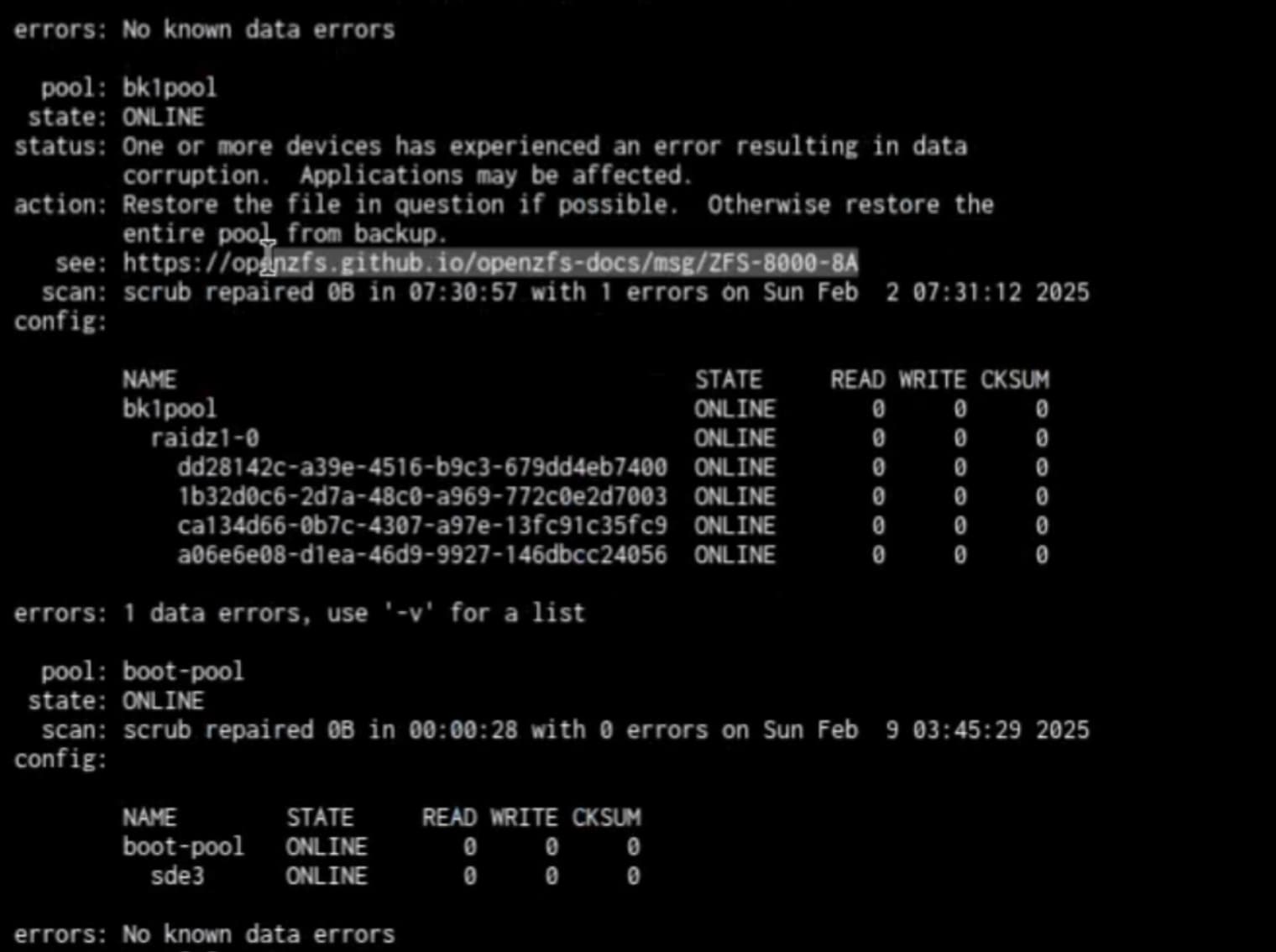
Hi all, so my remote backup system is working like a dream, however I just got off a call where the below screenshot was shown to me. Normally I would just decrypt the dataset and list what file is a problem, delete it and restore it. However this has some other challenges which I am not sure what the protocol should be.
For example, I could just copy and paste the decryption key into the remote side, because while it ‘is’ untrusted, it’s actually a friend that I do trust. Simplest but not technically desirable. Is there a way to allow just this capability to a remote user?
Also, once we resolve how to know which file it is and where it’s from - there are other questions.
I assume this file will be attached to a dataset that has a snapshot that I will have to rollback to to fix, due to all it’s subsequent snapshots relying on the former - then, is there some kind of incremental sync up I can do so that the data is re-sent from the source? Or do I need to do a ‘from scatch’ backup on that specific dataset.
I have had more problems with LSI cards related to heat which are now all swapped out with 3rd party (slower but more reliable) SATA cards. This resulted in a number of issues while I was away overseas which corrupted some data. What happens to the backup if the source has corrupted data? Does it just send the corrupted data as is and I can go back to an earlier version and it’s all good? Or if I’m doing a raw send (not sure that I am though) does it replace the original good version with the corrupted version in the backup? Are there any scenarios here I need to be aware of?
How do you recommend I fix the remote backup target?
Thanks!