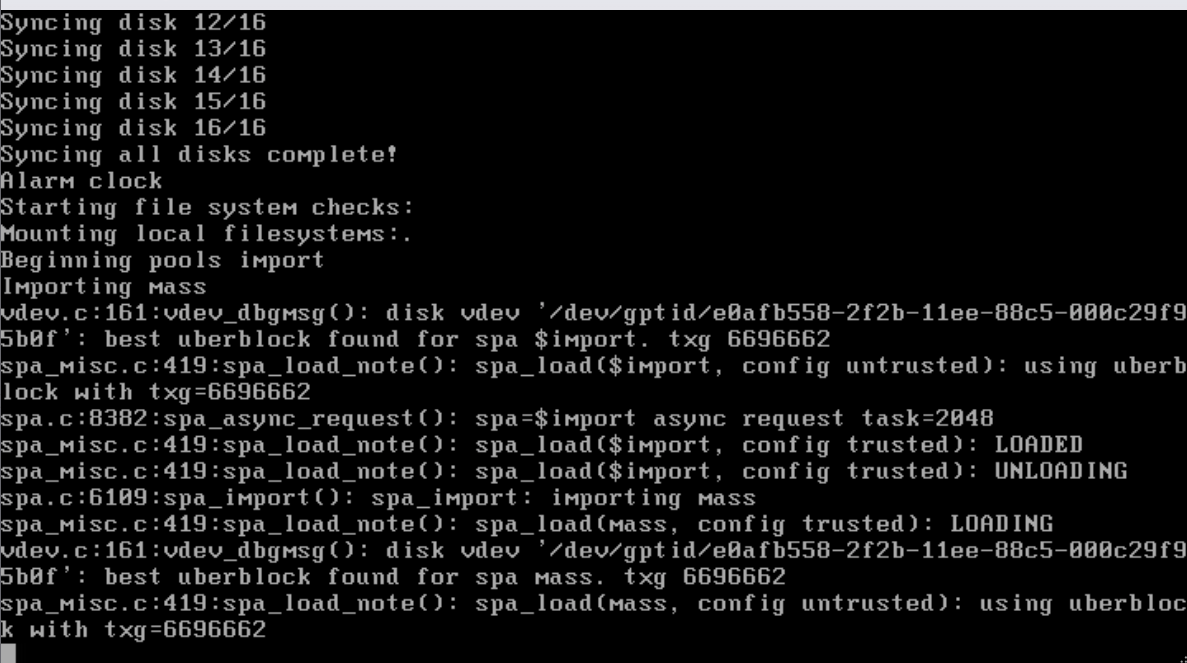
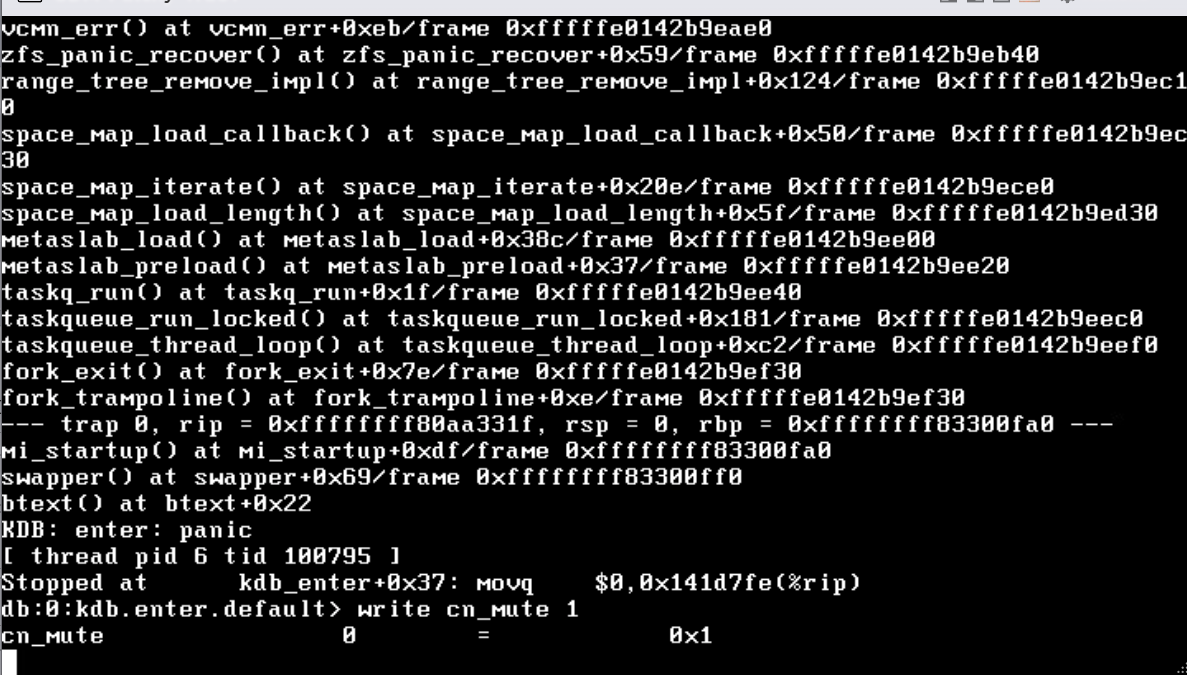
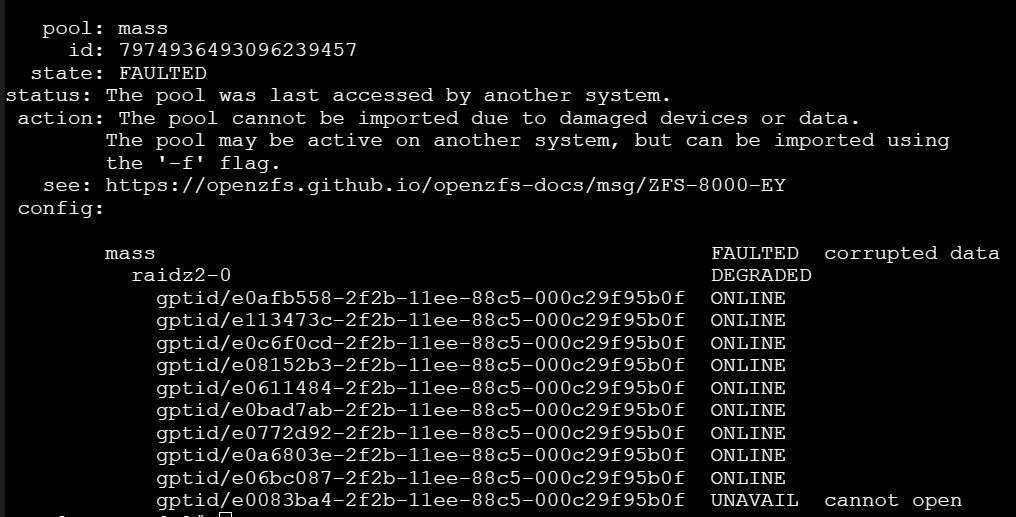
So I have a TrueNAS core system that has been running with no issues for years. It is a VM in an ESXi system, I have passed through my HBA to the VM so no middleman stuff going on.
Today out of the blue TrueNAS after years of no issues just hard crashed and just keeps boot looping. I did some testing and found that when I have physically removed the connection to the drives in A2 (array 2) it will boot no issue and I can get into A1 (array 1). But if i reach 8 disks or more of A2 boom it fails. It looks like it allows the disks in if it doesn’t see them as a pool but the second it has enough to see it as a pool it fails and causes this panic and loop.
Currently I have A1 running and still using the NAS at this time with no issues but I have no idea what is up with A2 or how to get it back. Any help will be very much appreciated.
Below are the pictures of the errors I haven’t found anything like this on the forum.
It might be a corrupted file system… space map specifically.
Could be caused by hardware or software…
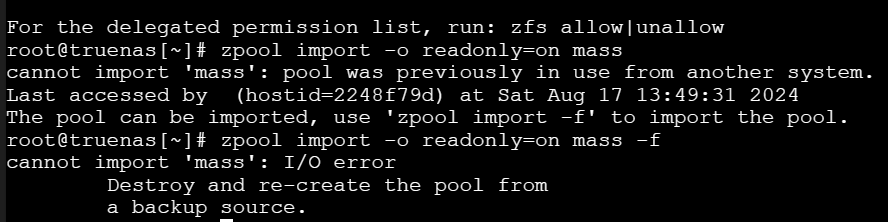
General approach we have recommended previously is to try importing the pool read-only, since it does not require space map access, evacuate the data and recreate the pool.
I pointed out earlier if I go through the process listed above it gives me the issue, it is why you advised me to mount it read only…
I have already mounted the zpool through command line as read only as you had advised, and as per the CLI it is already mounted and there. But I am unable to see it under pools or know how to access it to pull the data off.
When I go through the add pools section it only shows my other volume as it sees the other one is already there. That is why I am asking how do I access a mounted Read Only volume that was added through CLI.
Not sure… I’ve never had the problem. Perhaps someone else has?
You might try exporting via CLI and then reimporting via webui now that the pool is OK.
Otherwise, it’s use cli tools.
Currently reviewing some reddit thread seems someone else had the same issue.
I am curious though since none of the drives left an error in Truenas and all of them report healthy but the array dead. What on earth would have caused this!??! Like what would cause ZFS to just be like Nah mate I had a good life see ya and then die like this?!?
So I did some poking around reddit and found out how to access it
I will be writing this next part a bit weird just so others who face this issue can find this through google and save them some headache.
If you suddenly have TrueNAS enter a bootloop due to a panic over the Space Map read below
The issue from my analysis was caused by an overheating HBA card, the overheating of the HBA caused the space map to corrupt. The fix is active cooling for the HBA, so just a PC fan attached to the HBA should suffice. It seems the HBA card when it is overheating can write bad metadata resulting in this issue, its a known issue as per others I found on reddit.
To mount your drive read only zpool import -o readonly=on (ARRAY NAME HERE) -f
if you cannot find the name of your array run zpool import
This will give you the name of your arrays, either use its name or its ID. The ID is a huge pile of numbers.
Now doing it over CLI mounts it differently than through the GUI. For some reason it won’t mount under /mnt, but instead it just drops it in the root directory. So just use the console cd / then ls and boom it will be right there under the name of the pool.
From there you need to do the recovery over CLI. I just plugged in a 4TB external HDD, made it a pool and then started using Rsync to pull all data since my most recent backup.
From my research I cannot for the life of me find any way to recover this and looking through github this is a long known problem with ZFS. Sadly the OpenZFS devs refuse to acknowledge and refuse to fix the issue. So if you came here looking for a way to fix this and get the array back up… I hate to break it to you but you are SOL, the ZFS devs don’t care, this is just a risk of using ZFS
let this be a reminder
ZFS AND RAID ARE NOT BACKUPS STILL RUN BACKUPS
P.S
My comments on the devs are NOT to the truenas devs or ixsystems, they both do an excellent job. My comments are to the devs who maintains OpenZFS it self.
When bad data is written (e.g non-ECC RAM), its very hard for a file system to cover these issue. Its difficult to test and there’s always a possibility of 2 or more corruptions. The solution is well-behaving hardware. Its OK not to write data, but don’t corrupt it.
The ZFS advantage is no overwrites of data… so it can often be recovered.
Thanks for taking the time to raise our awareness of a problem. Please define what is “the long-known ZFS problem” that the deva refuse to acknowledge or fix so that we can understand the matter.