![]() What do you think spare cells are in?
What do you think spare cells are in?
Early failure of some cells
Some dying cells are, in the warranty period, to fulfill the guaranteed promises.
From the start, there were no working cells
may be more
![]() What do you think spare cells are in?
What do you think spare cells are in?
Early failure of some cells
Some dying cells are, in the warranty period, to fulfill the guaranteed promises.
From the start, there were no working cells
may be more
Continuing the discussion from Unexpectedly high SSD-wear:
It would be interesting and really scientific to have a count of wearing or dying boot devices threads or posts here in the forum over the years. Can lead to action or to ‘forget it’.
I will stop for now, because it has to be more proactive.
Thank you all for the very informative and fruitful inputs to the discussion.
I think there may or may not be options to generally increase the lifetime of an SSD based on smart wear leveling, over provisioning, extra sectors or whatsoever.
As I was the one posting the question, I’d like to slightly direct it back to where it came from:
My main concern was - and still is: How can I reduce unnessecary writes by configuring TrueNAS and its services (currently mainly Kubernetes) in a smart way?
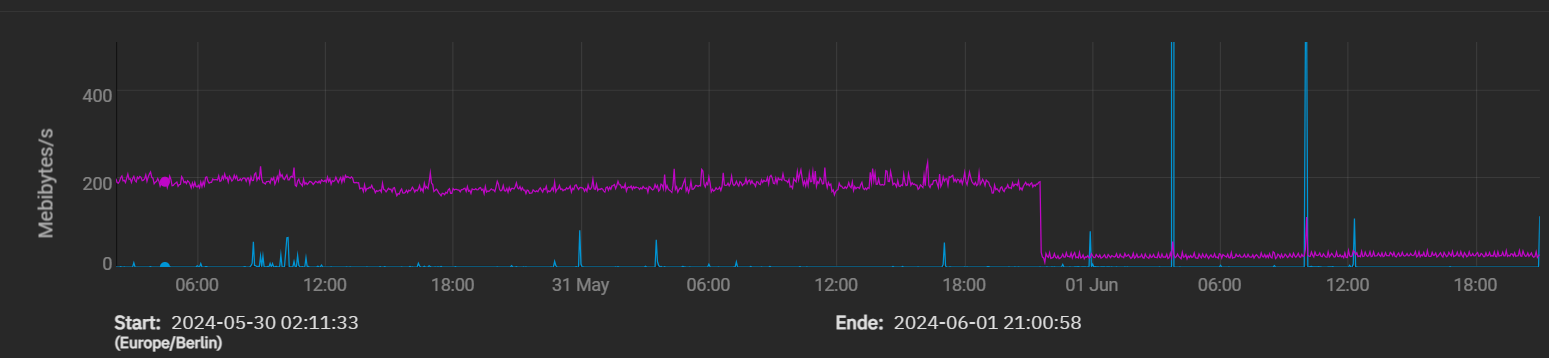
What is currently working fine for me, was changing the zfs_txg_timeout to 60. As you can see in the disk-write graph for my boot-pool, the constant write decreased from approx. 180 KB/s to approx. 30 KB/s.
The following questions are still not really solved for me:
Thank you very much for any further input.
@kris I am not enough of a ZFS expert (indeed not any type of ZFS expert) to know whether this is a good idea or not. I see from the documentation that various other parameters are related to this one, so I am not sure whether this is a good idea or not, whether other parameters should be changed at the same time or whether this is something that should be done as standard in TN.
(My gut reaction is that OpenZFS default parameters were probably chosen to be generally optimal, and that iX would already have changed any that were sensible for TN, but it seems worth asking the iX experts about this.)
Hey OP @mat.bitty,
I know this is not the answer you want to hear, but I guess the situation is this:
Kubernetes is like all virtualization and containers a little bit wasteful.
It is easy to use, you can spin up multiple instances and all the good stuff, but it is wasteful.
So I doubt that iXSystems cares much about some extra GB written every day.
Even a cheap Prosumer WD Red SN700 1TB drive offers 2000TBW. With your 80GB/day workload, that drive would last more than 70 years.
Don’t overthink it ![]()