Hello I have a new install of v25.04.0 that have been upgraded to v25.04.1.
and I’ve attempted to import my pools in it, but I still (like on v24.10.xxx get the nasty watchdog bug showing its nose
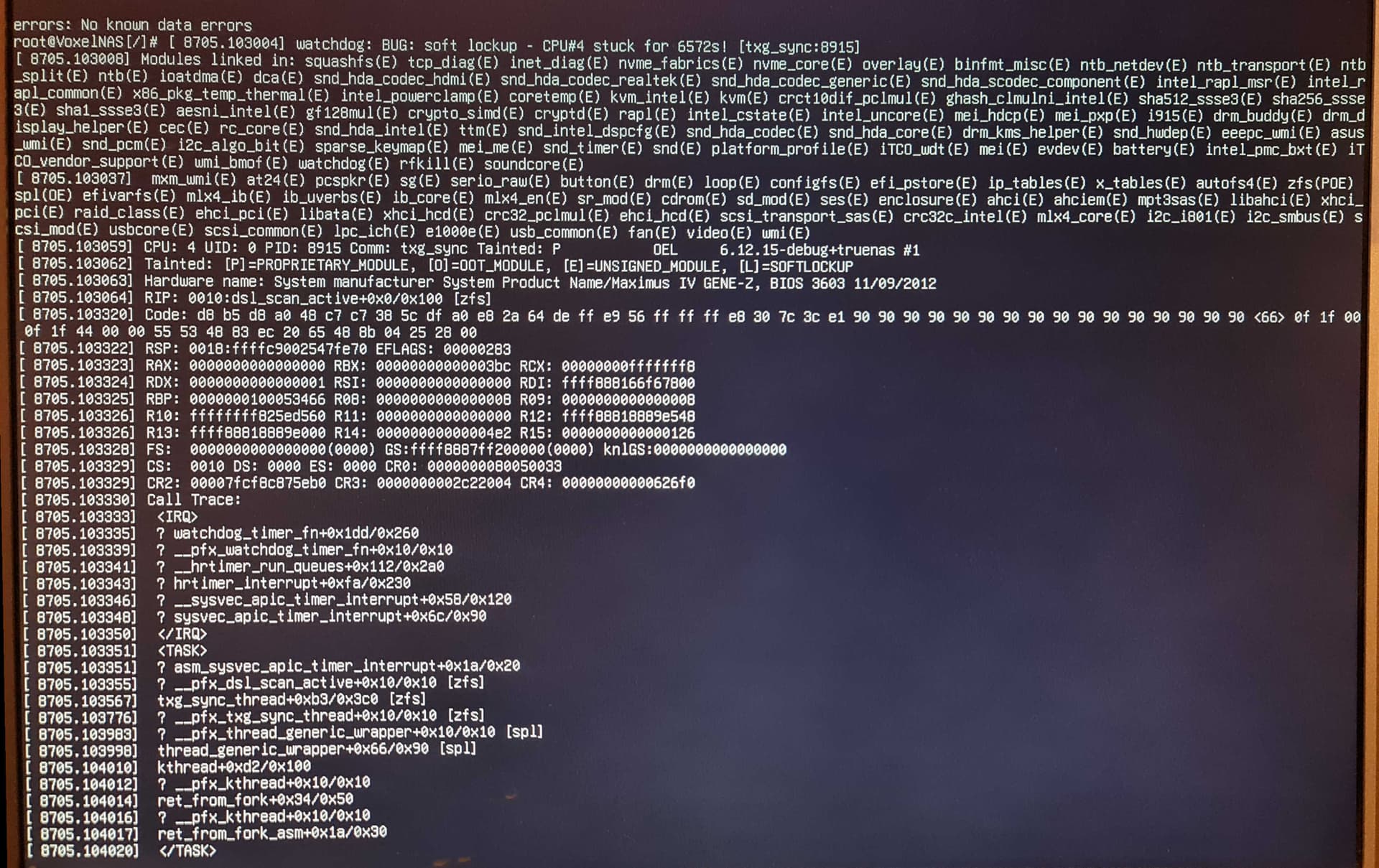
I’ve taken a photo of the screen report as I can’t get the text version on this machine in full :
Hello
yes it was 'till one drive began to fail, (it is currently being replaced by an hot spare disk and resilvered but this bug slows things) it was in v24.10.xxx, I hopped that v25 upgrades will cure this but not
what log do you need to address this bug ?
hardware failure ?
btw I have tested the drive that’s getting ‘dead’ in the pool and perfomed a ddrescue to another drive to it (took about 15 days !) and you know what ? ddrescue hasn’t found ANY read errors on it from block 0 to the last one !..
but that same disk connected to the pool finish invariably to spurt 120k read errors and power-on resets (but hasn’t at all in 15 days on getting read by ddrescue…)… that’s after that that the watchdog do appears and stall everything.
I’m kind of puzzled there, I’ve replaced the sata cable of it with no changes, haven’t swapped the HBA connector it reaches thought… (danm’ I don’t have another HBA Extender of the same model to test with)
will try that too
BTW II you said revert to 24.10, ok but I’ve performed the zfs updates of v25, isn’t it dangerous ?
I’ve performed a total revamp of the disks cabling so it are not using the HBA expander port that was seemingly causing problem, for this the now cabling is this :
1st port of the HBA goes to the 1st port of the expander card ;
2nd port of the HBA is used by the four 1st disks of the zpool (ID 0-3) ;
2nd port of the expander is not used ;
3rd port of the expander is used by the next four disks of the zpool (ID 4-7) ;
4th port of the expander is used by the next four disks of the zpool (ID 8-11) ;
5th port of the expander is used by the next four disks of the zpool (ID 12-15) ;
6th port of the expander is used by the last four disks of the zpool (ID 16-19) ;
ID19 is used by the cache ssd.
now booting shows no errors, but the zpool isn’t imported…
so I tried to import it by hand (see the pic) and after some time
got a panic + reset from the debug kernel I booted on…
min@truenas[~]$ sudo zpool import
pool: VoxelZ2
id: 10054978536421108484
state: DEGRADED
status: One or more devices were being resilvered.
action: The pool can be imported despite missing or damaged devices. The
fault tolerance of the pool may be compromised if imported.
config:
VoxelZ2 DEGRADED
raidz2-0 DEGRADED
aab036a6-7e2b-4632-b16d-cd7866845e5e ONLINE
7a8f8da1-836b-4a4c-9eaa-2aa29da2beb7 ONLINE
a10d9ac9-ef2c-4ede-9e6b-eba01e901361 ONLINE
9f2dce88-cde7-4923-b0bb-bf4de890ea52 ONLINE
replacing-4 DEGRADED
b74d4b85-0436-4814-8515-b405d7e40e24 UNAVAIL
181fbb56-496c-4540-a107-d35504e0d61b ONLINE
spare-5 ONLINE
96d445ec-e8b2-42ce-8f1a-63ca963eead9 ONLINE
67741fad-0683-4df2-ad52-c0c30405c419 ONLINE
b4dbc538-a334-417c-9b6a-7265693bc710 ONLINE
fd7f4ef7-237a-48c0-8a72-bebaf1cd3fb5 ONLINE
83e62634-a0a5-4c2f-abb8-10b763833042 ONLINE
ea3b911a-d478-4341-b4cd-4549385fcdde ONLINE
52c0cc19-1576-4186-b41f-8ee005e7ebaf ONLINE
ee9542ae-6266-4615-bcaa-6a0f06dafb87 ONLINE
0b764a40-fd5d-4631-922d-625178717347 ONLINE
e0df314c-cc1e-460e-9591-842264306d5b ONLINE
af112e1e-211c-4061-a0bf-4e7f943903ca ONLINE
c2c7b568-7eff-4f85-998b-eb4e1ac51897 ONLINE
ebd9e063-ebb9-4bdb-9ac6-3302a748390a ONLINE
cache
b7523e48-e07b-4fbb-94c5-c6de97a7d33c
spares
67741fad-0683-4df2-ad52-c0c30405c419
exp :
the ‘unavail disk’ is the one that died for good (on v24.10.xxx, no spin no life it is not present in the nas. re turned to seller for replacement) it is being replaced (currently when not crashing it was at 77% done)
the ‘spare-5’ disk replace a ‘degraded’ but not dead disk (just beggining)
now as said if I issue a ‘sudo zpool import ‘with -f or not) I get the kernel panic now after some times (30’ to 45’) and a reboot of the TrueNAS
what can I do ?
is it possible to ‘verify’ or ’ validate’ a non yet imported zpool ?
is there a way to ‘offline’ a disk that is not present anymore (will get rid of the ‘unavail’)