I asked a previous question about Best Practice regarding creating datasets for specific workloads (i.e. for specific storage purposes, e.g. photos, videos, music, documents etc.), but I thought that maybe a better way to approach this is to ask people to share (no pun intended) what kinds of Datasets they use and why.
For example:
do you have a dataset dedicated to storing photos?
do you have a dataset dedicated to storing application jail data?
do you have a dataset dedicated to storing databases?
do you have a dataset dedicated to storing videos?
What specific datasets do you - TrueNAS user - use?
Why do you use them?
What specific settings (if any) do you apply to them?
time-machine, for storing time machine backups, with a dataset per system (login per system)
veeem, for storing veem backups per system
replicas, for storing replicas/backups from other systems, one dataset per system
jailmaker, for jailmaker, and associated jail file systems
docker, for docker data, configs, mirrors etc etc
vms, for vm zvols
zvols, for iscsi extents
media, for various media that gets stored/recorded/viewed
share, for general file sharing, with actual permissions divvied out based on user permissions on directories
isos, for isos which get used for vms
server, for storing scripts, logs, etc anything that is actually for the server hosting the pool
I’ll then add a dataset for any significant service, for example, a truenas which is hosting a mail server, or its data, might have a “mail” dataset (actually mailcow), or a truenas that is hosting a gitlab instance (or its data), might have a gitlab dataset, etc
I hope others chime in to add to this so we get a good ‘average’ view of the most popular dataset practices.
What I am hoping to do is to help bridge the gap between all the great technical recommendations for TrueNAS system design and configuration, and recommendations on how to organize digital files and documents, such as is discussed in these videos:
I find I am constantly going around in circles and can never seem to escape confusion over how to achieve digital file sanity…
I am extremely disorganized, so will put my two cents in as an ‘all over the place’ user.
I have three pools, ‘data’, ‘nvme’, and ‘ssd-temp’
My datasets are as follows:
data/bin # for any scripts/binaries I might use on the TrueNAS CLI
data/SMB # general storage access
nvme/ix-applications
nvme/VM # VM zvols
ssd-temp/SMB # striped storage that I am storing very briefly and have no issue losing
I like to use TrueNAS like a big network share, and because of that I tend to store a lot in a big single dataset.
I personally don’t like it. It’s how I set it up initially and I just can’t justify a good reason to go and reorganize something that’s working (if it ain’t broke). I’m the only user so I don’t need to worry about permission partitioning that much.
In an ideal world I’d probably split out media, backups, and then have a general storage dataset beyond that.
Thanks for your input and honesty. (I was a fellow London-based network engineer for many years - I am back home in Sydney now, though).
I found organizing my work files relatively easy in part because it was dictated by my job (as a network engineer). But organizing my personal files I have found much more difficult.
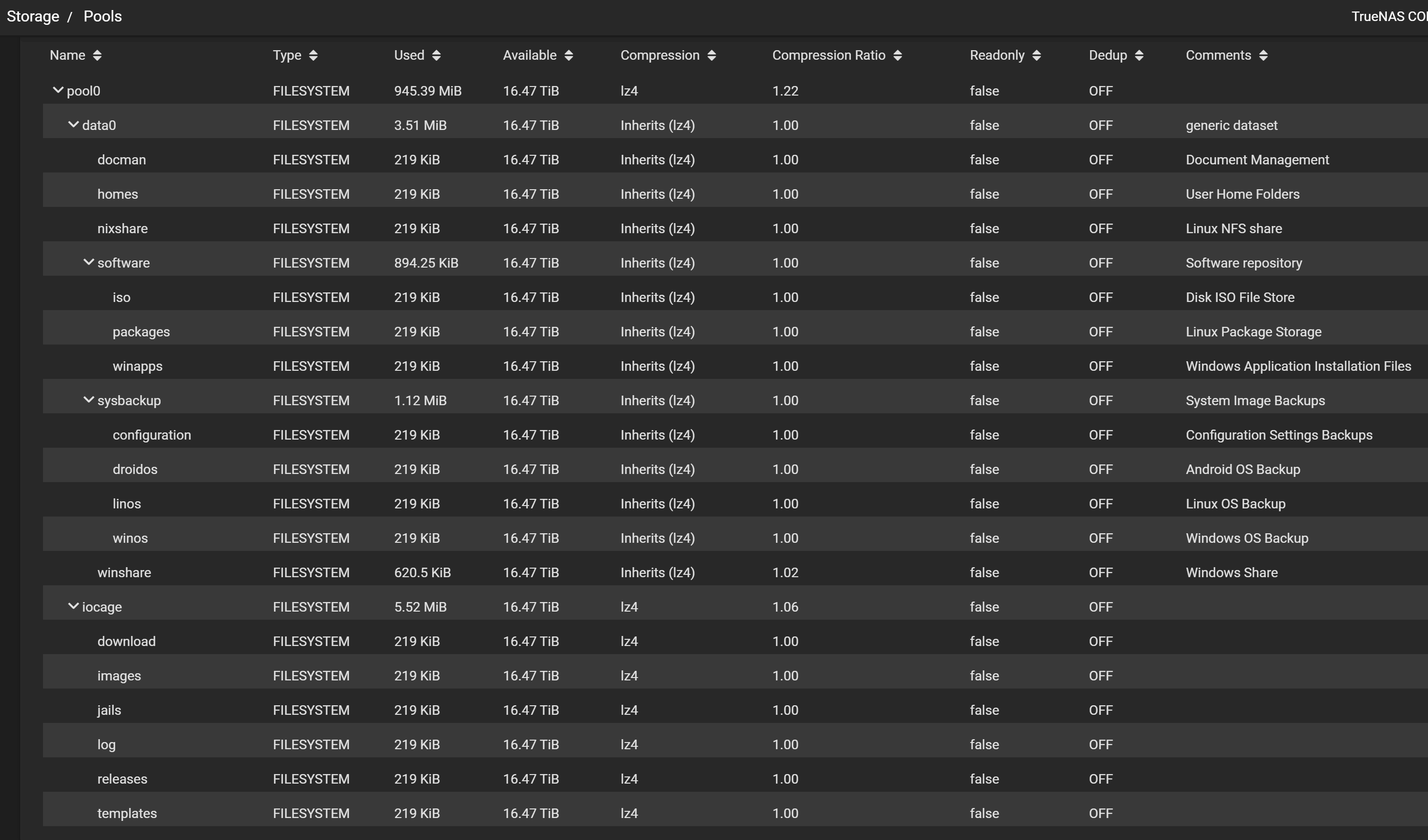
Here is an attempt at dataset ‘design’, which I’d like feedback on if anyone has it:
It seems I don’t have much choice over how Plugins and Jail storage is created. TrueNAS only gives me the option to choose a pool as the parent, not a dataset.
I just started with TrueNAS and coming from other systems/solutions I will start here with the following:
I’m moving/renaming files and folders on my server quite often: so I need one big dataset where these renames can happen without copying/moving the files physically. This is my main network folder.
Then I have a dataset for each client machine for backup. Periodic snapshots are used to keep a history. Currently I have not decided how many versions I will keep.
I generally agree with this, inasmuch as I think datasets are generally high-level storage. I am trying to differentiate between storage classes that serve fundamentally different purposes at said high-level, such as TrueNAS Application stores (plugins/jails), per-user home folders, software repositories (i.e. installation packages, OS disk ISOs and Windows-based installation executables - stuff I don’t want/need to keep on any user machines once installed), system configuration backups (e.g. for network devices and specific applications or server roles - e.g. DNS/DHCP/TrueNAS server configuration), and whole machine backups (as in, backing up a whole disk image for each machine on a dedicated iSCSI share per machine), same as
To me, these seem to be reasonable high-level distinctions. Obviously, each one of these high-level datasets would have sub-folder organization (mostly managed from the client side).
Correct. Each client can decide how the backup folders are organized.
For me it is just a backup! The actual data is used and changed on the client machine: this is much faster (each client has only SSDs, even 1 TB SSDs are really cheap these days) compared to the direct manipulation via smb on the server.
Of course: regular backups are necessary when using this approach. Each client has a simple sync program and should use it from time to time.
I am fairly novice and organized my data from the bottom-up. I wish I met @stux earlier because I am definitely breaking the rule of having datasets organize my data.
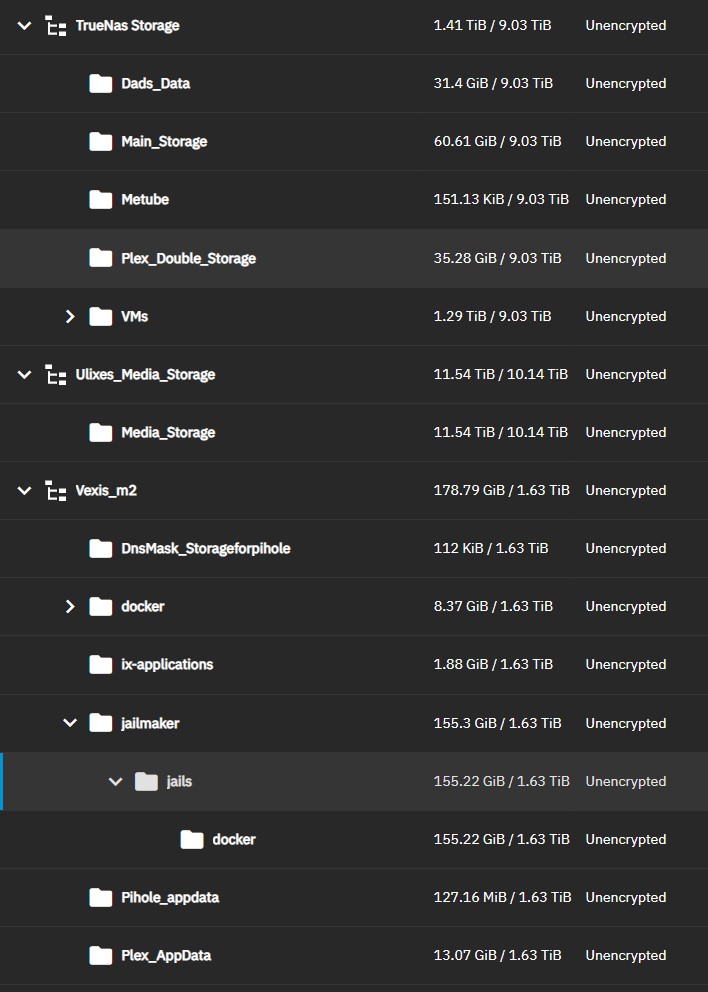
Here’s what things look like from a top level. Each bullet and sub bullet is its own dataset
Archive: Cold storage for any files from prior institutions, projects, or, jobs
Docker: Per @stux, following along with his tutorial
Jailmaker: Per @stux, following along with his tutorial
Library: dataset for various shareable media. Subdatasets are self-explanatory
Movies
Shows
Music
Video Games
Memes: it’s own top-level thing. conceptually separate from photos or library contents
Photos: Its own top-level dataset.
Projects: For any actively ongoing work. Contents moved to Archive when complete.
Shared: meant as a personal dropbox-esque network drive. Haven’t opened up to the outside world though. And probably won’t.
Temp: A slush dataset for incoming files, before they get sorted
Users: a dataset to hold user datasets. I wonder if this even make sense to do?
User1
User2
… more as needed
I created each of these datasets with the thought of one day sharing them out with friends and family. However I think the way I’ve arranged and nested some things makes assigning permissions more difficult.
And the more I’ve read about the headaches of opening a NAS to the world, the less I think I’ll do it.
I’m not sure what I would do differently if I had to do it again. I like having granular datasets for each of my library types because I can choose when how and where they get backed up (if at all).
If anyone wants to give their 2 cents on a dataset makeover, I’m all ears.
I hear you re: opening TrueNAS up to other users ‘outside’. If you want to make a share available over the internet to family or friends, there are a lot of things you have to do to create the necessary protections to ensure only those people can get to it.
I had a similar idea: create a temp dataset that is like an ‘Inbox’ for all unsorted files or files you haven’t yet decided the final resting place for.
I have two datasets to keep it simple. One huge one for media and one for documents. Since the docs dataset is only using 1% of 3TB, that’s where my system dataset pool went. This has served me well for a few years now.
16 x 1.2TB 10K (2.5") internal as RAID10 - ONE dataset, NFS used for XCP-NG virtual disks.
12 x 6TB 7.2k (3.5") in a 3PAR SAS shelf as RAIDZ2 - ONE dataset, CIFS for media and VM backups.
I have only a few datasets. I used to have more but realized that I was over complicating things. My datasets:
apps
home
jailmaker
shared
apps is where I create a new directory when I add a new stack to portainer
home is my truenas home directory (quite small)
jailmaker is for all of the data associated wth jailmaker and the jails I have (especially docker with its root filesystem)
shared is for all of the data I share internally and externally - media (music, photos, videos), and directories for home users who use the local share from their computers
I’m coming from a synology nas background which is just easy. I’ve wanted to roll my own for years and give TrueNAS a go, but I’m curious about some things that I can’t find any answers too. In DSM you create shared folders and each of those shares get whatever permissions you set. Are TN datasets the same as a synlogy shared folder? I have folders for different types of things such as Media, which hold all movies and tv shows, photos, operating system ISO’s, Games disc backups from the days of old etc etc
Somewhere in this conversation it was said that datasets are generally used for high-level storage. What does that mean and what would be an example of both high and low-level storage?
I’m essentially trying to recreate my synology on my TrueNAS system, but if there is a better way of doing things I would love to know what it is.
The same no, but your use of shared folders in DSM will map to datasets in TrueNAS.
Other reasons to create further datasets rather than throwing all data in one big datasets would be to adjust settings to the data being held (recordsize, compression, encryption, etc.) .