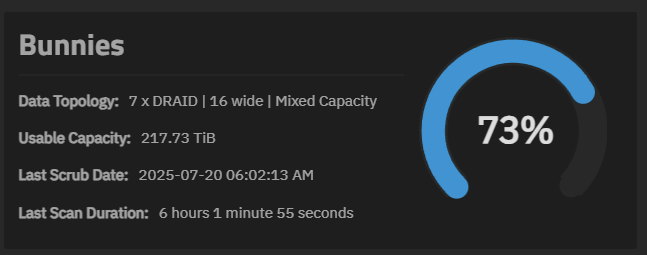
Sadly, the pool size I’m seeing is not lining up with what’s in TrueNAS. I thought maybe because TrueNAS was reporting 80% less space, but that doesn’t seem to be the case.
But that doesn’t make sense. I have 2 x 2TB and 5 x 4TB vdevs made up of 112 SSDs all with dRAID2:5d:16c:1s. That means the 112 drives are split into 7 vdevs where the capacities of all drives are the same. 32 x 2TB and 80 x 4TB.
Using that calculator:
2TB x 16 drives (1 vdev) = 19.057 TiB
4TB x 16 drives (1 vdev) = 38.239 TiB
With some multiplication, that’s ~230 TiB.
So where did my extra 13 TiB go?
I thought maybe it’s slop or something else, but lookie here, I’m already accounting for slop:
Looking at this deeper, even the calculation of drive capacity is wrong in the CLI.
For the 10TB HDD pool, that’s 9.1 TiB x 60. It should come out to 546 TiB. But zpool list is reporting 511 TiB. That means the total usable capacity is already wrong from the get-go.
I know ZFS has some overhead and slop, but slop is now limited to 128GiB (negligible in this pool), meaning the overhead is in tens of terabytes. Something about that seems very wrong: almost 600 GiB per drive in this pool. That’s over 6% of the drive!
zpool stats are accurate because they are based on actual blocks, zfs stats are estimates because they are based NOT on actual disk space used / free but on estimates of useable space after deducting parity. (They have to be estimates because of … compression, small blocks with larger parity ratios etc. etc.)
The UI widget is based on ZFS stats rather than zpool stats.
If you set the recordsize dropdown back to 128K, it should fix the issue. I need to add a note to the calculation – ZFS always uses 128K records when calculating capacity in zfs list. By changing the recordsize dropdown on the calculator, you can estimate how much you can actually store despite what zfs list shows you.
Thanks for the reply @jro! You’ve provided great tools!
My datasets are all 1M, and I changed that in the calculator too. Does that mean the calculator is already showing me the correct total capacity, not ZFS?
TrueNAS is reporting 73% used for one pool. Is that against the 128K record size then? Is it possible could TrueNAS calculate against the average dataset record size? Or is the percentage calculation already taking that into account?
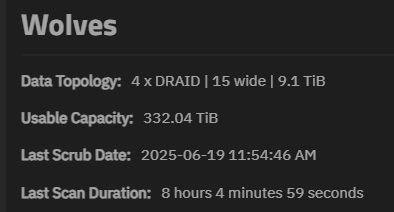
Yep, basically. If you write all 1MiB records, you’ll be able to fit 357.98TiB of data on your pool. If you write all 128KiB records, you’ll be able to fit 332.04TiB of data. ZFS just assumes you’ll be writing 128KiB records.
The used percent will be against actual usage, so if you’ve got all 1MiB records, that 73% represents 357.98 TiB * .73 = 261.33 TiB of data. If your USED column in zfs list is different than that number, your average block size is probably a little off 1MiB.
The calculator assumes your 4TB disks are exactly 4,000,000,000,000 bytes. If the primary partition of those disks is a bit off, the results will be a bit off. You can enter custom disk sizes to get more accurate (but only in TB units).
dRAID does a full width stripe for all data. This means if a stripe is exactly 1MB, but data is 1.1MB, 2 stripes are used. As far as I know, nothing else can use the remaining 0.9MB of the second stripe. This is simply how dRAID works, as far as I know. (Correct me if I am wrong, please.)
RAID-Zx can do variable width stripes. This is helpful for writing Metadata for files and directories, where it does not need the full width available. Not sure how dRAID handles that specific case.
Another issue with dRAID, is small files. Now the original poster, @Sawtaytoes mentions 1MB blocks, so small files might not be relevant. But, just to be complete, a small file that is much smaller than a dRAID stripe, wastes all the extra space.
My take on what dRAID pools can be helpful for, are large files, that exceed the stripe size by a factor of 3 or more. If using something smaller than 3 stripes, files could end up wasting space disproportionately to the used space.
Or, a dRAID pool could use a Special Allocation Class vDev, (aka Metadata vDev), for both Metadata and small files.
While the integrated hot spare is a nice feature, the issues with dRAID can out weigh the benefits for some applications.
I also believe these to be true (based only on what some other expert said rather than personal knowledge).
My understanding is that it is only really applicable for very large pools of several tens or hundreds of drives, and lose a lot of the flexibilities to do RAIDZ expansion or add a new small vDev as well as it having a lower storage efficiency.
The (IMO very small) advantage of a dRaid hot spare (over and above an ordinary hot spare) is that it can (somehow) reduce the resilvering time.
However, resilvering should be a rare event, and so what I would (perhaps naively) want to use it for would be to increase the normal RAIDZ resilvering time (by having much wider vDevs) and then bring it back to normal using dRAID.
So (again naively) I see dRAID as allowing e.g. to have (say) 4x 22-wide dRAID2 pseudo vDevs and instead of 8x 12-wide RAIDZ2 saving a few drives worth of disk space.
With the right sort of data - lets say a large scale media server for a streaming TV service - the downsides would be small, and the potential upsides significant.
But for most users here, I suspect that the downsides of dRAID are more than outweighed by the upsides of RAIDZ.
Yes, the re-silvering time for dRAID is something that can be hard to explain. But I will try.
To sum up the integrated spare of dRAID, is that the spare(s) is / are part of the data vDev. The spare(s) are actually virtual, and the amount of spares is actually spare space spread across all the columns in a dRAID vDev.
To re-silver a failed disk, causes dRAID to read from multiple sources and write to multiple destinations at the same time. Since there is no single target disk, like a spare or replacement disk in RAID-Zx, (or Mirroring for that matter), the writes happen much quicker. This restores redundancy noticeably faster than RAID-Zx or Mirroring in the ZFS context.
Whence a replacement disk is available for dRAID, the actual replacement takes the normal time because it is a single write target. But, of course, redundancy is preserved due to the spare space still being used until replaced by the replacement disk.
This final replacement is somewhat similar to the “replace in place” for a non-failed disk in ZFS for RAID-Zx or Mirroring vDevs. The “replace in place” allows a vDev to maintain all the redundancy it can, while re-silvering. dRAID simply takes that to a different level.
Agreed.
In the original posters case, it appears he understands the use case. My main comment was space utilization could be skewed because of the full width stripe writes.