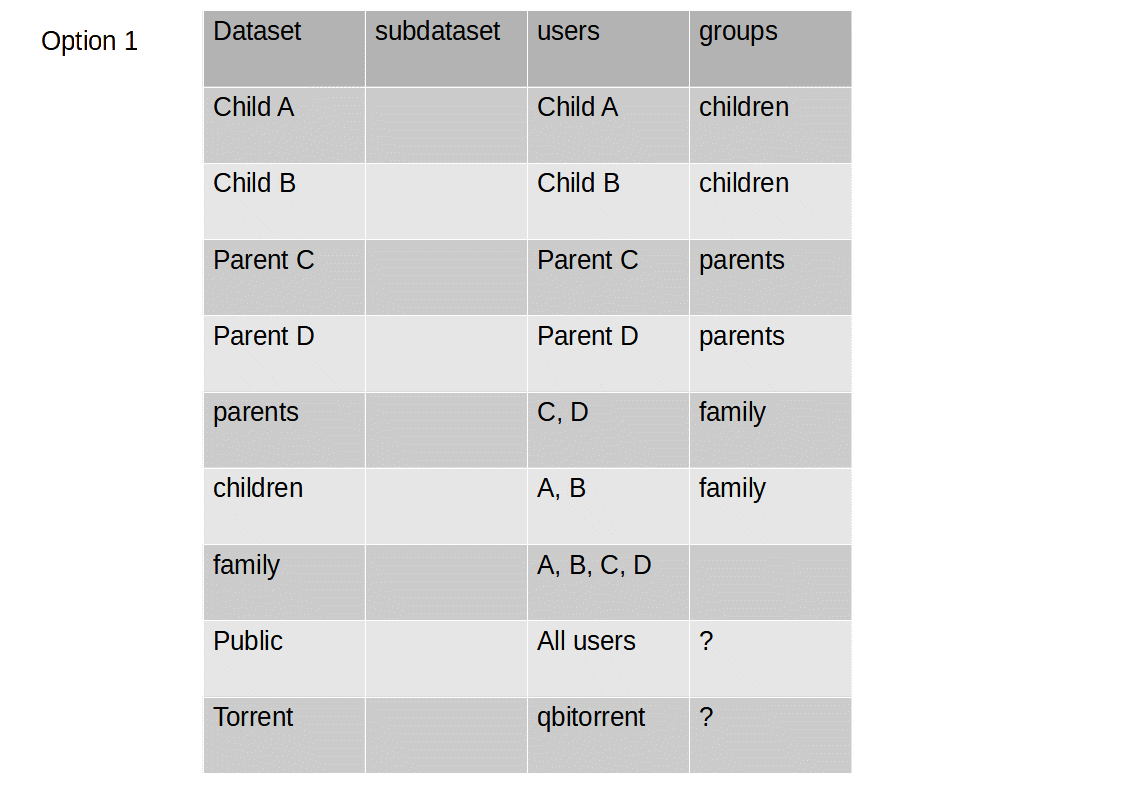
Hello all,
I’ve been posting a bit recently in this forum, and I had great help so far. Like I mentioned, I’m coming from a Synology DiskStation, and I’m trying to figure out the best way to implement Datasets, which is something that has no equivalent on Synology. The Storage Pool is equivalent to the Volumes, and shares are shares, but there is nothing that compares to datasets… So before jumping into it, I want to make sure I adopt the right strategy. My TrueNAS server will be for data sharing, sure, but also usage of apps from TrueNAS or TrueCharts.
1- I saw a video tutorial, can’t remember which one, but the person was suggesting to create a dataset specifically for apps storage, as it will be easily share with the apps group and may prevent issues. Makes sense to me, so I already plan one for this.
2- I think in the same video, it was suggested that when installing an app, to put the app configs on a different dataset than the one created for apps (ix-applications), arguing that transferring apps to a new system may be easier. I’m really not sure about that one.
3- On Synology, all users had a home folder. Not sure if I really need that, as I may change my storage strategy on TrueNAS, but still, if I decide to go that way, is there any concerns or suggestion on datasets?
4- also, if users don’t have home folders, and I SSH to the account, where are stored the default SSH keys and login scripts (.profile or such depending on the shell)?
So far, I was planning the following:
- A dataset for apps, with multiple folders as below:
- A Media folder, where I will put my videos and music
- A Picture folder for my images and photos
- I may or not dedicate a folder for apps preferences
- A second dataset for data archival
- Home folder will be here if I decide to do so
- I’ll probably create folders for each type or archival I want to do
In all of that, each folders will be a shared by itself, so it should be easy to manage access depending on the needs.
I’m sure I’ll get real good advise here again, so thank you for your help in advance.