I was there, Gandalf, 3000 years ago.
4 Likes
According to their docs you can pick any convenient time after upgrading for the conversion. A mixture of existing and newly installed apps will probably break things if you don’t do it.
1 Like
Every time I upgrade I lose my web GUI access .
Just dared to do the switch to Dragonfish.
So far everything works. GUI works. GPU passthrough works with both win10 VMs.
![]()
4 Likes
Updated 2 systems. One old supermicro server was on the latest Cobia with no special setup other than filemanager app. Upgrade went fine and app is working fine.
Other system was on latest Bluefin with both Tailscale and filemanager. The upgrade path for Bluefin is a two part upgrade (Bluefin–>Cobia–>Dragonfish) The two part upgrade went fine for both parts and both apps are working fine.
1 Like
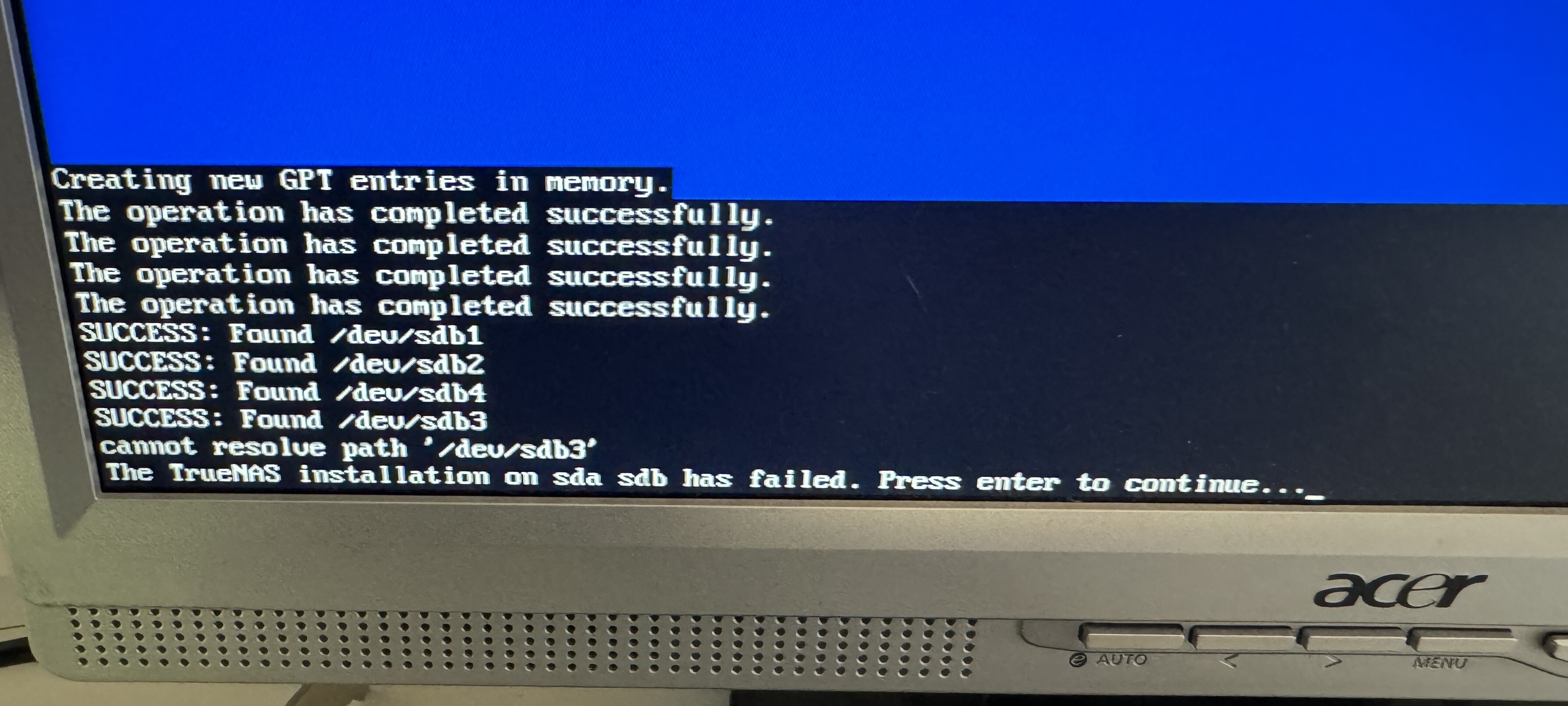
Did a fresh clean install yesterday for my brand new build. I tried to get it to do a mirrored boot drive and it failed with the same error with multiple different drives and ports. It would do an install with just a single drive.
I agree with winnielinnie that it’s actually a fair point about the UUIDs but @amtriorix; dude, chill out, this is not the way to interact with people, certainly not here. Would you ask for your coffee at Starbucks in this tone?
1 Like
… @kris I admire your patience and your calm in equal amounts in dealing with @amtriorix ![]() … Please remember everyone else fully appreciates what you guys are doing and have achieved.
… Please remember everyone else fully appreciates what you guys are doing and have achieved.
1 Like
I actually thought internally Truenas used drive serial numbers to keep track of drives. Just because lsblk or whatever program lists them as sd** means nothing other than at the point of running the command that was what the system ordered the drives as.
I was taught long ago to never trust drive labels especially under Unix/Linux/FreeBSD as they can change and will cause grief.
I have never had an issue of willy-nilly shoving drives into a chassis with truenas. Some other systems want or require drives remain in the same space order. On one system my boot drives are listed as sdd and sdf shoved into the second backplane on the rear of a 36 drive chassis, not sda and sdb as they origionally were labeled. On the other system boot drives are listed as sdq and sdr. Both of these machines were initially setup with only the two drives I wished to use as boot drives. Only after fully populating the backplanes did the order of the Name labels change after reboots.
I believe somewhere in the docs or old forum I remember reading that Truenas tracks drives by serial number. There is nothing wrong with that. If you use cheap usb sticks and/or cheap m.2 cards that don’t pass a valid serial number or clone the same serial number for all drives/sticks you will have issues as Truenas can’t tell drives apart.
Internally it does. But when it creates a pool, it uses partition UUIDs, which you can tell by running zpool status at the shell–except for the boot pool, where it uses things like sda3 or ada0 (depending on whether it’s SCALE/Linux or CORE/FreeBSD). The troll wasn’t wrong in saying that, at least in the abstract, it’d be good to use UUIDs for the boot pool as well–but was grossly overstating the importance of this in the TrueNAS context.
Okay, I understand better now I think. It’s something I should read more about as an excuse to not do something else. I’m in the camp of it it ain’t broke…
After updating from TrueNAS-SCALE-23.10.2 → TrueNAS-SCALE-24.04.0, all settings and raid/datasets were saved fine.
But after ~10 minutes the system simply becomes unavailable, everything falls including GUI / SSH / Samba (mostly unreachable).
In the top containerd-shim processes, in the console after the message:
systemd-journald [570]: Data hash table of /var/log/journal/4a0a90eb98a64204a674bf9a927ff78e/system. journal has a fill level at 75.0 (8536 of 11377 items, 6553600 file size, 767 bytes per hash table suggestion rotation
Systemd=joumnald (579]: /var/Log/journal/4a6a9ecb98a642848674bf989274478e/systemdjournal: Journal header limits reached or header out-of-date, rotating.
Clearing the journal doesn’t help.
Before this, all upgrades after TrueNAS-SCALE-22.12.4.2 were painless. Rolled back to Cobia, everything works perfect.
This mainly went OK for me, apart from Frigate which failed the migration and I had to manually reinstall.
I updated and also migrated a number of Truechart apps based on their documention.
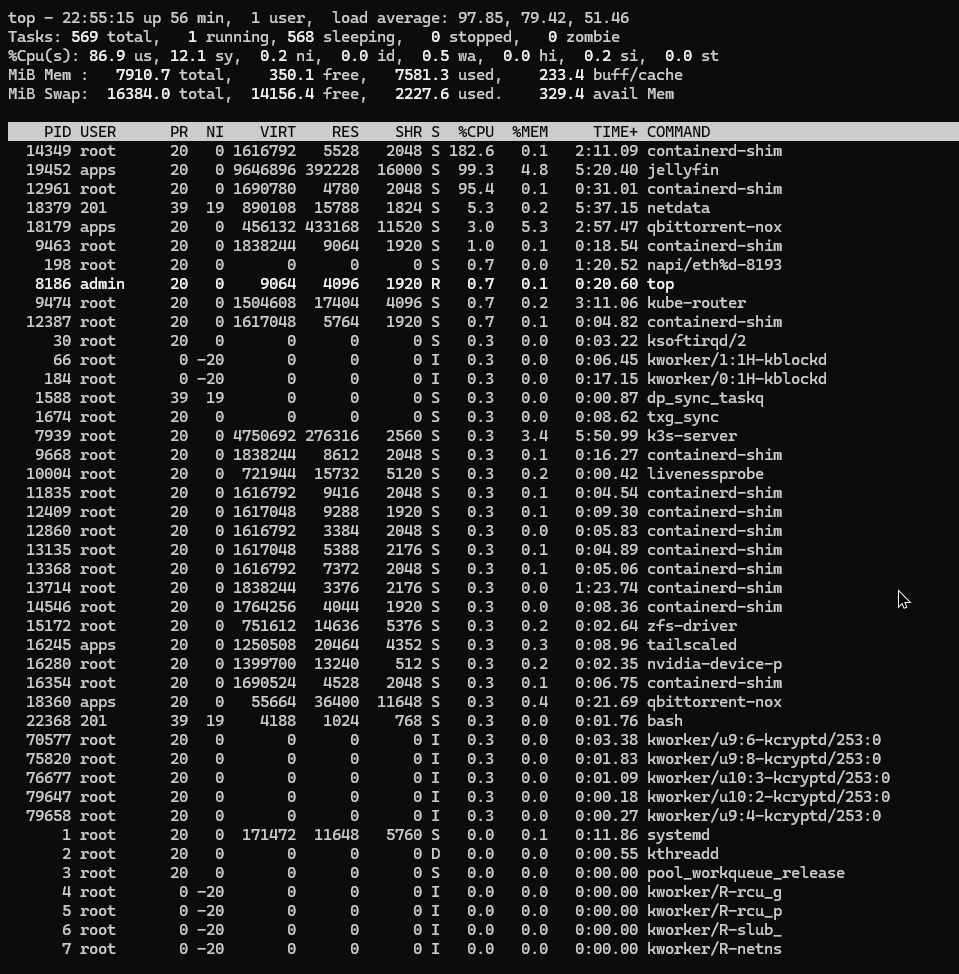
It seems to mostly work so far, but I am seeing much higher CPU utilization than before. Even if the apps are all idle.
If I look at top, then its mostly these processes consuming CPU cycles:
- asset-syncer
- k3s-server
- python3
- middlewared
That is troublesome. We’ve had a few similar tickets from other users as well. Can you tell us how you run TrueNAS? Is it bare metal or virtual and what kind of setup? We’re trying to see if there some commonality between these incidents.
@kris, it’s old bare metal:
- Intel® Core™2 Quad CPU Q9500 @ 2.83GHz
- North Bridge: Intel® G41 Chipset
- South Bridge: Intel® ICH7
- // GIGA-BYTE GA-G41M-Combo (rev. 1.4) systemboard
- DDR3 1333 RAM
I can share debug.tgz if it helps (done immediately after reboot, when the system was stable)
Kris, I don’t know if this is what’s going on with this user, but I’ve seen a number of reports of Dragonfish exhausting RAM, presumably due to (or related to) the ARC changes in that version. The symptoms described in those reports are similar to what @vadym mentions.
1 Like
A trip down memory lane.
![]()
If I could go back and edit the post, I would have bolded and underlined the word “if” in my last sentence. ![]()
1 Like
Just to confirm what my eyes are seeing on your screenshot earlier, 8GB of RAM in total?