Hey guys,
Surely this isn’t normal…
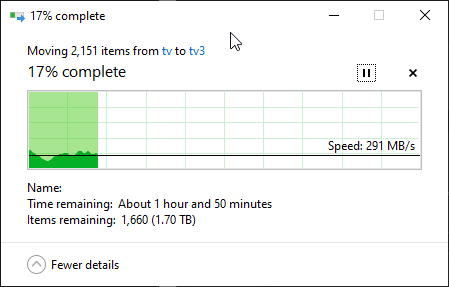
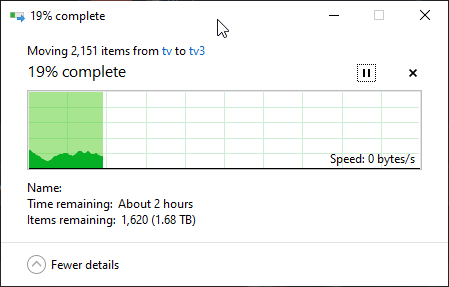
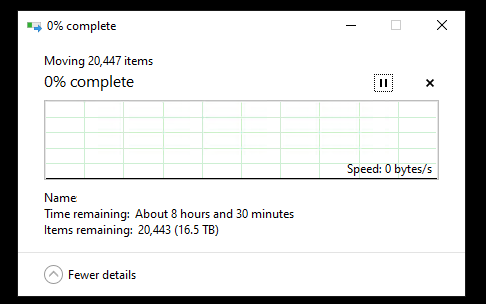
Any time I copy a large amount of files, between each file, it drops to 0bytes/s.
It starts off fine for a couple of seconds, until what I am assuming is when the file is transferred, then drops to 0 for ~5-10 seconds, then keeps going.
Im 99% sure its not my hardware, I’ve replaced my NIC/HBA, have tried a fresh install with config backup, and come to think of it, have also tried on a different PC.
This is happening between different pools
System specs…
AMD EPYC 7532 32-Core
128gb ECC ram
10gbe Broadcom NIC
I have set:
sudo zfs set sync=disabled Rocinante/TV3
sudo zfs set atime=off Rocinante/TV3
sudo zfs set compression=off Rocinante/TV3
sudo zfs set recordsize=1M Rocinante/TV3
on all my shares (this helped overall speed on big files, but not with multiple files).
This is driving me nuts because I need to move everything off one pool across to others, so I can remake it - smaller. (Power consumption of 24x 3tb SAS disks is killing me)
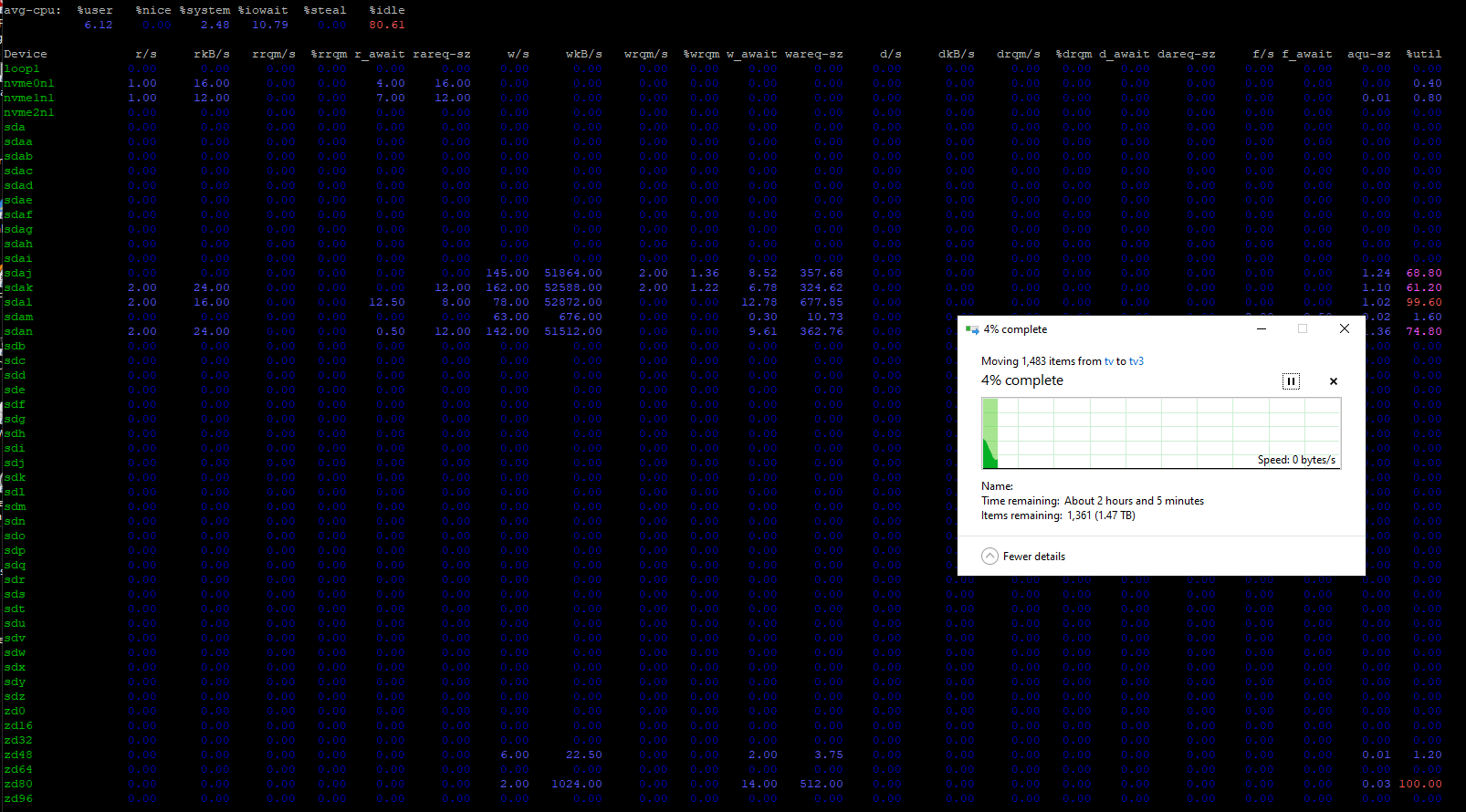
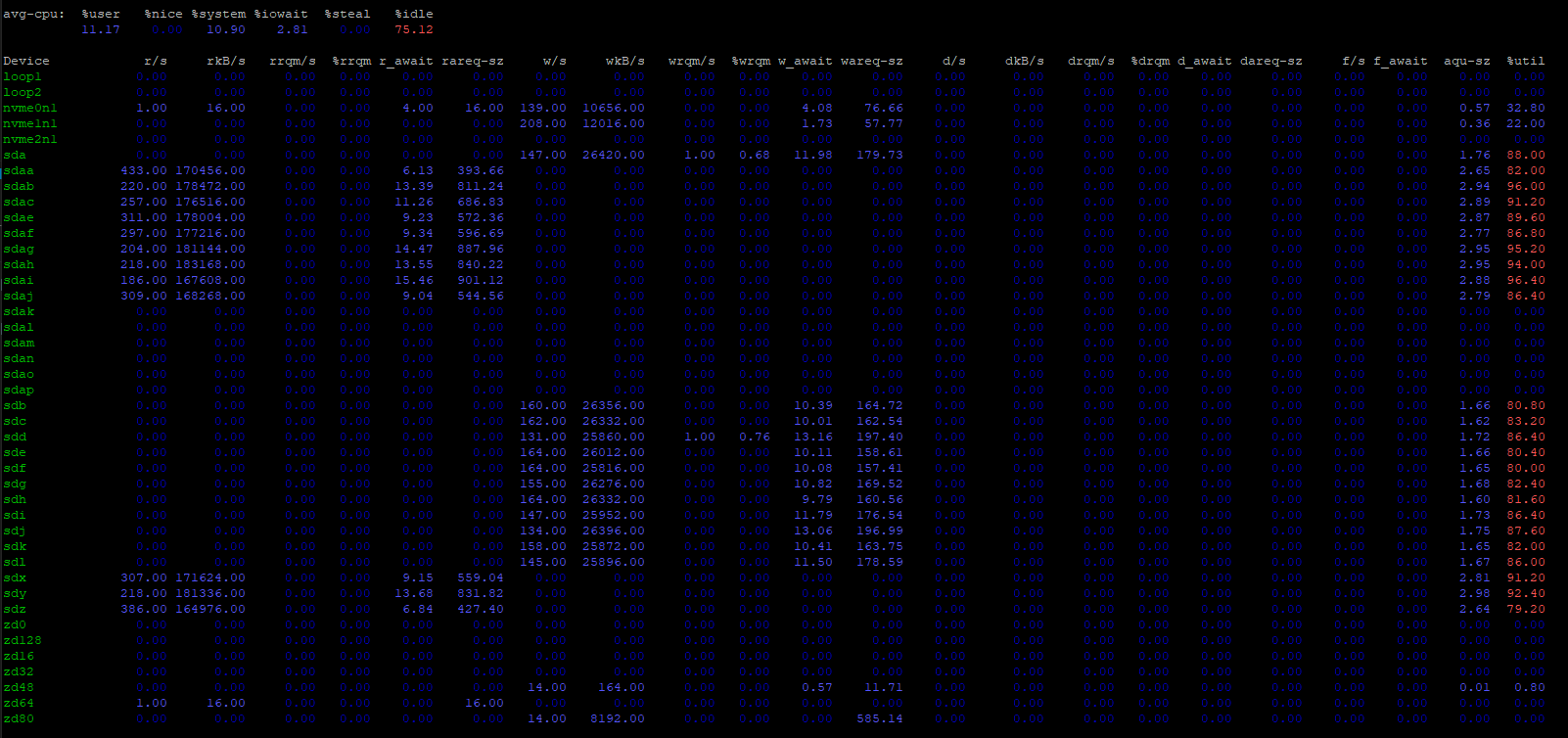
Check what is going on on the NAS when the hiccup occurs. Look at “disk busy” and IOPs stat. Check transaction group size — it is based on ram size and could end up being too large for your pool configuration (aka pool too slow), you can try tuning it down.
So I tested by copying from one SAS pool to another SAS pool (the above was SAS to SATA), and it looks like it is still doing the same thing, just for a shorter time. It will hit 0bps for 1/2 seconds, then continue again faster.
on top of that, I also had delays where it would sit there “calculating” where the disks weren’t getting smashed… (this is from a SAS pool to the SATA pool)
SAS to SATA:
I feel like I might have two problems? One being a SMB issue, the other a bottleneck on sdal?
EDIT: dumb moment - there was some activity which was causing the pool that sdal is on spike from time to time, I thought maybe zfs/ truenas was doing something silly where even though the disk wasn’t part of the pool, it was waiting for it, but that was just me instead. Above comments still accurate though.
There is nothing magical about SAS. Each rotational magnetic disk can support a ballpark of 200 IOps. Vdevs comprised of such drives can yield worse or better performance.
It seems all your writes go to just 5 drives? What are other drives doing? Why are they idle?
What is make and model of sdal vs sdak? The former seems to have reached its limit at much lower IOPs load – but even if it was 2x faster that would not have saved the day.
I think my original guess is correct – you have a tiny pool of 5 disks in an unfortunate configuration, and too large transaction group size, due to high amount of free ram. You need to reduce transaction group size.
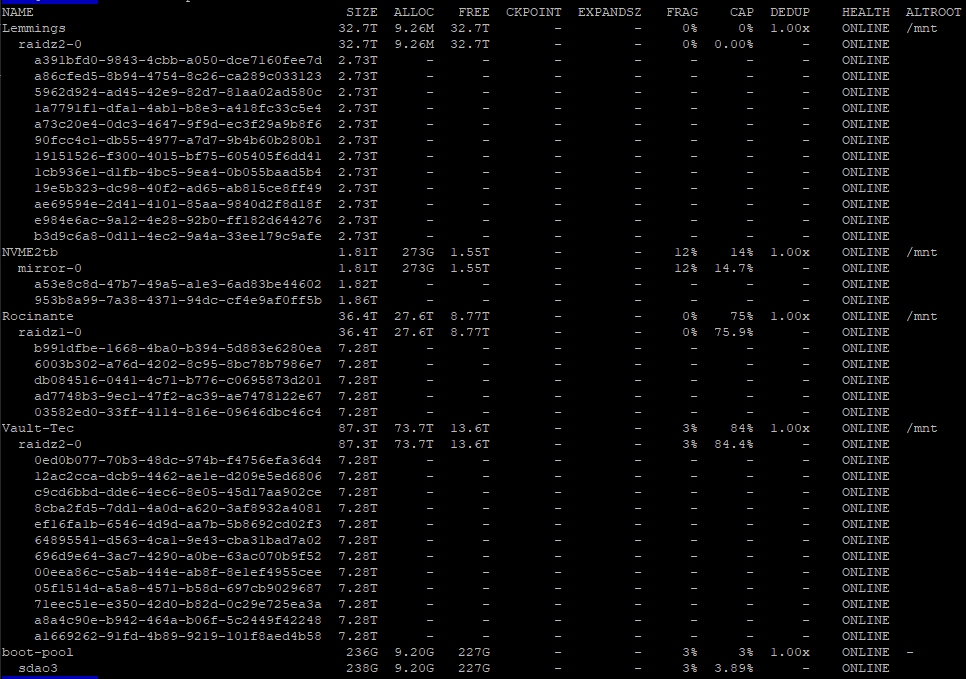
Please share your pool configuration. zpool list -v
I was more so mentioning “SAS” as they are overall quicker than 5400rpm disks, which is where I thought a bottleneck sat.
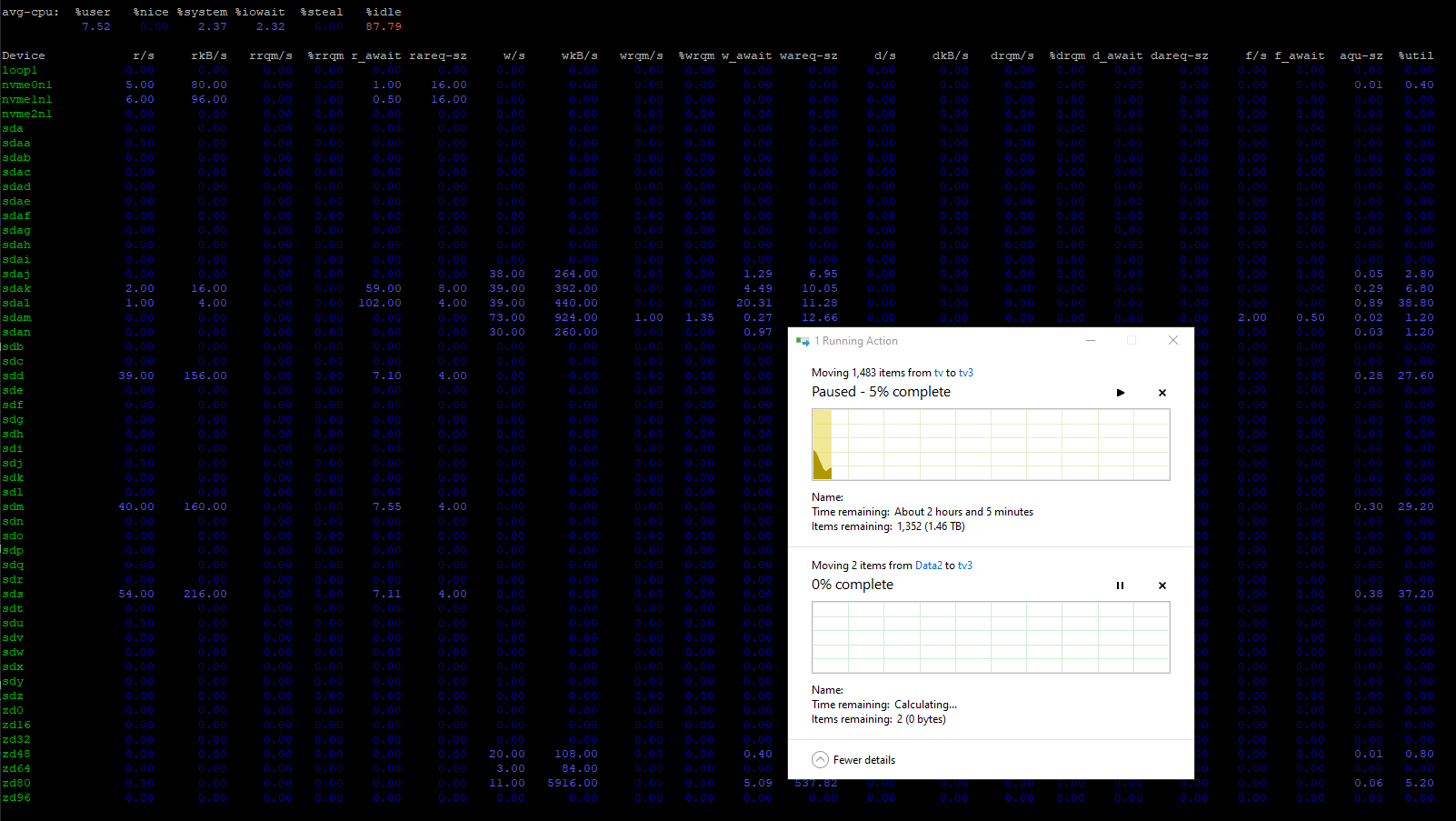
I’ve dropped the amount of disks in my “Lemmings” pool and changed to raidz2 (needed to move everything off it, destroy it, and re-create it) (power saving exercise )
Also decided to re-make the Rocinante pool, because it was quicker to move everything off it than wait for it to finish expanding.
However, still having the same issue. I do hope it is an issue where reducing the transaction group size would fix.
(I’ve also added another disk to the Vault-Tec pool)
Updated screenshots below:
This is a copy from Rocinante to Lemmings