I’d like to preface this by saying it’s 4 AM where I’m at, I’ve mentioned this couple of times over the years and I keep being shut down by TrueNAS veterans, and I never understood why.
I have a failed drive(s) in TrueNAS Scale box. I think there is 9 physical disks in there. Some have recently failed.
-
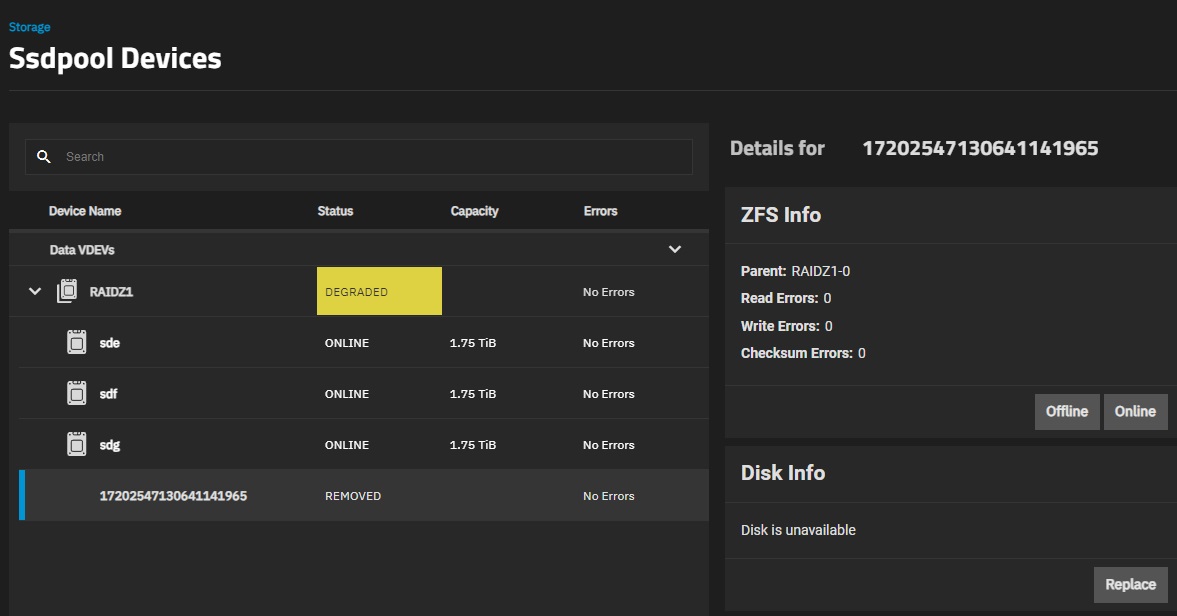
There is currently no view, where I’d see devices connected to the system and devices assigned to a pool, so I can clearly tell which devices were disconnected from the pool (for whatever reason) and replaced by hotspare unit. All I can see is a table that gives me list of some of the disks connected to the system with serial number and name. So I can see that drive unit with serial 1EGYE2LN is sdj and part of tank pool. No indication of what is broken, missing, replaced, spare, nothing. Just list of disks. The list is incomplete, there is more devices connected to the system than is visible in this table.
-
I have received email that says that device has failed and that the failure might be related to device known as sdi. Nothing in the GUI navigates me to this. The device table has no sdi device on any line, presumably because the disk is dead.
-
If I want to act on this, I have to go into shell (wtf) and type
zpool status, which shows me some incomprehensible list of guids, which is completely useless and I have nothing to do with it. But it does tell me there is a disk with statusUNAVAIL. I have no way to tell what serial number the disk is, tho.
I have this box backed up, so I’m giving this up and I’m going to bed. What I am asking is how is it possible, that a NAS software, after decades of development, does not have completely idiot-proof GUI to guide me through the one thing that I am expected to do over the life span of the NAS box? Why is this so hard to accomplish? Why does it just not tell me that unit with serial number of 1EH24DNN is failed and to click a fking button when I’m done replacing it? And the answers being given here are totally unusable also. What use is it to me that I have a physical note of what serial is where in the box? Why do veterans keep poking people with this remark? Yes I do have a damn sticky note that tells me where everything is, but what use is it to me when the damn TrueNAS can’t tell me which serial number is it that has gone bad? Why am I presented with completely impotent UI that keeps telling me weird useless crap that I either already know or have no way to act upon? What is the philosophy behing this approach? I can see with my own eyes there is 9 disk units up and connected in this box. The Disks table shows 7. The zpool status shows 7 with one unavailable. The Windows Storage Spaces is like the worst tool I’ve ever come across to manage data but when a disk fails, the process to replace it is incredibly convenient and transparent, they were able to nail this on first attempt.