So I’m on Dragonfish-24.04.2 with GTX 1070Ti and been playing around for a week or two. Probably the most annoyng issue I have, is random GPU detection. I’ve searched a lot, but couldn’t find any reasonable explanations.
When I want to install any app, that allows GPU selection, there are 3 dropdowns. I have nVidia GPU enabled. Usually nVidia dropdown shows only the 0 option to select:
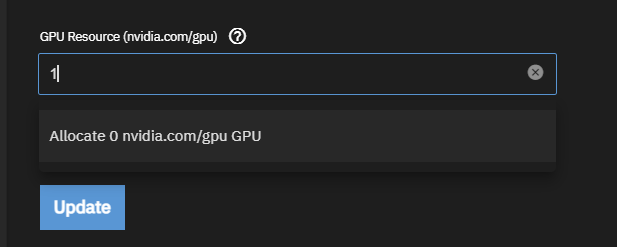
But if you keep refreshing and if you’re lucky, occasionally you get even 5 of them:
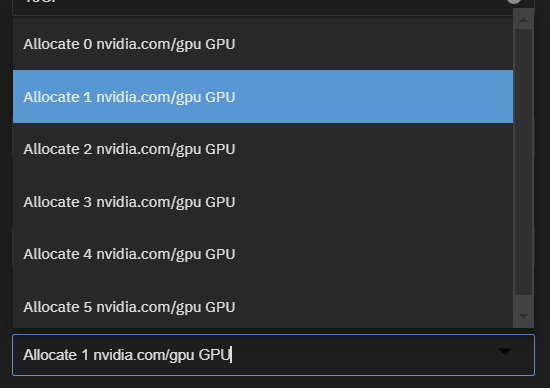
You get that literally by just refreshing the page countless times…
But that also doesn’t make sense, because there’s only one GPU on my machine. If I select anything more than 1, I get an error. I’ve seen on the net some say it’s the core count, which you assign to a specific app, some say it’s actual GPU count… I have 2 apps using GPU - Plex and Jellyfin - both have assigned 1 from GPU selector and both use GPU as expected when transcoding media
If you fanally manage to get GPU assigned to the apps, deployment is a nightmare…
After app service or system restart, when all apps are deploying, some of them usually get:
Allocate failed due to no healthy devices present; cannot allocate unhealthy devices nvidia.com/gpu, which is unexpected
But this happens for the apps, which don’t even have any GPU assigned. The ones which have GPU assigned, sometimes get:
0/1 nodes are available: 1 Insufficient nvidia.com/gpu. preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod…
Sometimes (very rarely) stopping and restarting deployment helps. What usually (still not always) helps - in Apps advanced settings disabling and re-enabling GPU support… Then apps with assigned GPU almost always deploy successfully. Ones without the GPU still might get the Allocate failed error. In that case either re-deployment helps or just leaving in the deployment state for ~10 minutes until it manages to deploy…
Would really appreciate any insights about this behaviour. I find myself spending much more time disabling/enabling services and constantly re-deploying apps than actually setting up my environment…