I am following instruction to do burn-in of disks. tmux session with 3 panes doing ‘badblocks’ commands for sda sdb sdc
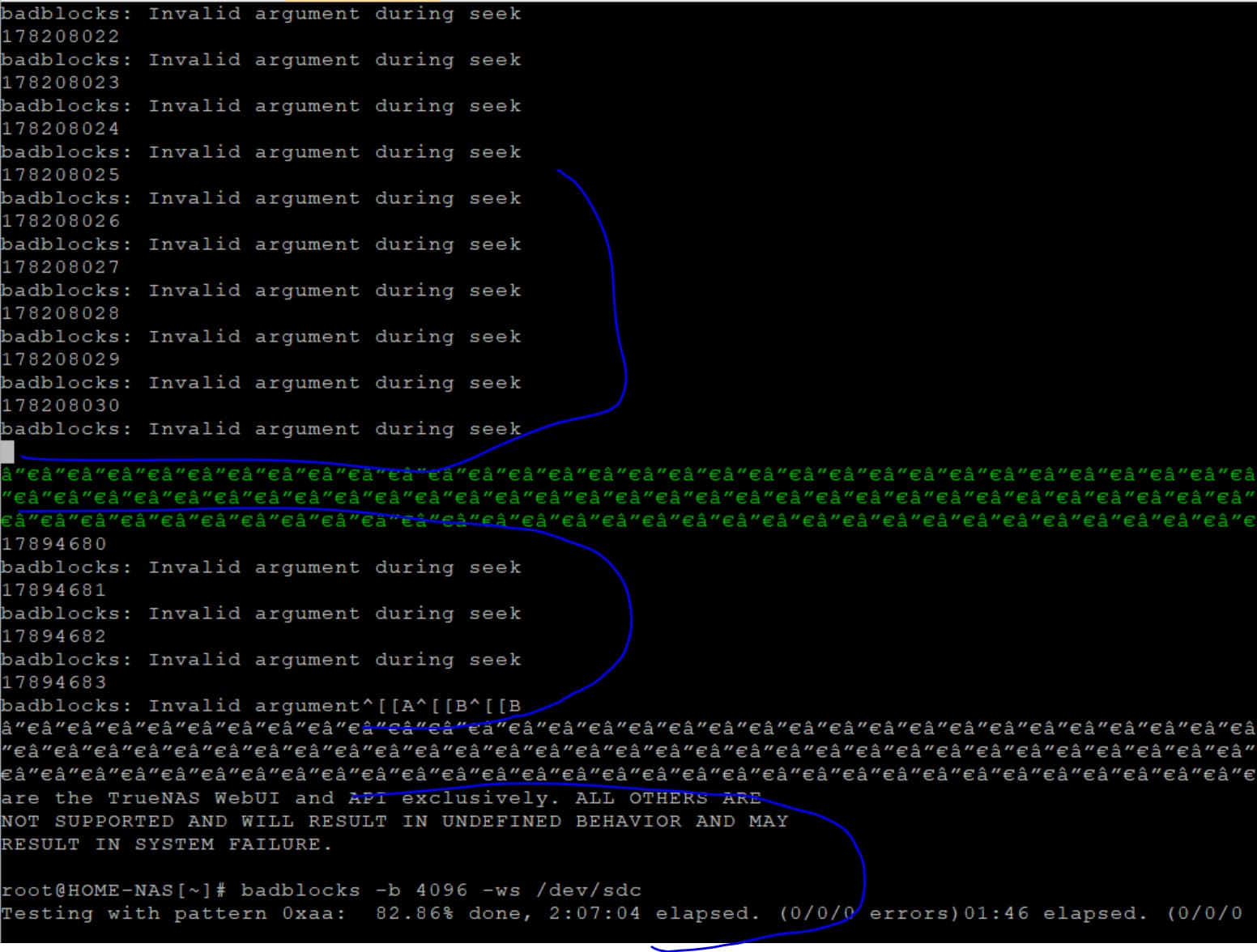
One of the disks started produce errors and I am not sure how to make sense of what is going on right now.
Only 3rd pane shows correct “process” %. First 2 panes filled with those errors and I can’t see progress or understand if it’s for sda or sdb.
Maybe advice on correct SSH client so I get better formatting (split line, etc). It’s on Windows.
I can move cursor between panes by using Ctrl-B and up/down arrows but that doesn’t reveal any progress. Just trying to understand what is going on right now…
Ok. Some background.
YES, it’s WD REDs 4TB drives. WD40EFRX purchased 2015. They were used part-time in RAIDZ mirror with no problem. All SMART tests look good.
I bought 4 more of the same (WD40EFPX) just now. And did go through SMART/badblocks for those.
Idea is to build RAIDZ2 with 6 drives (4 new and reuse old)
“Exported”/disconnected pool (after taking backups somewhere else)
Ran destructive badblocks on both of those old drives: badblocks -b 4096 -ws /dev/sdj
I have hard time believing that both of those drives which were working perfectly now bad for some reason. Yet they go shortly (after a minute or so of badblocks) into loop of
badblocks: Invalid argument during seek
46141370
badblocks: Invalid argument during seek
46141371
badblocks: Invalid argument during seek
46141372
badblocks: Invalid argument during seek
And when they get to end something else interesting happens.
TrueNAS “freaks out” and changes letters for those drives.
They were sda/sdb, then they became sdg/sdj, and then they changed again.
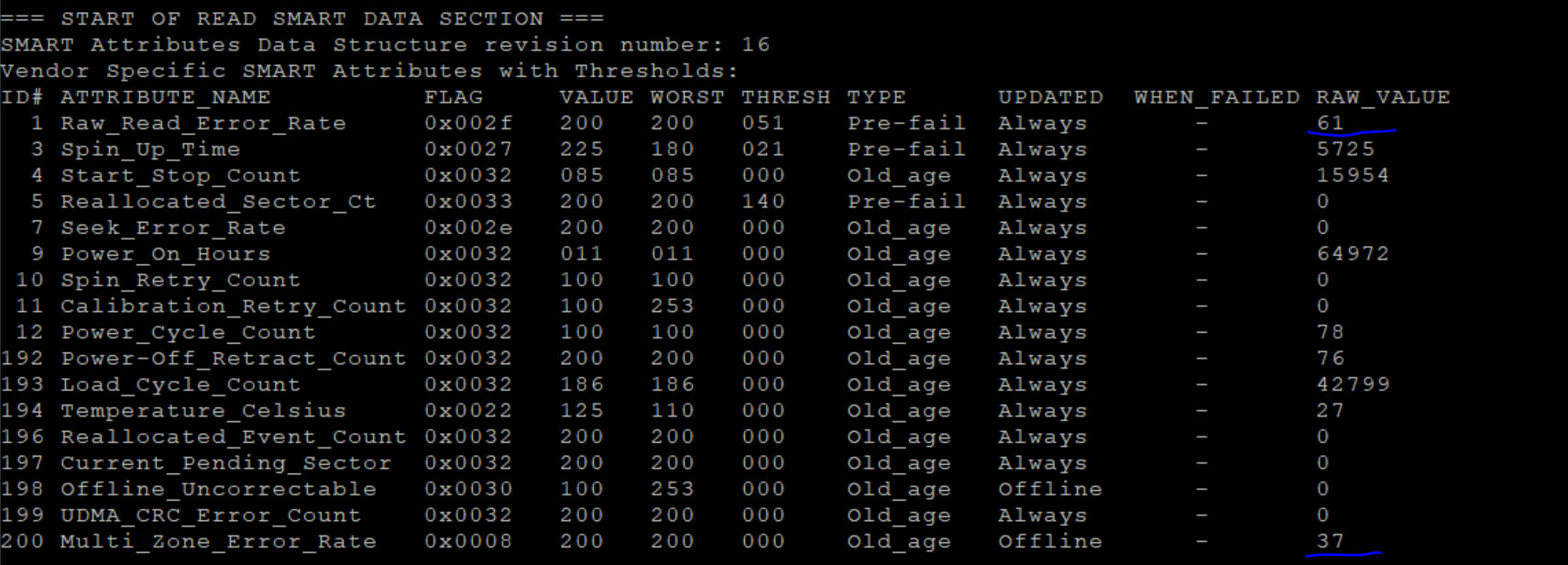
I feel like it’s something to do with zfs being on disks prior to this? SMART tests look good. There is couple questionable entries, but according to my research it’s OK
The only other “test” is just old 1TB drive I had and it’s almost done. 4 new drives tested OK (took like 50hr)
Old drives also “NAS” and according to table CMR. And from my memory (been awhile) they did burn in just fine. And SMART tests have some questionable items but OK.
Very very strange how they behave. And there was no issues with data, no issues with SCRUB tests. Weird.
Unbelievable. How? Both disks. I ran smart test on both of those disks, they failed and this is what I see for them:
How is it even possible? I guess data was stored in “good parts” and when I ran badbocks it triggered those and Smart test found it? But prior to badblocks smart test was good, does it make sense?