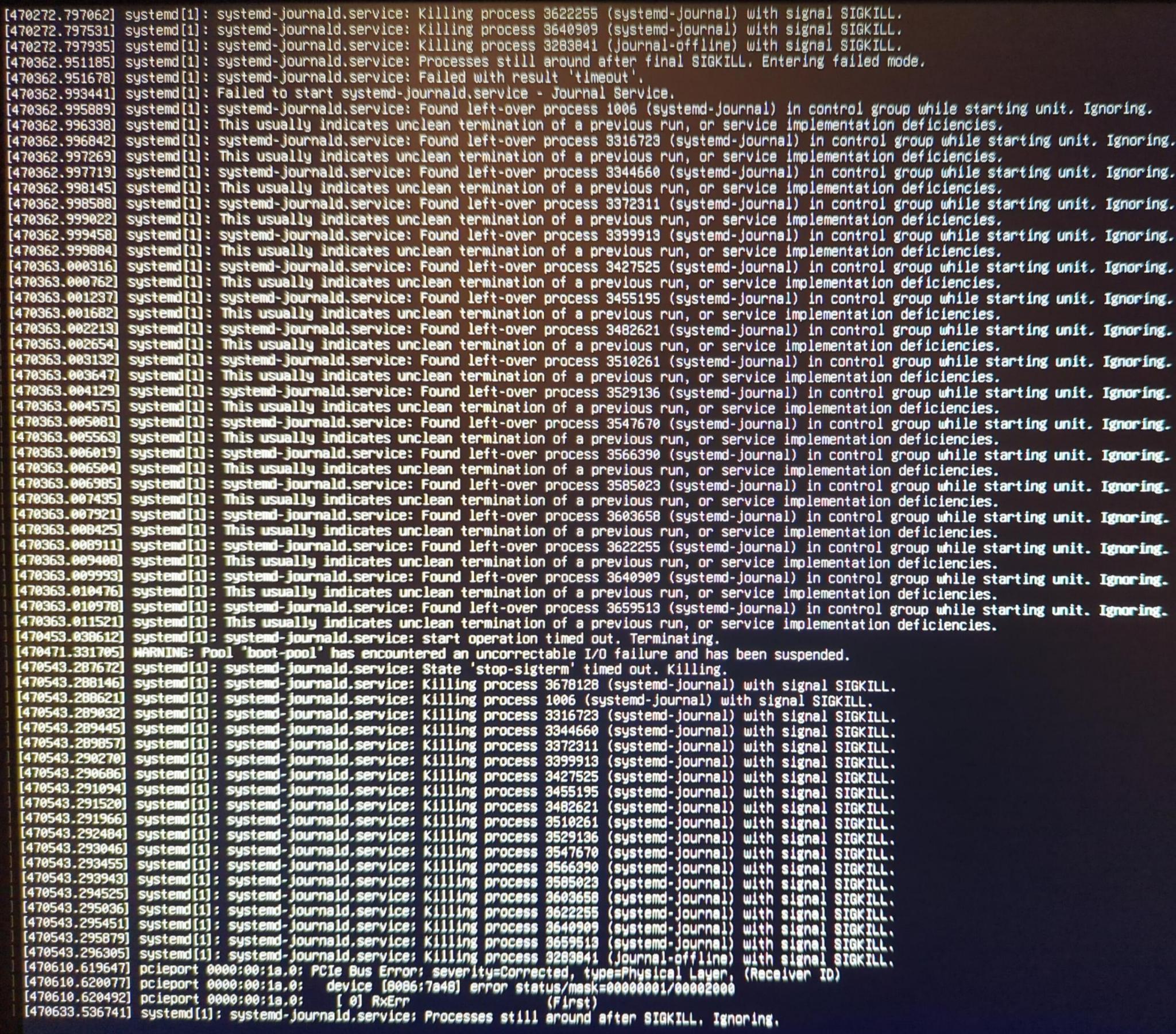
TrueNAS console showing PCIe Bus and other error info
Can’t connect to any app or TrueNAS web UI, on either of the two onboard NICs
Can’t access files via SMB
Can’t SSH into TrueNAS
The only thing that seems to work is Home Assistant OS, which runs in a VM
When I do a force/hardware system restart, system enters BIOS and claims there are no boot devices
When I do a force/hardware shutdown and reboot, everything seems to go back to normal until the next meltdown
TrueNAS UI reports no errors in the UI - no notifications, all disks and pools reported to be in good health
Boot Drive as Potential Source of Issue
My first guess was the issue is related to the Kingston boot drive, mostly because of the BIOS claiming there were no boot devices.
However, I ran a long SMART test on this device after each meltdown and they’ve both passed (although I assume this won’t catch everything). I ran command smartctl -x on the boot drive. One interesting thing I see, despite passing SMART tests, is the line, Error Information Log Entries: 18, although this number was queried before and after the second meltdown and did not change. When I run this command on the Samsung NVMe drive, it reports 0 Error Information Log Entries.
One interesting thing I see in the 2025-03-22 console errors is line, WARNING: Pool 'boot-pool' has encountered an uncorrectable I/O failure and has been suspended.
Motherboard as Potential Source of Issue
I guess it’s also possible there is an issue with the most recent motherboard firmware update, although I’m not sure why it would have been running without issue for ~6 weeks until now. Unfortunately, I just checked and there is not a newer version I can try right now.
Request for Help
Does anyone have any ideas? My best guess is the boot drive is bad, but I would hate to replace the boot drive and rebuild the system, only to find out that wasn’t actually the issue.
Is there anything I can do reasonably easily to provide further proof that the boot drive is indeed the issue?
If we are convinced it is the boot drive:
Shouldn’t we expect SMART tests or TrueNAS to otherwise detect and report this in the UI?
Does Kingston make poor NVMe drives, or is this just bad luck?
Running command zpool status -v shows no issues with boot-pool, so I’m still trying to find evidence that the drive itself is the issue:
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:54 with 0 errors on Sun Mar 23 03:45:55 2025
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
nvme1n1p3 ONLINE 0 0 0
Replacing the boot drive is as simple as saving the configuration file, wth secret seed, installing a new device, installing TrueNAS anew and loading the configuration file. 5-10 minutes.
Just do it.
If it’s not the boot drive, I wonder if your PSU is going marginal, i.e. all is well until you have a scrub and the system is running a high load on a sustained basis. I had some pretty weird errors come up when my PSU started to fail and once I replaced it, they all went away.
Thank you for the suggestion. I’ve disabled PCI Express Native Power Management and ASPM. Unfortunately, I’m not sure how much time should pass before I could safely say this was the issue. It sounds like these settings have been default for the entire existence of my machine, so I’m not sure what would cause this to be a problem all of a sudden. I would also like to think that a default setting in the BIOS causing this much of an issue would get more attention.
This also makes me wonder if there are also TrueNAS power settings which may cause or have contributed to this issue.
Thank you for the suggestion. I failed to mention I have a Thermaltake Toughpower GF3 (1350 Watt), which is way more power than I need right now (might add large GPU later) and is supposed to be a quality PSU. Of course, it could be faulty. The system is also on a full sine wave UPS and hasn’t experienced any unsafe shutdowns other than to address the two meltdowns.
I will keep this in mind though in case I have further issues.
This may be a red herring, but the 14900K may be dodgy. Intel eventually admitted to a manufacturing issue causing them to (permanently) degrade. If you just recently updated the BIOS you may have been running without their fixes for long enough to cause damage.
Do you happen to have access to another CPU that fits the same socket?
Good point. I don’t have another CPU, but I am somewhat familiar with the CPU issues. IIRC, there were two issues:
Some sort of microcode issue causing an overvoltage problem
Some sort of manufacturing issue causing oxidation
Last I read, only the first issue affected my CPU, which is why I updated the motherboard firmware when a version was released to address this. The machine was only running for ~7 months with this issue, and at low CPU utilization, so I would hope that it’s not damaged, but I’ll keep this in mind.
FWIW, the plug load on my system never exceeded 125W and the PSU is rated for 750W. So that’s a 5x “safety factor” and yet the system became unstable. However, my issues were mostly related to HDDs becoming unresponsive, so the other suggestions re: the CPU and SSD boot disk are likely a better starting point.
The Bios update could have altered the power management profile employed? Or created a condition where it could occur i.e. introduced the conditions that lead to it
The CM can have 700+ W on the 12V system no issues, but you have to be careful on the BQ as to where you put the loads in case you exceed the Amps available
Then you get into if the voltages drift off spec you get unstablity
We do not know, when did he buy the MoBo/CPU.
All we know is that he last updated the BIOS on 1st of February this year.
The issue got publicity last mid summer and the first BIOS-es were available at around august/september.
If he did not update the BIOS then, it is most likely the CPU has already degraded by that time.
(Especially, that ASUS was deeply involved in the root cause by enabling the 4000W limit as default for an otherwise 256W rated CPU. ) Having a powerful PSU is actually, I think is worse for him, because it COULD supply that overpower to the CPU.
I recommend to RMA the CPU ASAP.
Had another meltdown today. Best guess is the boot drive has failed because:
Despite many reboots, the system no longer sees the boot drive
I booted into a live OS and it does not see the boot drive either
I moved the boot drive to a different slot, which is on CPU rather than the chipset, and the system still does not see it
I’ve seen several reports of the Kingston NV2 being unreliable, but nothing concrete
I’m not really seeing any evidence that this is a CPU issue, although it’s possible, so I’m going to try replacing the boot drive first:
When the meltdown occurs, there are some things (e.g. Home Assistant VM on other NVMe drive) that continue to function without issue
The live OS appears to be functioning normally
The other day, I was stressing the CPU with local AI and it did not cause any issues
I did save the config after the past couple of meltdowns, but I wonder whether they may be corrupt, if the drive was actually what was causing the issue.
I’ve indicated twice that the boot drive is my first/best guess, and I said I’m replacing this first, so I’m not sure what your issue is. Finding a few people, and potentially myself, with a faulty NV2 is not concrete evidence that these drives are generally unreliable, which is a fair and accurate statement.
Just to close the loop on this, the system has been stable for the past ~4 weeks with a new boot drive (Samsung 990 Pro), so it’s probably safe to say the NV2 drive was at fault. I guess the moral of the story here is one might want to avoid the Kingston NV2 drives.