Dear community, from this morning I got TrueNAS Scale Dragonfish-24.04.1.1 instability.
My TrueNAS runs under proxmox and the whole controller has been passed to TrueNAS VM. I have 2 pools, tank (4x10TB 2 mirrors) and tank-backup (RAID-Z1 4x4TB). If I try to access to samba share on tank and try to read some files I got the following from console:
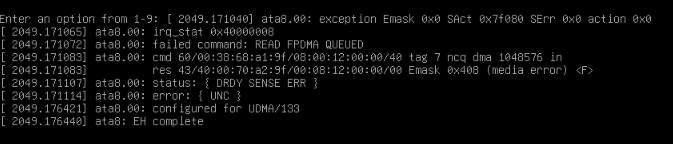
I reboot TrueNAS and try to start a scrub on tank pool, but again TrueNAS hangs and I got several read errors like above.
Now what? Is it time to replace disk? But which disk? ata8???
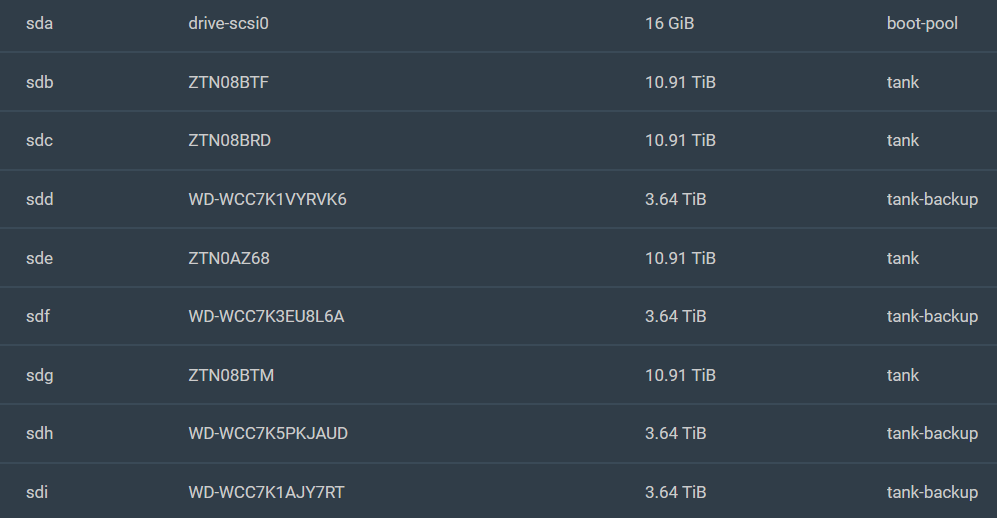
These are the disks in my box:
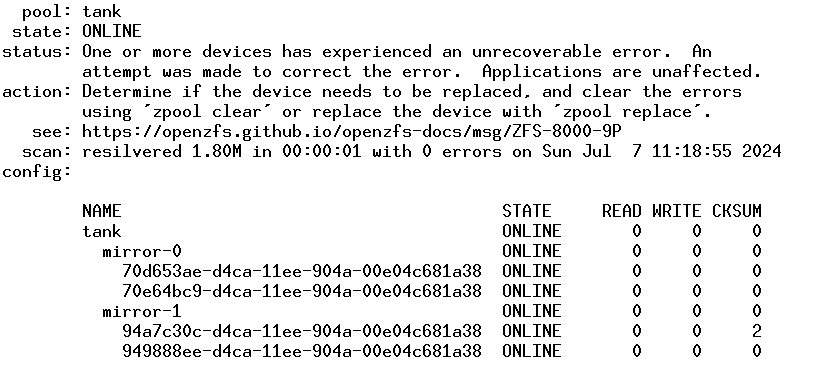
This is the status of the pool right now (after the reboot):
Please help to moving forward.
Thank you
Lucas
Any old TrueNAS alert will be useless when determining which drive(s) are faulty since the device names (sda, etc) can change after a reboot.
Run smartctl -a /dev/sdX on each disk and note any reported errors in the table of smart details.
Post them here if you aren’t sure how to interpret them.
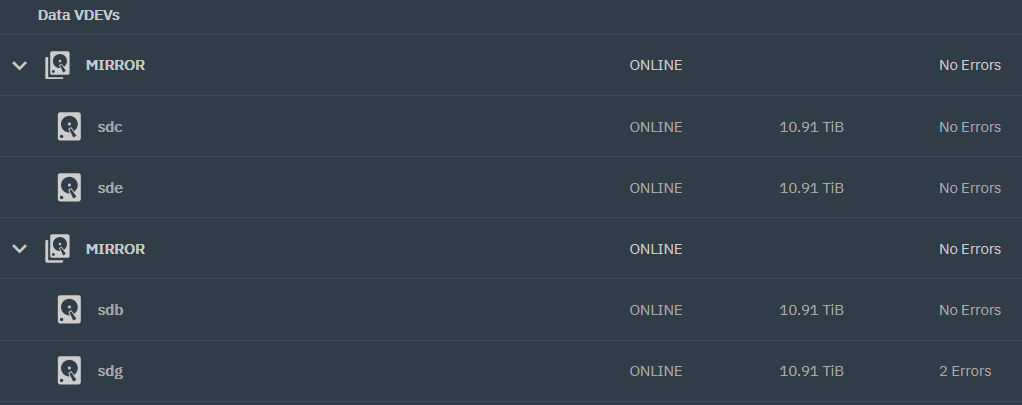
It seems I identified the broken disk:
is the sdg need to be replaced? O is there anything I can do to recover these errors?
EDIT:
This is the smartctl output as kindly suggested by neofusion
# smartctl -a /dev/sdg
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.6.29-production+truenas] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate IronWolf Pro
Device Model: ST12000NE0008-2PK103
Serial Number: ZTN08BTM
LU WWN Device Id: 5 000c50 0b1f18cf4
Firmware Version: CN03
User Capacity: 12,000,138,625,024 bytes [12.0 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database 7.3/5528
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Sun Jul 7 11:34:49 2024 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 567) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: (1063) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x50bd) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 082 064 044 Pre-fail Always - 163645724
3 Spin_Up_Time 0x0003 090 089 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 98
5 Reallocated_Sector_Ct 0x0033 092 092 010 Pre-fail Always - 32568
7 Seek_Error_Rate 0x000f 081 060 045 Pre-fail Always - 122709146
9 Power_On_Hours 0x0032 097 097 000 Old_age Always - 3132
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 31
187 Reported_Uncorrect 0x0032 001 001 000 Old_age Always - 150
188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0022 056 049 040 Old_age Always - 44 (Min/Max 40/45)
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 9
193 Load_Cycle_Count 0x0032 092 092 000 Old_age Always - 16281
194 Temperature_Celsius 0x0022 044 051 000 Old_age Always - 44 (0 19 0 0 0)
195 Hardware_ECC_Recovered 0x001a 014 004 000 Old_age Always - 163645724
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
200 Pressure_Limit 0x0023 100 100 001 Pre-fail Always - 0
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 590h+01m+28.574s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 114038905372
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51142668151
SMART Error Log Version: 1
ATA Error Count: 150 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 150 occurred at disk power-on lifetime: 3132 hours (130 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 00 ff ff ff 4f 00 00:26:36.258 READ FPDMA QUEUED
47 00 01 13 00 00 a0 00 00:26:36.257 READ LOG DMA EXT
47 00 01 00 00 00 a0 00 00:26:36.257 READ LOG DMA EXT
ef 10 02 00 00 00 a0 00 00:26:36.257 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 a0 00 00:26:36.254 IDENTIFY DEVICE
Error 149 occurred at disk power-on lifetime: 3132 hours (130 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 00 ff ff ff 4f 00 00:26:26.670 READ FPDMA QUEUED
47 00 01 13 00 00 a0 00 00:26:26.664 READ LOG DMA EXT
47 00 01 00 00 00 a0 00 00:26:26.663 READ LOG DMA EXT
ef 10 02 00 00 00 a0 00 00:26:26.663 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 a0 00 00:26:26.661 IDENTIFY DEVICE
Error 148 occurred at disk power-on lifetime: 3132 hours (130 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 00 ff ff ff 4f 00 00:26:17.409 READ FPDMA QUEUED
47 00 01 13 00 00 a0 00 00:26:17.408 READ LOG DMA EXT
47 00 01 00 00 00 a0 00 00:26:17.407 READ LOG DMA EXT
ef 10 02 00 00 00 a0 00 00:26:17.407 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 a0 00 00:26:17.405 IDENTIFY DEVICE
Error 147 occurred at disk power-on lifetime: 3132 hours (130 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 00 ff ff ff 4f 00 00:26:08.093 READ FPDMA QUEUED
47 00 01 13 00 00 a0 00 00:26:08.090 READ LOG DMA EXT
47 00 01 00 00 00 a0 00 00:26:08.090 READ LOG DMA EXT
ef 10 02 00 00 00 a0 00 00:26:08.090 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 a0 00 00:26:08.088 IDENTIFY DEVICE
Error 146 occurred at disk power-on lifetime: 3132 hours (130 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 00 ff ff ff 4f 00 00:25:58.546 READ FPDMA QUEUED
47 00 01 13 00 00 a0 00 00:25:58.539 READ LOG DMA EXT
47 00 01 00 00 00 a0 00 00:25:58.539 READ LOG DMA EXT
ef 10 02 00 00 00 a0 00 00:25:58.539 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 a0 00 00:25:58.537 IDENTIFY DEVICE
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
The above only provides legacy SMART information - try 'smartctl -x' for more
CKSUM errors are often related to cable/connection issues. I would first try unplugging and replugging the data cable to the affected drive. If it doesn’t clear the CKSUM error, then I would swap the cable to another drive and see if the error moves with the cable. If it does, replace the cable.
If it doesn’t seem to be cable related, then run a scrub. If no change then replace the drive.
I see two problems and I will list the most significant with respect to this issue first.
- 5 Reallocated_Sector_Ct 0x0033 092 092 010 Pre-fail Always - 32568
EDIT: Adding one other huge warning message:
195 Hardware_ECC_Recovered 0x001a 014 004 000 Old_age Always - 163645724
If the drive is under warranty, RMA the drive. It will not get any better.
- You are not running SMART self-tests. You should setup a daily SMART Short self-test on all drives and I suggest a weekly SMART Long self-test on each drive. you can split the drives into a few different days for the Long tests if you desire.
@Redcoat Unfortunately this does not look like a cable issue.
2 Likes
Thanks - I missed that issue in the smart results. 
You are not alone, I miss things as well and I want to kick myself in the ass for the mistake.
Also, I have no idea if this drive has 3K hours or 68K hours and the timer rolled over. I could do a warranty check but the OP should handle that.
1 Like
Thanks for pointing me out to the right smart result place, I opened a RMA to Seagate, and it seems they accept it as the drive is still under warranty. Now, I put in offline the broken disk waiting for replacing… Crossfingers for at least two weeks as, obviously, now the pool is in degraded state.
It’s why I usually like to keep spares in my lab any array always have a spare drive in a box, if it dies at 2am, swap, restore and then think about what to do with the bad drive if it’s a Z1 or a mirror you never know how much time you have left until another drive dies 
Yep! This is what I did for my other pool (4x4TB WD Red). I have a spare part purchased some years ago… never used! And what’s the broken disk? 12TB purchased 4 months ago
12TB is expensive, so I didn’t purchased an extra disk. Lesson learned, RMA will replace the disk, meanwhile I’m looking to ebay to take another 12TB just incase!
You should have tried for an Advanced RMA. Thi is where they take your credit card number and send you a replacement drive, then you send them back the failed drive within XX days. If they don’t get it in time, they charge your credit card.
i’ve used this method several times and I prefer it. I get a return box that is authorized by the manufacturer so they can’t tell me it shipped in a substandard box.
Mine are 8x14TB I bought some certified refurbished drives on ebay, I got lucky no issues and everything went well, i had some used 14TB from the old days mixed with them and so far so good, all of them seagate exos, I always got my drives shucked so I have no idea what the concept of RMA a hard drive is or having an actual warranty  but there’s your ‘money for the spare drive’, though here in the EU I don’t think they can deny you warranty on a drive that’s been shucked that is if you still have the parts and can put everything back together neatly.
but there’s your ‘money for the spare drive’, though here in the EU I don’t think they can deny you warranty on a drive that’s been shucked that is if you still have the parts and can put everything back together neatly.
Personally if I were to spend big bucks on drives I would go for SAS and back in the day would’ve gone for HGST nowadays might need to look the latest drive reliability charts from datacenters and see what to get, probably 20TB for maximum data density or 32TB ssds if a billionaire out there is feeling generous…
I didn’t know this kind of RMA, but I double checked again my Seagate account and it seems such RMA is not available for my country (Italy).
Mine are from ebay too, China seller. I was lucky they are under EU warranty.
My “dream” is build a pool with only M2 drives, so that I can take full advantage of my 10Gb connection. Currently I can trasnfer file to/from my nas at about 300MB/Sec, not bad, but could be better
But I need space, and big (and good) M2 drives are expensive.