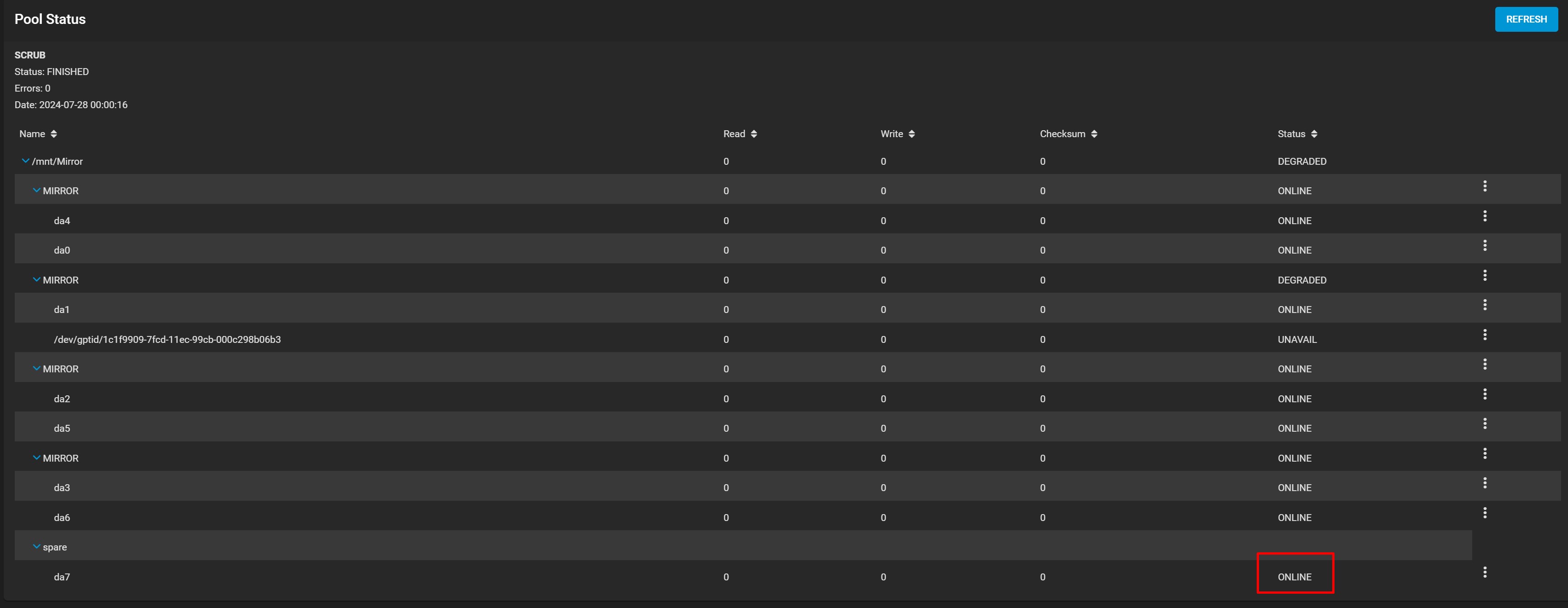
I had a drive fail a week ago, and I just found out today (a week later).
I don’t think my Spare drive “activated”? Based on what I’ve seen on other posts, it should say “INUSE” but mine just says “ONLINE”… is there a way to check if it’s actually being used currently (like it should be)?
Just want to make sure i actually still have my redundancy until i can procure a new drive…
Correct it doesn’t appear like it has. How did your drive fail? Assuming you didn’t offline it and the system kicked it out of the pool then the hot-spare should have activated.
To the best of my knowledge, I’m think the drive controller failed.
I removed the drive from the server and plugged it into a SATA-to-USB adapter into my desktop for testing, and the drive doesn’t spin up, and nothing is detected by the computer.
And no, I did not offline it or remove it from the pool (you can still see it in the pool in the above screenshot). I hadn’t logged into TrueNAS in at least a month.
Now that I’m thinking about it, however, on that day (Date indicated in the Alert I noticed in TrueNAS), I did have a power outage. My Server is on dual UPSs, and I did gracefully shut down my server.
I’m guessing this drive just didn’t spin back up after it had stopped.
I assume if the controller is dead, on boot TrueNAS just read the (actually) Failed drive as simply “Removed”… and thus not triggering the Spare…
I’m not sure if that “should” have triggered the Spare as far as the program is concerned (obv in practice, it should have, but if the system didn’t detect an actual failure, i get it)…
Yeah not but I wouldn’t be surprised if the drive vanished during your outage and never came back that may well not be enough for the hot-spare to activate. What version of TN are you running?
The only thing I can think of, is that the Hot Spare is too small.
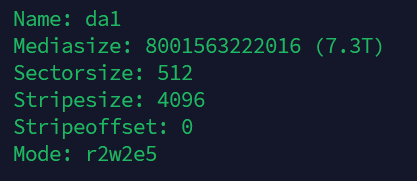
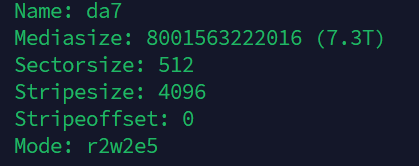
This can happen if a different vendor is used. Even 1 Sector too small is enough to make it fail. Check the size of both the Hot Spare and the Mirror vDev with “da1”.
As for a storage device failing on power off, (graceful or not), it happens. But, to be clear, ZFS won't corrupt any existing data on a pool during such an event. (Unless you loose redundancy...) ZFS was specifically designed to support graceless and crash based power losses without pool damage, as part of COW, (Copy On Write).
Good thought, and I actually had never thought of checking that.
It is true that my Spare drive is a different vendor than the 8 drives I actively use (4-way stripe, mirrored)
Upon initial inspection it appears they are identical in media size:
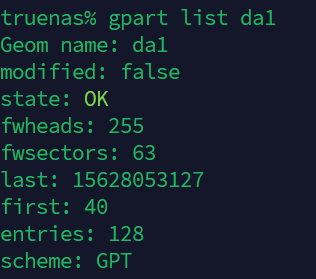
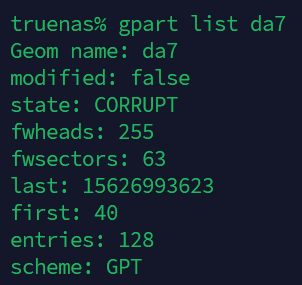
HOWEVER, while running the command (gpart list da[*] ) I did notice something which looks like a promising lead onto my issues here… but I have no idea how to troubleshoot further… da7 is reading “state: corrupt” while also having a “Last” value smaller than da1 ?
Doesn’t make sense to me how they can be the same size and sectorsize, but not the same amount of sectors?
My highly un-educated guess is that the partition table for “da7” is corrupt.
My highly un-scientific suggestion is remove the hot spare “da7” from the pool, wipe it with simply zeros, then re-add it to the pool as a hot spare. The wiping will take a long time…