I’ve been doing an inplace rebalance of a mirror pool consisting of 4 vdevs and…I am basically through (about 500 G to go) but I just don’t see the expected result.
Here is how this pool’s occupancy currently looks like:
As you can see, the pool occupancy is about 25% and I expected all vdevs to be around that same CAP, but that didn’t happen and I curious if I did something wrong or are we looking at an anomaly here.
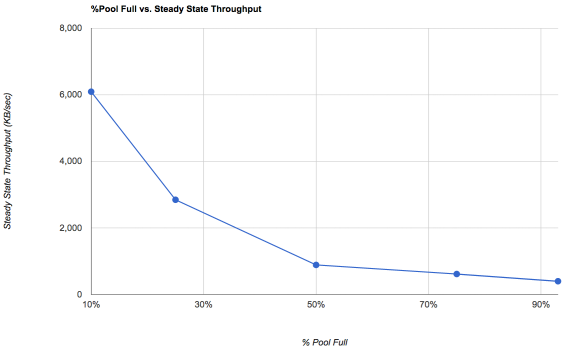
My understanding is that steady-state pool IOPS falls sharply from 10% occupancy onward (link here, p.6).
I would have expected ZFS to try and maintain the per vdev occupancy parity at all times so that IOPS is relatively consistent across the pool, but that doesn’t seem to be the case. I also don’t think that having different-sized vdevs should somehow skew this strategy.
The only explanation I have for the behaviour observed is that ZFS doesn’t target equal CAP, but rather equal ALLOC…but that that makes no sense to me.
What don’t I know here?
EDIT: I removed the snapshots from the pool prior to rebalance
My understanding of the ZFS vdev strategy is that it is not based on CAP nor ALLOC, but rather vdev latency. Let me explain as best I understand it.
Say you have a bunch of data you want to write. ZFS starts breaking it up into allocation units, and in your case of 4 vdevs, sends 1 allocation unit to each vdev and then it waits on the drives. The first vdev that comes back and says it’s done gets the next allocation unit, and so on until you’ve finished writing all the data.
At first glance this seems like it’s allocating data evenly to all the vdevs, and initially it will, but as it the vdevs start to fill up the story will change. Take your system, as mirror-0 and mirror-1 start to get more full (they’re smaller after all) their seek times will naturally start to increase. They’ll start to take longer to complete their writes than the other 2 vdevs and thus writes will begin to be biased to the larger vdevs more. So overall the vdev latency will remain similar.
At least that’s my understanding of the system, someone more knowledgeable please correct me if I got that wrong.
I don’t think so? I’d like to look at the code but the way I’d naively do this is by keeping the CAP across all pool members equal.
Interesting - so ZFS actually keeps track of write op timings per VDEV and then decides where to actually write the data? Quite sophisticated, I did not expect this.
So in the example from OP, the ZFS preferentially writes to 10 TB drives over 14 and 20 TB ones? I’d expect newer and bigger drives to perform “better”…as in - have lower write seek times, all other things being equal?
Not quite that sophisticated, you might be overthinking it. It prefers whatever vdev is “ready”. Since all your drives are relatively large and mostly empty still, the allocation of data has remained roughly even.
If you were to say triple the amount of data you’re storing the allocation pattern would change. The 10T’s would be nearly full and writes would become slow, so those drives would be ready for more data less often than the larger vdevs.
If my [AI-assisted] interpretation of OpenZFS code is correct, vdev write queues are populated based on least busy with a bias toward least full. The more imbalanced they become (space-wise) the stronger this bias becomes. So there’s likely to be some space imbalance but there’s a limit to how bad it’ll get (in theory).
mc_free is the free space across all vdevs in the metaslab class
mg_bias is the bias value that will influence allocation decisions
The mg_bias value is calculated within the metaslab allocation code, specifically in the section that handles vdev selection for writes. This calculation occurs after a successful allocation but before determining whether to rotate to the next vdev:
vs_free: The free space on the current vdev, calculated as vs->vs_space - vs->vs_alloc
vs_space is the total usable space on the vdev
vs_alloc is the space already allocated on the vdev
mc->mc_alloc_groups: The number of metaslab groups (top-level vdevs) in the pool
mc_free: The total free space across all vdevs in the metaslab class, calculated as mc->mc_space - mc->mc_alloc
mg->mg_aliquot: The base allocation granularity value (metaslab.aliquot) for the current metaslab group
The calculation happens in two steps:
First, it calculates a ratio that compares this vdev’s free space to the average free space across all vdevs:
If ratio = 100, this vdev has exactly the average amount of free space
If ratio > 100, this vdev has more free space than average
If ratio < 100, this vdev has less free space than average
Then it calculates the actual bias by:
Subtracting 100 from the ratio (creating a positive or negative value)
Multiplying by the aliquot value (scaling the bias based on the base allocation size)
Dividing by 100 (converting the percentage back to a proportion)
The resulting mg_bias value directly affects when ZFS rotates to the next vdev:
if (atomic_add_64_nv(&mca->mca_aliquot, asize) >= mg->mg_aliquot + mg->mg_bias)
For vdevs with more free space than average: mg_bias is positive, allowing the vdev to receive more data before rotation
For vdevs with less free space than average: mg_bias is negative, causing the vdev to receive less data before rotation
For vdevs with average free space: mg_bias is zero, and standard rotation occurs
Regarding your imbalance… What is the typical recordsize in your pool? Recordsizes in excess of zfs.metaslab_aliquot appear to reduce the effectiveness of the balancing mechanism…