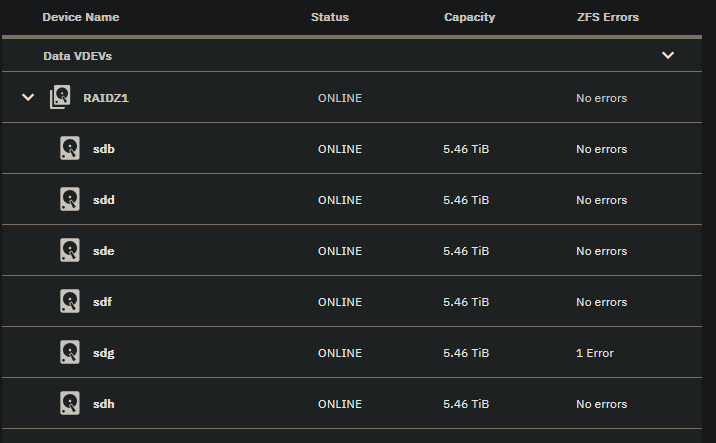
truenas_admin@truenas[~]$ sudo smartctl -x /dev/sdg
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.6.44-production+truenas] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red
Device Model: WDC WD60EFRX-68MYMN1
Serial Number: WD-WX11D55PX170
LU WWN Device Id: 5 0014ee 26199e5b4
Firmware Version: 82.00A82
User Capacity: 6,001,175,126,016 bytes [6.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5700 rpm
Device is: In smartctl database 7.3/5528
ATA Version is: ACS-2, ACS-3 T13/2161-D revision 3b
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Mon Nov 18 12:41:00 2024 GMT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
AAM feature is: Unavailable
APM feature is: Unavailable
Rd look-ahead is: Enabled
Write cache is: Enabled
DSN feature is: Unavailable
ATA Security is: Disabled, NOT FROZEN [SEC1]
Wt Cache Reorder: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x04) Offline data collection activity
was suspended by an interrupting command from host.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 2984) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 684) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x303d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 200 200 051 - 0
3 Spin_Up_Time POS–K 211 198 021 - 8450
4 Start_Stop_Count -O–CK 099 099 000 - 1362
5 Reallocated_Sector_Ct PO–CK 200 200 140 - 0
7 Seek_Error_Rate -OSR-K 200 200 000 - 0
9 Power_On_Hours -O–CK 001 001 000 - 73317
10 Spin_Retry_Count -O–CK 100 100 000 - 0
11 Calibration_Retry_Count -O–CK 100 100 000 - 0
12 Power_Cycle_Count -O–CK 100 100 000 - 133
192 Power-Off_Retract_Count -O–CK 200 200 000 - 67
193 Load_Cycle_Count -O–CK 196 196 000 - 12970
194 Temperature_Celsius -O—K 124 103 000 - 28
196 Reallocated_Event_Count -O–CK 200 200 000 - 0
197 Current_Pending_Sector -O–CK 200 200 000 - 0
198 Offline_Uncorrectable ----CK 100 253 000 - 0
199 UDMA_CRC_Error_Count -O–CK 200 200 000 - 0
200 Multi_Zone_Error_Rate —R-- 200 200 000 - 0
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
General Purpose Log Directory Version 1
SMART Log Directory Version 1 [multi-sector log support]
Address Access R/W Size Description
0x00 GPL,SL R/O 1 Log Directory
0x01 SL R/O 1 Summary SMART error log
0x02 SL R/O 5 Comprehensive SMART error log
0x03 GPL R/O 6 Ext. Comprehensive SMART error log
0x06 SL R/O 1 SMART self-test log
0x07 GPL R/O 1 Extended self-test log
0x09 SL R/W 1 Selective self-test log
0x10 GPL R/O 1 NCQ Command Error log
0x11 GPL R/O 1 SATA Phy Event Counters log
0x21 GPL R/O 1 Write stream error log
0x22 GPL R/O 1 Read stream error log
0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log
0x80-0x9f GPL,SL R/W 16 Host vendor specific log
0xa0-0xa7 GPL,SL VS 16 Device vendor specific log
0xa8-0xb6 GPL,SL VS 1 Device vendor specific log
0xb7 GPL,SL VS 40 Device vendor specific log
0xbd GPL,SL VS 1 Device vendor specific log
0xc0 GPL,SL VS 1 Device vendor specific log
0xc1 GPL VS 93 Device vendor specific log
0xe0 GPL,SL R/W 1 SCT Command/Status
0xe1 GPL,SL R/W 1 SCT Data Transfer
SMART Extended Comprehensive Error Log Version: 1 (6 sectors)
Device Error Count: 15
CR = Command Register
FEATR = Features Register
COUNT = Count (was: Sector Count) Register
LBA_48 = Upper bytes of LBA High/Mid/Low Registers ] ATA-8
LH = LBA High (was: Cylinder High) Register ] LBA
LM = LBA Mid (was: Cylinder Low) Register ] Register
LL = LBA Low (was: Sector Number) Register ]
DV = Device (was: Device/Head) Register
DC = Device Control Register
ER = Error register
ST = Status register
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It “wraps” after 49.710 days.
Error 15 [14] occurred at disk power-on lifetime: 7741 hours (322 days + 13 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
40 – 51 00 00 00 00 cc 24 f2 08 40 00 Error: UNC at LBA = 0xcc24f208 = 3424973320
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
60 00 38 00 00 00 00 cc 24 f2 08 40 00 5d+08:26:00.000 READ FPDMA QUEUED
60 00 30 00 00 00 00 cd 75 10 40 40 00 5d+08:25:59.992 READ FPDMA QUEUED
60 00 38 00 00 00 00 cd 75 10 08 40 00 5d+08:25:59.989 READ FPDMA QUEUED
60 00 38 00 00 00 00 cd 75 0f d0 40 00 5d+08:25:59.985 READ FPDMA QUEUED
60 00 30 00 00 00 00 cd 75 0f a0 40 00 5d+08:25:59.981 READ FPDMA QUEUED
Error 14 [13] occurred at disk power-on lifetime: 44541 hours (1855 days + 21 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
40 – 51 04 00 00 00 bd a5 00 00 e0 00 Error: UNC 1024 sectors at LBA = 0xbda50000 = 3181707264
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
25 00 00 04 00 00 00 bd a5 00 00 e0 08 1d+04:11:00.642 READ DMA EXT
25 00 00 04 00 00 00 bd a4 fc 00 e0 08 1d+04:11:00.635 READ DMA EXT
25 00 00 04 00 00 00 bd a4 f8 00 e0 08 1d+04:11:00.632 READ DMA EXT
25 00 00 04 00 00 00 bd a4 f4 00 e0 08 1d+04:11:00.629 READ DMA EXT
25 00 00 04 00 00 00 bd a4 f0 00 e0 08 1d+04:11:00.626 READ DMA EXT
Error 13 [12] occurred at disk power-on lifetime: 44473 hours (1853 days + 1 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
40 – 51 00 08 00 00 2b 52 85 40 e0 00 Error: UNC 8 sectors at LBA = 0x2b528540 = 726828352
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
25 00 00 00 08 00 00 2b 52 85 40 e0 08 5d+07:18:40.945 READ DMA EXT
ea 00 00 00 00 00 00 00 00 00 00 e0 08 5d+07:18:40.883 FLUSH CACHE EXT
35 00 00 00 01 00 02 b9 91 84 18 e0 08 5d+07:18:40.883 WRITE DMA EXT
ea 00 00 00 00 00 00 00 00 00 00 e0 08 5d+07:18:40.883 FLUSH CACHE EXT
c8 00 00 00 08 00 00 08 50 8d 88 e8 08 5d+07:18:40.768 READ DMA
Error 12 [11] occurred at disk power-on lifetime: 44051 hours (1835 days + 11 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
40 – 51 03 b8 00 00 28 b3 8f 88 e0 00 Error: UNC 952 sectors at LBA = 0x28b38f88 = 682856328
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
25 00 00 03 b8 00 00 28 b3 8f 88 e0 08 27d+23:24:45.490 READ DMA EXT
25 00 00 01 20 00 00 28 b3 6e 68 e0 08 27d+23:24:45.347 READ DMA EXT
25 00 00 02 00 00 00 28 b3 6c 68 e0 08 27d+23:24:45.325 READ DMA EXT
25 00 00 00 80 00 00 28 b3 6b e8 e0 08 27d+23:24:45.325 READ DMA EXT
25 00 00 00 20 00 00 28 b3 6b c8 e0 08 27d+23:24:45.306 READ DMA EXT
Error 11 [10] occurred at disk power-on lifetime: 32733 hours (1363 days + 21 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
40 – 51 00 08 00 00 7e 0b 10 18 e0 00 Error: UNC 8 sectors at LBA = 0x7e0b1018 = 2114654232
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
25 00 00 00 08 00 00 7e 0b 10 18 e0 08 2d+09:07:55.136 READ DMA EXT
25 00 00 00 70 00 00 75 cb 08 98 e0 08 2d+09:07:55.091 READ DMA EXT
25 00 00 00 08 00 00 75 cb 08 90 e0 08 2d+09:07:55.091 READ DMA EXT
25 00 00 00 08 00 00 75 cb 08 88 e0 08 2d+09:07:55.086 READ DMA EXT
25 00 00 00 60 00 00 88 55 b4 20 e0 08 2d+09:07:55.055 READ DMA EXT
Error 10 [9] occurred at disk power-on lifetime: 31899 hours (1329 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
40 – 51 00 08 00 00 7a f5 b3 88 e0 00 Error: UNC 8 sectors at LBA = 0x7af5b388 = 2062922632
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
25 00 00 00 08 00 00 7a f5 b3 88 e0 08 9d+16:38:48.674 READ DMA EXT
25 00 00 00 40 00 00 62 ad c6 b8 e0 08 9d+16:38:48.658 READ DMA EXT
25 00 00 00 08 00 00 77 a0 64 10 e0 08 9d+16:38:48.658 READ DMA EXT
25 00 00 00 08 00 00 77 a0 64 18 e0 08 9d+16:38:48.658 READ DMA EXT
25 00 00 00 08 00 00 77 a0 64 08 e0 08 9d+16:38:48.646 READ DMA EXT
Error 9 [8] occurred at disk power-on lifetime: 30904 hours (1287 days + 16 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
40 – 51 00 08 00 00 6d d5 b3 88 e0 00 Error: UNC 8 sectors at LBA = 0x6dd5b388 = 1842721672
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
25 00 00 00 08 00 00 6d d5 b3 88 e0 08 2d+08:08:25.445 READ DMA EXT
25 00 00 00 80 00 01 18 eb 14 88 e0 08 2d+08:08:25.382 READ DMA EXT
25 00 00 00 10 00 01 18 eb 13 f8 e0 08 2d+08:08:25.201 READ DMA EXT
25 00 00 00 10 00 01 18 eb 13 e8 e0 08 2d+08:08:25.201 READ DMA EXT
25 00 00 00 10 00 01 18 eb 13 d8 e0 08 2d+08:08:25.200 READ DMA EXT
Error 8 [7] occurred at disk power-on lifetime: 30843 hours (1285 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER – ST COUNT LBA_48 LH LM LL DV DC
– – – == – == == == – – – – –
10 – 51 00 08 00 02 b9 91 83 f8 e0 00 Error: IDNF 8 sectors at LBA = 0x2b99183f8 = 11703256056
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
– == – == – == == == – – – – – --------------- --------------------
35 00 00 00 08 00 02 b9 91 83 f8 e0 08 1d+23:04:57.374 WRITE DMA EXT
ea 00 00 00 00 00 00 00 00 00 00 e0 08 1d+23:04:57.329 FLUSH CACHE EXT
ea 00 00 00 00 00 00 00 00 00 00 e0 08 1d+23:04:55.194 FLUSH CACHE EXT
35 00 00 00 01 00 02 b9 91 84 18 e0 08 1d+23:04:55.194 WRITE DMA EXT
ea 00 00 00 00 00 00 00 00 00 00 e0 08 1d+23:04:55.193 FLUSH CACHE EXT
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
1 Extended offline Completed without error 00% 7773 -
2 Conveyance offline Completed without error 00% 7744 -
3 Short offline Completed without error 00% 7744 -
4 Short offline Completed without error 00% 7516 -
5 Short offline Completed without error 00% 7402 -
6 Short offline Completed without error 00% 7234 -
7 Short offline Completed without error 00% 7066 -
8 Short offline Completed without error 00% 6898 -
9 Short offline Completed without error 00% 6731 -
#10 Short offline Completed without error 00% 6563 -
#11 Short offline Completed without error 00% 6395 -
#12 Short offline Completed without error 00% 6227 -
#13 Short offline Completed without error 00% 6059 -
#14 Short offline Completed without error 00% 5891 -
#15 Short offline Completed without error 00% 5724 -
#16 Short offline Completed without error 00% 5557 -
#17 Short offline Completed without error 00% 5389 -
#18 Short offline Completed without error 00% 5221 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
SCT Status Version: 3
SCT Version (vendor specific): 258 (0x0102)
Device State: Active (0)
Current Temperature: 28 Celsius
Power Cycle Min/Max Temperature: 23/30 Celsius
Lifetime Min/Max Temperature: 2/49 Celsius
Under/Over Temperature Limit Count: 0/0
Vendor specific:
00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
SCT Temperature History Version: 2
Temperature Sampling Period: 1 minute
Temperature Logging Interval: 1 minute
Min/Max recommended Temperature: 0/60 Celsius
Min/Max Temperature Limit: -41/85 Celsius
Temperature History Size (Index): 478 (467)
Index Estimated Time Temperature Celsius
468 2024-11-18 04:44 28 *********
… …( 71 skipped). … *********
62 2024-11-18 05:56 28 *********
63 2024-11-18 05:57 27 ********
… …(364 skipped). … ********
428 2024-11-18 12:02 27 ********
429 2024-11-18 12:03 28 *********
… …( 37 skipped). … *********
467 2024-11-18 12:41 28 *********
SCT Error Recovery Control:
Read: 70 (7.0 seconds)
Write: 70 (7.0 seconds)
Device Statistics (GP/SMART Log 0x04) not supported
Pending Defects log (GP Log 0x0c) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 2 0 Command failed due to ICRC error
0x0002 2 0 R_ERR response for data FIS
0x0003 2 0 R_ERR response for device-to-host data FIS
0x0004 2 0 R_ERR response for host-to-device data FIS
0x0005 2 0 R_ERR response for non-data FIS
0x0006 2 0 R_ERR response for device-to-host non-data FIS
0x0007 2 0 R_ERR response for host-to-device non-data FIS
0x0008 2 0 Device-to-host non-data FIS retries
0x0009 2 3 Transition from drive PhyRdy to drive PhyNRdy
0x000a 2 9 Device-to-host register FISes sent due to a COMRESET
0x000b 2 0 CRC errors within host-to-device FIS
0x000f 2 0 R_ERR response for host-to-device data FIS, CRC
0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC
0x8000 4 605596 Vendor specific