I’ve been reading jro’s various posts and personal website trying to learn as much as I can about DRAID. As I start to learn more about DRAID, more and more questions have come up when I think about things.
The confusion for me seems to be that, because of the redundancy groups present interior to a DRAID VDEV, it has properties not unlike a pool while simultaneously being a VDEV.
For example, a hypothetical DRAID2:8:48:2 is created. Internally, with the redundancy groups, you could visualize this as something akin to 6x RAIDZ2 VDEVs of 8 disks each, with 2 hot spares. They obviously aren’t exactly the same, but I think close enough for illustrative purposes.
A traditional RAIDZ2 pool created with the same layout could, in theory, sustain 12 device failures (a highly unlikely scenario, but possible) and remain online provided the failures were evenly distributed amongst the VDEVs.
However, with DRAID2, you can sustain 2 device failures. Any more are guaranteed to take the VDEV offline.
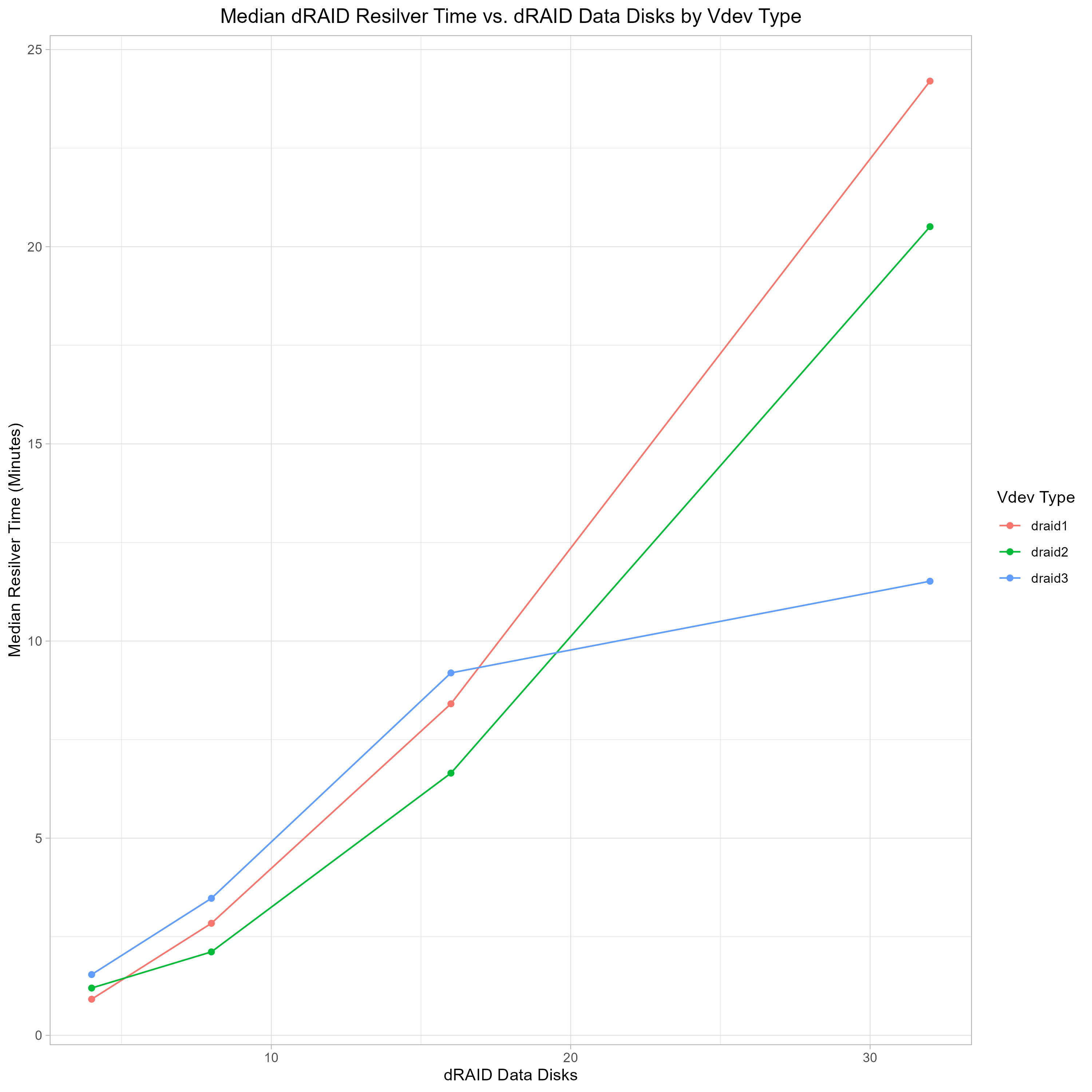
So the question is, internal to the DRAID VDEV, what purpose do the redundancy groups serve? As an extension to this question, what are the consequences of wider redundancy groups within a DRAID VDEV? If I were to change the above DRAID configuration to something like RAID2:16:48:2 what are the consequences of that choice?
It doesn’t change the number of maximum device failures that can occur.
The percentage of space dedicated to parity data is significantly decreased, resulting in more usable capacity. How is this possible without negatively impacting the reliability of the pool?
Because of DRAIDs lack of partial stripes, the minimum stripe size becomes 64k instead of 32k. Depending on the type of data store on the pool this could be a significant overhead if you were to be storing, say, millions of tiny files.
Overall decreased performance of the VDEV.
Any input would be appreciated. Thanks.