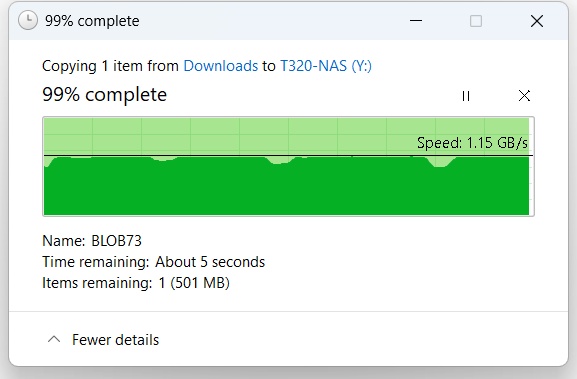
Truenas Scale 24.10.2 on a Dell T320 with a Xeon E5-2470 v2 cpu 96gb memory. 8 4tb seagate 7.2k hdd in 4 mirrored vdevs 1tb nvme log cache (3200mb/s tested in windows on same machine). 10gb/e.
iperf3 is 9.8gb to workstation.
SMB Copying a 72GB file from the workstation to the NAS it starts out at 1,100MB/s (windows explorer copy). After 8 seconds it drops to 450-500MB/s where it bounces around until the transfer completes.
Copying same file from NAS to workstation I get 700MB/s
Crystaldiskmark r/w at 32gb is 1,232MB/s Read, 873MB/s Write.
I’m trying to achieve sustained 1,000/MB/s read or write.
Right now hdd’s are on a 6gb/s controller. They are 12/gb/s SAS drives so I have a 12G SAS backplane, and hba controller coming to speed things up.
When I build the pool as 8 striped drives I achieve the 1,000MB/s upload so I’m thinking it’s something to do with the pool. Seems like my hardware should be beefy enough. I put in a bunch of tuning parameters thinking it would speed things up, but no real change.
For this test you shouldn’t be doing any synchronous writes so the NVMe SLOG will be doing nothing.
The start of writes at 1100MB/s = c. 10Gb and then a drop off is a reflection of asynchronous writes where you start transferring at network speeds until the maximum amount of writes is cached in the NAS memory and then it slows down to disk speeds because you can only send data over the network as fast as memory is freed by writing to disk.
So it looks like you have a disk bottleneck.
With 4x mirrors, you effectively have the write capacity of 4 drives (because each block data is written to both drives in the mirror and you can only write 4 blocks simultaneously), which should give you a sustained write speed of a maximum of 800MB/s-1GB/s. (When you stripe you get double the total sustained write speed because you can write 8 blocks simultaneously.)
You have not stated exactly what Seagate drive models you are using? Are they Exos 7E10 or something else?
According to the spec sheet Exos 7E10 4TB drives have a sustained access speed of 215MB/s, so your system has a maximum sustained access speed of 860MB/s. However I should stress that this assumes zero head seeks, and in real life you may never see this level of performance because head seeks are an essential part of disk access.
Since at present each disk has a 6Gb SATA channel (which is c. 5x the sustained access speed), it is unclear whether a switch to 12Gb SAS connections will speed things up. However a switch from the MB SATA ports to an HBA may help if the MB SATA ports have some sort of bottleneck.
So, we have two results from this:
You will never achieve 1,000MB/s sustained writes to 4x mirrors, but you might achieve it with a 8x RAIDZ2 which should give you write speeds of 6x drives rather than 4x. (It is a common misbelief that mirrors are faster than RAIDZ - and this is true when your measure is IOPS because you are doing small random reads and synchronous writes for zVolumes/iSCSI/virtual disks and databases - but for sequential access to largely inactive files, RAIDZ performs very well and with less redundancy overhead so less cost per TB.)
A real-life SMB sustained write speed of 450-500MB/s seems to be on the low side, but it is not clear whether this is simply due to seeks, or due to SMB overheads, or ZFS TXG overheads or some hardware bottleneck.
HDD’s are ST4000NM0034 SEAGATE 4TB 7.2K 12G LFF 3.5" SAS 512E ENTERPRISE HARD DRIVE
When transferring large files (73gb test file). I get what I would call chugging, where every few seconds I see writes and head seeks to all drives. I’m assuming that I’m filling a cache and then the slow-down occurs because of the seeking and slower HDD’s. Was thinking there were some tuning parameters that could improve this especially since I have 96gb system memory. No vm’s or other things, all NAS.
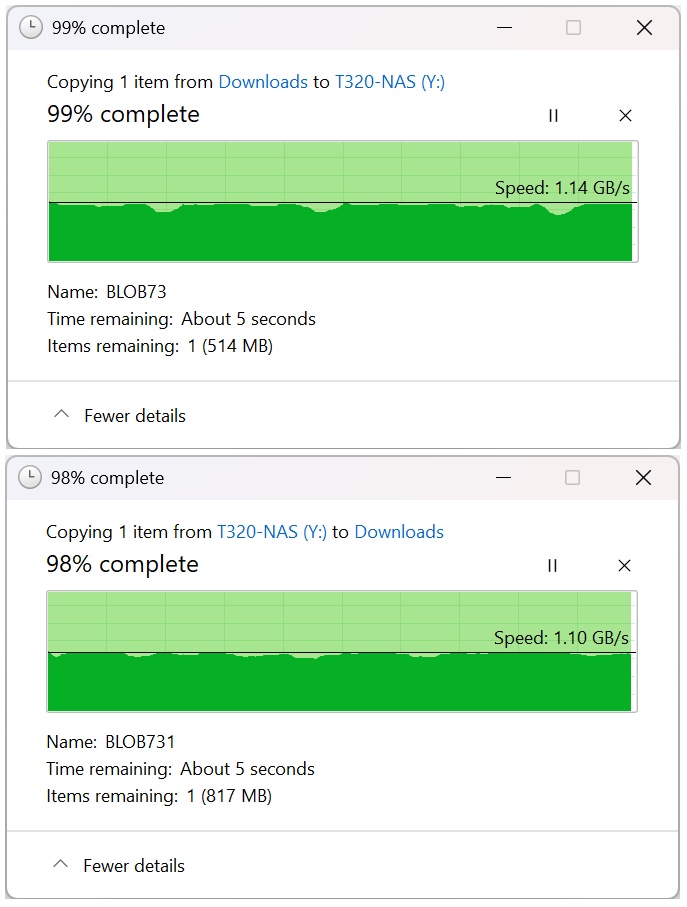
As a test i removed the nvme ssd from the pool and made a new pool with just the ssd. Transfer rates in both directions are 1.14GB/s. If i remember correctly if i set the HDD’s up in a single stripped pool I was getting 1GB+ rates. Can’t remember if it was both directions or not.
What you are seeing are ZFS Transaction Groups (TXGs) which are by default every 5s.
If write throughput is genuinely important to you in real life (regardless of the consequences elsewhere) then this period is tuneable to a smaller or larger number of seconds. It is (I believe) a system-wide ZFS parameter that you can update real-time by doing an echo of the new value to /sys/something.
For the purposes of the benchmark you can do a cat /sys/something to get the current value and you can set it, do a benchmark, and then reset it to see if it makes a difference to your benchmark workload. But these values are generally a tradeoff so by changing it to e.g. improve a benchmark you are likely going to be making something else worse (e.g. fragmentation, seeks) elsewhere.
Seems there’s no network issue – you’re fully saturating 10Gb whenever the disks aren’t a bottleneck. So we can rule out the network I reckon.
I have half the disks but an otherwise similar setup: mirror vdevs. Sustained sequential throughput from my drives is 152+185+181+212MB/s for a total of 730MB/s. Identical numbers from dd and fio. I can benchmark the drives individually or all four together with identical results. Suggesting there’s no controller bottleneck.
You might want to undertake a similar exercise. Bench each drive one at a time then all eight simultaneous and see if the numbers add up. If this checks then I reckon we can rule out the controller (or the PCIe slot it’s in).
Now, all that said I don’t think 1000MB/s is going to happen.
You have eight drives but every block gets written twice (one copy onto each side of the mirrors) which doubles the amount of data being written. So the theoretical max write speed would be the sum of four drives. 4x 215MB/s = 860MB/s. We’re 140MB/s short of the goal and I reckon highly compressible data would be the only possible workaround for this.
How large are the writes? If you’re sending perhaps 10-15GB at a time we could turn some knobs and possibly get the ARC cache to swallow the entire thing in one go. Then the data would be written to the drives in the background.
I’m thinking zfs_dirty_data_max, zfs_dirty_data_max_max, and zfs_txg_timeout are the relevant knobs. All three come out of the box with rookie numbers and you know the story with those.
Your last paragraph was exactly how I spent my evening. Hadn’t even read your message yet. I put the following into init/shutdown scripts and was able to transfer my 74gb file without dipping below 1gb/s. When I transferred my 175gb file it went about 80%, dropped way down (20-30mb/s) for a little bit then back up over 1gb. Took the slog drive out alltogether, disable sync alltogether and enabled write cache on the HDD’s. I know, data loss…
Now, I don’t know if I want to live with these settings in a production environment, but it shows it can be done. A reliable UPS with auto shutdown would be bare minimum in such an environment.
One issue. When I cat’d the two dirty_data entries the first one showed the number I put in the init. The second one only showed 48gb. Can someone explain that?
Are you working with a T320? If so, you have to be careful about what slots you are using.
I think I used 3 for the disk controller, 4 for my 10gb nic and 6 for my nvme ssd. Slot one is handicapped. A week or so ago, I dug into a Dell document that told me 3,4 & 6 are teh best slots to use. I’m fairly sure of that info, but please double check that info. It’s late. just looked in the box. It’s slot 3, 4 & 6 like I said above. There was something about slot 1 & 2 that steered me away. Can’t remember.
I think this one has to be in-place prior to pool import and I don’t know if TrueNAS pre-init qualifies. I don’t remember it working. So I applied it to the kernel command line at boot. On SCALE I invoked the middleware thusly:
My server has a generic B660 motherboard and a low-end Alder Lake proc. The on-board SATA has been fine. The only snag I’ve hit is my 2x 25Gb NIC being PCI 3.0. Running this in the 4x slot translates to ~3200MB/s max and no amount of knob-twisting ever made it go one tick faster. So I can either throw away ~35% of my total network bandwidth or else use the x16 slot which means no GPU. PCIe connectivity was superior several processor generations back vs. today.
At what speed can you read that data back? I found some tunables that helped with reads but I don’t know if they’d translate as I have mismatched drives in the pool (three different models in a pool of four).
What are you using the GPU for? Possible it would be fine with x4 lanes.
And yes, with the switch to NVME storage, the amount of lanes available for everything else has plummeted. Went with a more expensive, but lane/slot flexible, board for my new 9800x3d gaming rig. That way I can hand it down to my NAS in a few years and still use my HBA/dual10GNIC/GPU. 5.0x16. 4.0x4 and 4.0x2 lanes for the 16x slots FTW!
AI nonsense. It’d work in 4x slot if I could work out how to make it fit. It’s a typical two-slot GPU and the board’s 4x slot is at the very bottom so the GPU’s heatsink/shroud/fans collide with the MB’s header garden. And probably the case itself.
Not needing access to the video ports means I could get creative but I haven’t landed on anything yet.
My desktop is similar. The 2x 25Gb LAN card uses a chipset-connected 4x port (i.e. the same 3200MB/s limitation) with a bonus “no SR-IOV allowed” for lack of ACS in said chipset. I could move it one of the two CPU-connected x8 slots (unusual motherboard) but then I’m back to same problem of somehow stuffing a GPU into poorly-situated x4 slot.
My plan will be to get one of the single slot intel arc/bm/c cards for transcoding. I should be able to put it wherever, since you can now buy pcie 4.0 x1 10gbe NICs. Using a MSI x670e tomahawk, 3 16x slots with x16/x4/x2 lanes (gen5/4/4).