Stux
May 14, 2024, 8:04am
21
dan:
But, of course, there’s always good old-fashioned process of elimination. You know the serials for the not-dead disks that are part of your pool, so whichever disk’s serial isn’t on that list is going to be the dead one. Tedious, but simple enough–and with only eight disks in the pool, not even that tedious. You could probably sort it out by some grepping in the kernel boot logs as well, but that’s definitely getting more fiddly.
I did this a couple of weeks back. Sort of sucked, used lsblk then physically crossed off each serial that was present in the array.
I had 4 simultaneous failures, (Physical issue) And the disk was dead, but couldn’t afford to accidentally replace the wrong drive.
Stux
May 14, 2024, 8:05am
22
And this was the problem. I pulled the wrong drive. And made my problems worse.
Stux
May 14, 2024, 8:23am
23
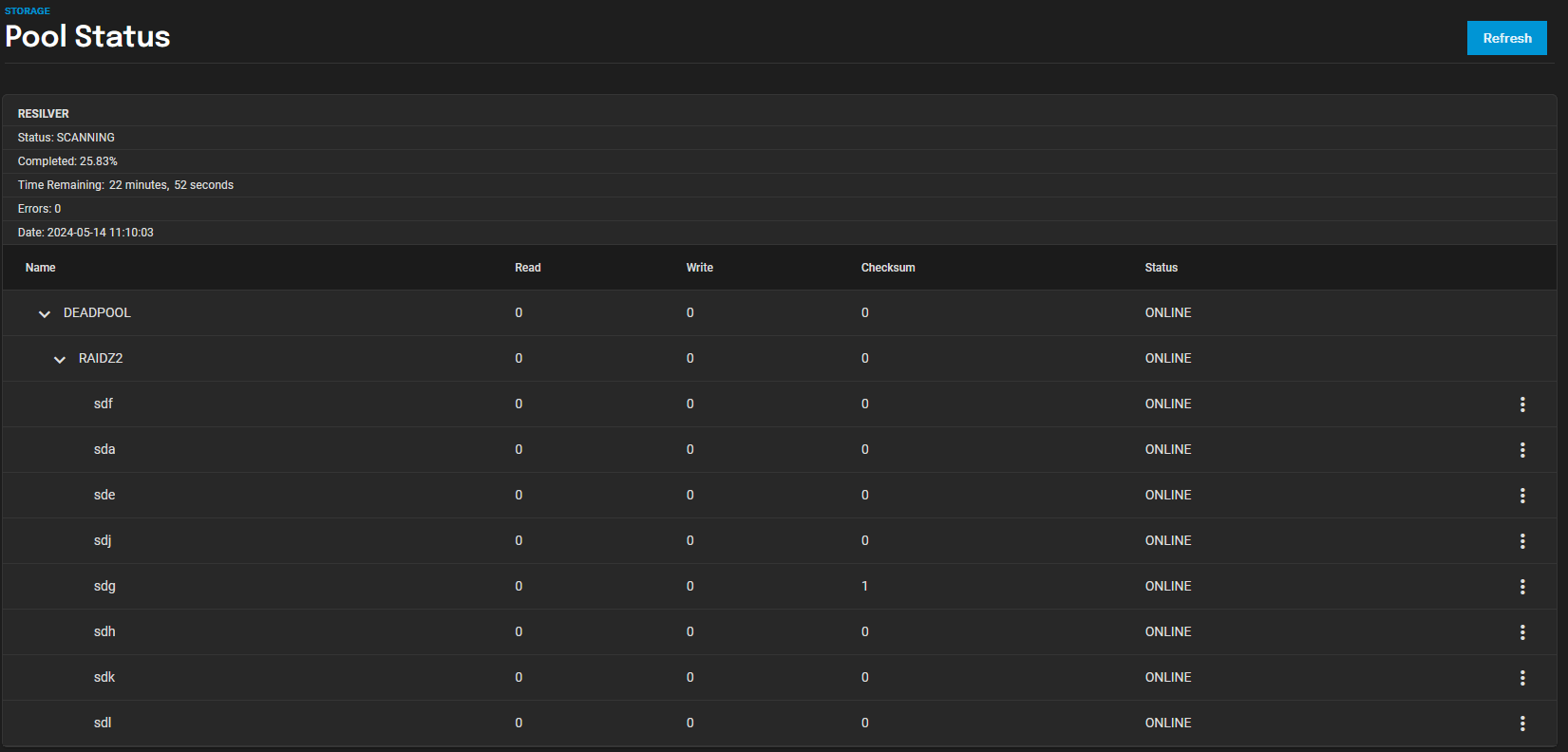
This would’ve saved me.
Instead it was something like “was /dev/sdd”, and helpfully provided a link to the disk info. With serial. Removed disk.
Guess what. It wasn’t sdd anymore. The actual disk that failed was removed and had a different unknown serial.
So then we had to eliminate all the others.
dan
May 14, 2024, 6:22pm
25
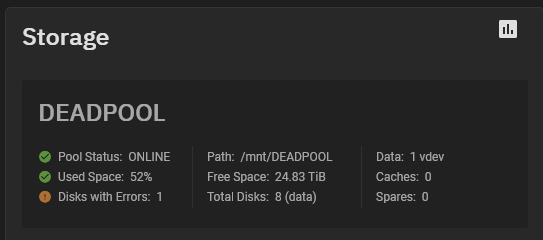
Gee, I don’t know. Which one does the pool status page say has an error? It’s right there in front of you. Hint: Is there something about sdg that’s different than the others?
emsicz
May 14, 2024, 6:36pm
26
All I see is a drive that has 1 checksum. I don’t know what that is or how to act on this. Nothing even says those are errors. Sorry I forgot my crystal ball at home. I don’t know if there is anything wrong with the drive, because I have no idea what drive it is. I have 9 drives in there. No idea which is which.
pmh
May 14, 2024, 6:54pm
27
Point taken, you might want to create a JIRA issue about the column labels?
These are
read errors
write errors
checksum errors
respectively.
Stux
May 14, 2024, 7:07pm
28
Might be nice to hilite rows with errors somehow.
Maybe a
1 Like
DjP-iX
May 14, 2024, 7:22pm
29
You can click Manage Devices on the Storage > Topology widget for your pool to get a more readable output of read, write, and checksum errors.
I believe that particular Pool Status screen in your screenshot has been entirely replaced/removed in favor of the Storage dashboard in Dragonfish.