Hey guys, first some system details:
OS version: ElectricEel-24.10.2
PC specs: i5 12600, ARKTEK B760 DDR4 AK-B760M EG mobo, 2xCorsair DDR4 16GB 3200 CL16, CoolerMaster Elite NEX 600W PN600 psu.
So, I’ve been experiencing random shutdowns of the system that did not previously happen. The weird thing is that the system is unreachable (seemingly off) but the fans of the case are still working like the system is still active, and if I plug an HDMI / mouse / keyboard the system won’t respond.
This last happened this morning and midnight. I returned home after seeing the system was unreachable (through Plex server being unavailable) and hard reset the system at approx. 23:50. Apparently the system shut down at around 00:20, according to cpu temp activity I checked before leaving for work. I hard reset the system again this morning at 06:50 after noticing it was again unreachable, and checked the cpu temp as I said, and when I got to work I browsed Overseerr for a bit and at 07:50 it was unreachable, meaning the system had shutdown somehow.
Does anyone have any idea what’s going on?
I did recently install Overseerr and Cloudflared (about when all this started).
update:
Moved the rig to my work room, and took out two drives that weren’t being used. So far almost 24h and not one problem. Will test those drives when I get a chance.
Hello! I have experienced similar issues. It’s a long story really, but want to keep it readable:
After installing a StorJ node on my TrueNAS Scale, I noticed how little by little the ARC gets filled up (I did not set any limits or swapping - it’s all raw, out of the box); Most of the time, it’s all good: always some 2.8, 2.9, 3.0 GB of RAM left free (out of 128 GB). Then, at random times, the system reboots! Out of the blue, with absolutely nothing useful to go with in the logs. It’s no power issue, cause it’s on UPS. My other TrueNAS Scale - different configuration but the same version with no StorJ node on it never had a problem.
I’m also thinking of setting a MAX for the ZFS Cache and exploring setting up a swap. But need to know more about it. I’ve run the system with default configuration for many months without a single issue. Why did it start now? After these random reboots, there doesn’t seem to be any issue with anything in the system: Apps, pools, data, etc. all seem to be in order.
Thank you.
PS: I’ll provide my full configuration if necessary… it’s quite a lot in there (6 way RAIDz2 16TB Iron Wolf PRO data pool, with 3 way MIRROR 1TB Crucial MX500 SSDs Metadata, 1 way 1TB WD Red SN700 NVMe L2ARC, 2 way MIRROR 16 GB SSD SLOG(ZIL) (provisioned); Separate Apps pool: 2 way MIRROR 500GB WD Red SN700 NVMe;128 GB non-ECC RAM, AMD Ryzen 7 5700G CPU (8 cores/16 threads)
Again: before StorJ, I had uptimes of 30 days+! 40, 50… I only rebooted when new updates had to be installed. Everything perfect!
Wow I’m also experiencing the same issue. At first, I thought it was bad memory, did a mem test and it passed. Then I thought it was my cheap Ebay 2.5gbe network card as I remember reading some network cards were causing crashes, but the system still shut down. Experiencing the same symptoms (the system is unreachable, but the fans of the case are still working). when downloading the de-bug reports nothing stands out to me within the parts I understand. Hoping my Reply will boost interest.
I recommend you both post your own threads, as what hardware you have provided shows that you have vastly different parts and possibly different underlying cause.
Be sure to include detailed descriptions on hardware, TrueNAS version and any events leading up to the shutdown.
So I guess I should give an update… I took out two drives that weren’t in an actively used pool (they threw some ZFS errors) and so far it’s been a week smooth sailing. I should test those drives thoroughly.
I’ve had similar random lock-ups and shut-downs on a setup that I’d cobbled together for testing purposes… SCALE 24.10.2
One instance was a very bad drive - I was testing a stockpile of drives that had been in a cupboard for a good few years, so that one wasn’t exactly a mystery.
But the others were thanks to a 32GB LR-DIMM, having happily done service for many years, suddenly deciding to start shifting off this mortal coil, and no longer play nice with the linear angry pixies it was
System was spectacularly unstable - crashing / hanging several times a day. Found that the DIMM happened to be in slot A1, meaning it filled up first with ARC data.
Error logs confirmed it. Changed it out, and all was well.
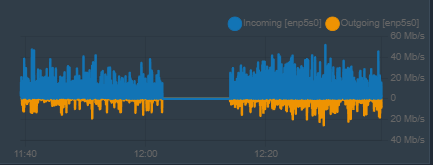
Well. I had more than one uneventful week since I posted this; meanwhile, I suspected this all has something to do with the ARC being filled up slowly by StorJ Node; And what I did was to start a VM when I noticed ARC was full - process that usually clears a good part of the ARC. But Today I let it be. And it so happened that I was right there, looking at the Dashboard when this occurred:
There is a gap of 13 minutes in network activity, including the reboot, which is roughly 2 - 3 minutes. Will try to look again at logs (last time it happened, and I checked, there was nothing!)
Maybe someone can corroborate this and help solve the mystery.
Thank you all.
I had a development on my end, too.
I took out the disks that were acting up, put them in my Windows machine and started testing them on HDSentinel. They both underwent a surface WRITE and an extensive self test successfully. So far so good. Put them back in the server, created a new pool and put 300GB of media on them. A day goes by and at 5 AM I get 8 email notifications from the server that the drives “failed to read SMART Attribute Data.”.
Now, I connected them both to a M.2 to 6xSATA controller I bought from AliExpress. I suspect foul play in this strategy. I have a PCIe x1 to 6xSATA controller coming so I will switch them around to see if this is actually the issue. Maybe the M.2 controller is having a hard time reading SMART attributes from the drives through this set up and is throwing a fit.
It’s weird because manual short SMART tests are running fine, and I am in the middle of running a SMART long test, we’ll see.