Hi all!
I was wondering if anyone could help ascertain if a fast metadata vdev will help with this.
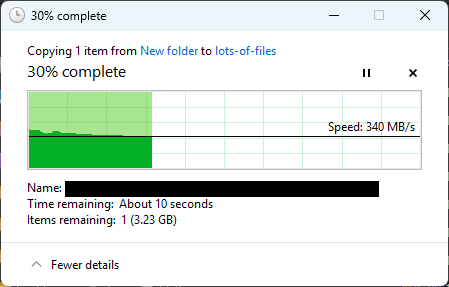
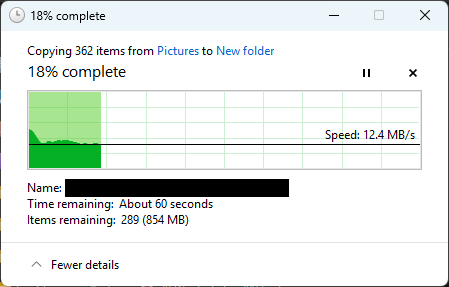
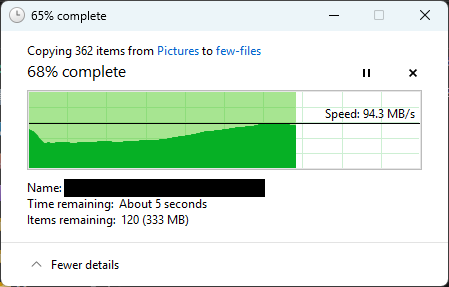
When copying (in windows via SMB) from one dataset to another on the same pool we get very slow (sub 5mB/s) speeds often. Normally the gigabit machines max out on transfers and the 10gBit machines nearly do too. Often with lots of 10(ish) megabyte files (exr image sequences).
Setup config as below, any help appreciated; thanks!
Truenans scale ElectricEel-24.10.1
Bare metal install
500GB EEC ram
Intel Xeon Gold 6326 CPU, 2.9ghz
1 pool, 3 RAIDZ2 vdevs, each with 8 20TB SAS drives (spinning).
useable capacity 317.9 TiB
used 232.44TiB
Available 85TiB
No special devs (yet!)
Datasets are…
Type:
FILESYSTEM
Sync:
STANDARD
Compression Level:
LZ4
Enable Atime:
OFF
ZFS Deduplication:
OFF
Case Sensitivity:
ON
System is connected to network via SFP+ 10gbit connection and as mentioned happily maxes this out on normal transfers to and from the workstations.
Server-side offload works between datasets and even between pools - but there’s a significant difference between “single large file” and “many small files” especially when copying to and from the same set of spinning disks.
Larger recordsize values can help here. Even when bclone is engaged you’re doing lots of small metadata writes - basically incrementing a cloned counter for each record - and the reality is that magnetized spinning metal is a lot slower to handle that kind of write workload vs. SSDs:
My understanding is that there’s certain things that need to match for bclone to work between datasets - recordsize is definitely one, but I believe there’s also acltype and aclmode considerations. I’ll have to put it on my radar to make an exhaustive list.
I don’t profess to know much about inner workings of file systems and I know zfs does stuff differently as a COW filesystem. So the zfs system generally wouldn’t be able internally during a file move look at the file(s) contained in the source of Pool1/dataset1/my_photos, and a destination of Pool1/dataset2/my_2025photos and see that the file(s) to move are on the same pool (Pool1) but in different datasets so lets just change the pointer. And this is because zfs actually treats datasets as separate file systems even if on the same pool. Correct more or less?
And this is because zfs actually treats datasets as separate file systems even if on the same pool.
root@bob[/mnt/dozer/CLAUDE]# zfs get type dozer/SHARE
NAME PROPERTY VALUE SOURCE
dozer/SHARE type filesystem -
The ZFS type of what TrueNAS / FreeNAS has historically called a dataset is “filesystem”. It’s generally the case across all OSes that you can’t rename across filesystem / device boundaries. Renames are expected to be atomic.
Copies (even with block cloning) can take time because:
client opens file (including locking)
client enumerates streams for file
client issues FSCTLs to do server-side copies (typically 16 x 1MiB chunks per request) of streams
client closes file
For every file. (3) is generally fast when able to block clone, but it doesn’t improve situation for other SMB requests. Every request is subject to network latencies as client makes a request and server replies. When you start dealing with small files the ratio of “data” requests vs other stuff gets worse so perception of speed drops.
Just out of curiousity, why is anyone moving tons of little executables around like this anyway? You could symlink stuff to make it appear to live in many places at the same time without using extra space, and I think hardlinks do the same in a less obvious way. In the windows world, these are simply shortcuts.
I think there might be a way to tar or gzip the little stuff together, move it, then unpack it at the destination because it’s faster to move a blob of a tar than individual files…and this is server-side voodoo, probably not recommended. I can’t imagine end users doing all this shuffling to begin with, managing that weird workflow without a tool or a script for the heavy lifting.