Ok, this one is totally baffling to me. I often move largish (greater than 50GB) files from one dataset to another on my pool. I use Windows 11/Server Side Copy, so it normally goes at about 1.5GB/s. It’s an all SSD pool, and while I think it should be faster, that’s fast enough for me.
Today, for the first time since I think upgrading to 24.04.2 I was doing a copy, and it went very fast. Too fast, as in 17GB/s fast. I tried again with a larger number of files, and this is what it looked like:
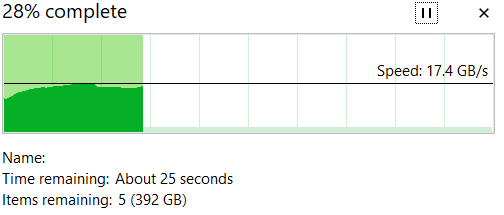
To try and be perfectly clear, this shows copying files from Pool/Dataset1 to Pool/Dataset2.
There is no way even my SSD pool can write and read to itself that fast, and while the transfer is happening there is no disk activity at all shown in netdata or iostat which implies no data is actually being copied, yet, the files all show up and look normal in Windows explorer and via terminal. The don’t appear to be links to files. Deduplication is turned off.
This behavior is also exhibited on a Windows 10 VM, so it’s not isolated to Windows 11 or my desktop computer.
When a file is copied to another dataset, the sized used on the dataset as shown in the TrueNAS GUI increases by the appropriate amount for the file size. In this case they are video files, and the video files can be played back with no issue after being copied.
Doing file copies via a terminal session using the cp command go at 2GB/s with the normal corresponding read and write activity on the drives, so the phenomenon I’m seeing only happens with moving or copying files via Windows Explorer.
I have another pool, and file copies back and forth to that pool via Windows Explorer go at a more normal 1GB/s.
I’m seeing this to all datasets in the pool except one, and that dataset uses 128k record sizes. Changing it’s record size to 1M like the others replicates the fast transfer behavior. Changing it back to 128k reverts it back to around 1GB/s. Clearly this is related to record size somehow.
So what is going on here? I’m stumped as I’ve never seen this before. The speed is fantastic, but I don’t want to rely on it being real.