Hello! I’m using fresh installation of Truenas Scale (Dragonfish-24.04.1.1).
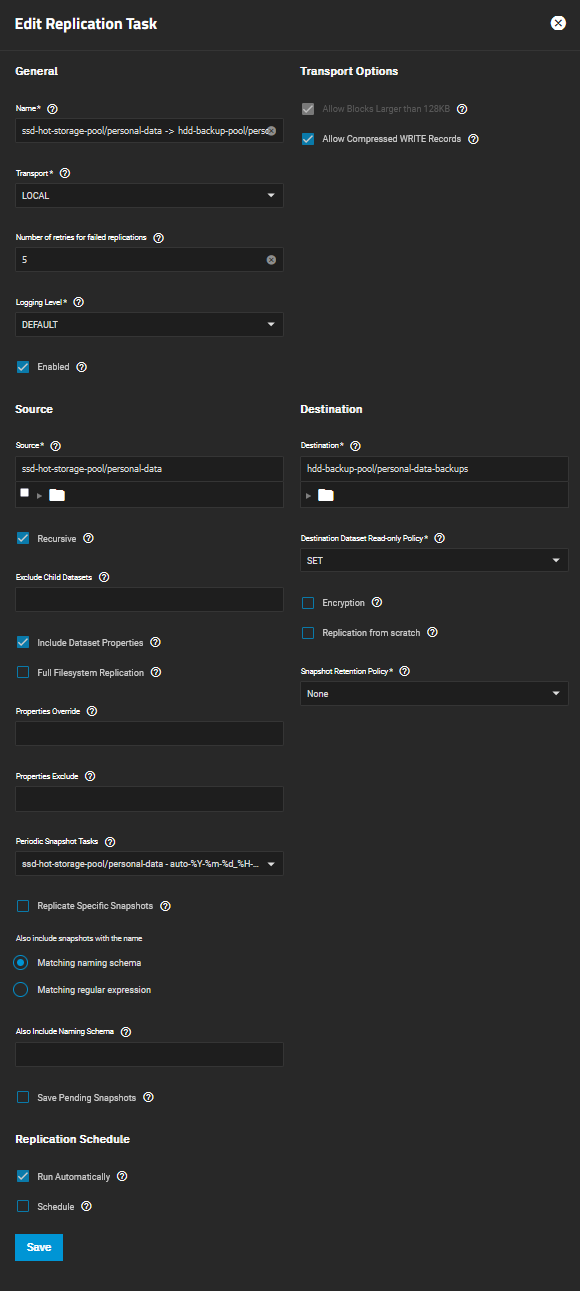
I have two datasets that reside on different pools, one for data (private-data dataset) and the other for backups of that data (private-data-backups dataset). Both pools are encrypted and I made sure that the datasets simply inherit encryption settings from the respective pools. After configuring datasets, I manually (i.e. not using the wizard mode) created local replication task (private-data → private-data-backups) and made sure that the encryption checkbox in task settings is off. When I saved the task, private-data-backups was unlocked and had its encryption settings inherited from the pool, but when I started the replication job private-data-backups became ‘encryption root’ and ‘download encryption keys’ button appeared in the replication task. Is this expected behavior? I’m a bit confused and don’t understand why this happens. Would really appreciate some elaboration. Thanks.
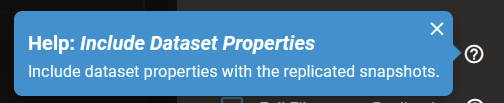
You have “Include Dataset Properties” checked. This includes the (modifiable) encryption properties[1] of the source dataset. The end result is that the destination dataset will require the same key/passphrase (as the source dataset) to lock and unlock it.
Encryption itself, the cipher, the key width, and the Master Key are permanent, set once during dataset creation. The “encryption properties” that are set/changed on the destination dataset are “modifiable”, which include the User Key (related to keystring/passphrase), iterations, and the inherited (or cleaved) “encryptionroot”. ↩︎
Compared the encryption keys and private-data-backups does indeed have the same encryption key as the source (private-data) dataset. Totally makes sense in retrospective. Thanks!
The “encryption properties” that are set/changed on the destination dataset are “modifiable”, which include the User Key (related to keystring/passphrase), iterations, and the inherited (or cleaved) “encryptionroot”.
So I can simply unlock the dataset, check ‘Inherit encryption properties from parent’ and everything is going to be back to ‘normal’? Do I have to make another snapshot of the source dataset and/or re-run replication task in order for data to get re-encrypted with the inherited key?
Until your Replication Task runs again, in which it will immediately revert those changes, setting the encryption properties to be the same as they exist on the source dataset.
Encryption is not a snapshot property; even if it can be listed as such (deceivingly) via the zfs list and zfs get commands. Encryption applies to the dataset-at-whole.
If you insist that it doesn’t touch the destination’s encryption properties, you can write them in the “Properties Exclude” text field of your Replication Task.
Oh, I meant unlocking the dataset, changing its settings and then also changing the replication task settings. Forgot to mention the last part
Out of curiosity, to understand how it all works better. Just tried unchecking ‘Include Dataset Properties’ and re-running replication task. The task didn’t set the encryption properties. I suspect that’s probably due to the fact that there were no new snapshots since the initial replication (and thus the task gets ‘skipped’). Or maybe due to the fact that since the ‘Include Dataset Properties’ is (now) unchecked, no properties are going to be copied, and I’d have to first ‘revert’ the encryption settings manually in order to achieve the desired state. Or due to both?
Correct. If there’s nothing new to send, nothing happens on the destination.
You probably don’t want to uncheck “Include Dataset Properties”, as this means all properties will be inherited from the destination’s root dataset. (Other than encryption, I don’t believe you want that to happen.)
You can simply add encryption into the text field labeled “Properties Exclude”, and that should take care of it, even after scheduled replications. (All other dataset properties will remain the same as they exist on the source.)
If it helps, think of a ZFS replication as a two-parter:
Sending actual blocks of data (via full/incremental snapshots)
Issuing ZFS commands on the destination (remote or local), such as setting certain properties
Number 2 is not really front-and-center when people think of replications, but it does happen. For example, if ZFS (whether locally or via SSH) discovers “Hey wait! It’s not using X property!”, it will issue a zfs set command against the destination dataset to match the source’s property.
EDIT: In fact, a replication is not even required to do #2, whether locally or remotely. You can issue zfs set / inherit commands over SSH, for example, without sending snapshots / blocks of data.
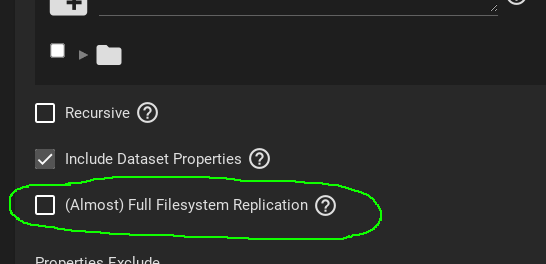
At first, I was thinking about that, but then got quite hesitant as there is no list of valid values or dropdown to choose the properties from. These are the properties you get from zfs get, right? Or something else entirely (a regexp maybe)? Just queried the source dataset and there is also the encryptionroot property which I should probably exclude too? It contains a very specific value - the name of the pool.
The hint on this one is even less helpful, I must say. It kind of suggests that these properties are dealt with on per-file basis which leads to confusion (these are dataset properties after all?):
You’re right, excluding encryption properties is much more preferable and I’ll go with that (after I figure it all out ).
It’s confusing, but the only relevant property is encryption. The rest are either non-inheritable or non-settable, yet are changed accordingly when encryption is inherited.
In other words, on the destination pool, have the dataset inherit its encryption properties from the root dataset using the GUI (since you desire the it to use the pool’s root dataset encryption key), and then add encryption to the list of excluded properties in the task page.
Just for giggles, when it was pointed out that in Core, checking the box “Full Filesystem Replication” doesn’t actually do a full filesystem replication, guess what was changed to resolve this issue?
Damn This is the kind of magic I normally prefer to avoid. Good thing you got the ‘recipe’ because I certainly wouldn’t figure all that out on my own (not from the get go for sure). I’ll try excluding the encryption property. Really appreciate all the help!
Reporting the progress. I’ve been playing with different dataset properties, replication task properties, restoration to different datasets and such, kinda forgot what exactly I was doing along the way and decided to reconfigure everything backup-related from the clean slate. Removed datasets, shares, replication tasks - everything that’s not the source-dataset-related and recreated them. After that, I ran the replication task and It appears that (in Scale?) ignoring encryption property when using Include Dataset Properties doesn’t work as described above (anymore?). The target dataset got encrypted with the keys from the source dataset. I’ll probably do some more experiments on a test dataset and see if there is a way to ignore encryption properties, but, for now, I ultimately wasn’t able to. I haven’t tried excluding encryptionroot alongside encryption yet, maybe that’ll work.
Edit: Created a test dataset and added both encryptionroot and encryption to Properties Exclude of Include Dataset Properties. The target dataset still gets encryption properties of the source dataset. Investigating further
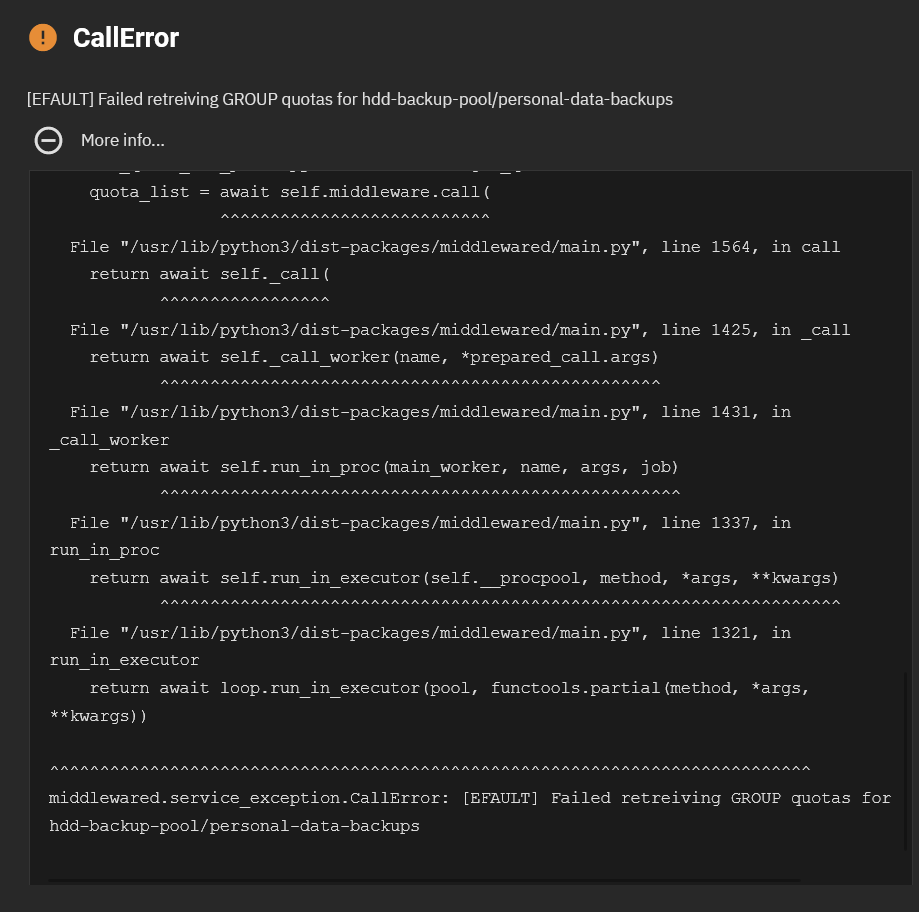
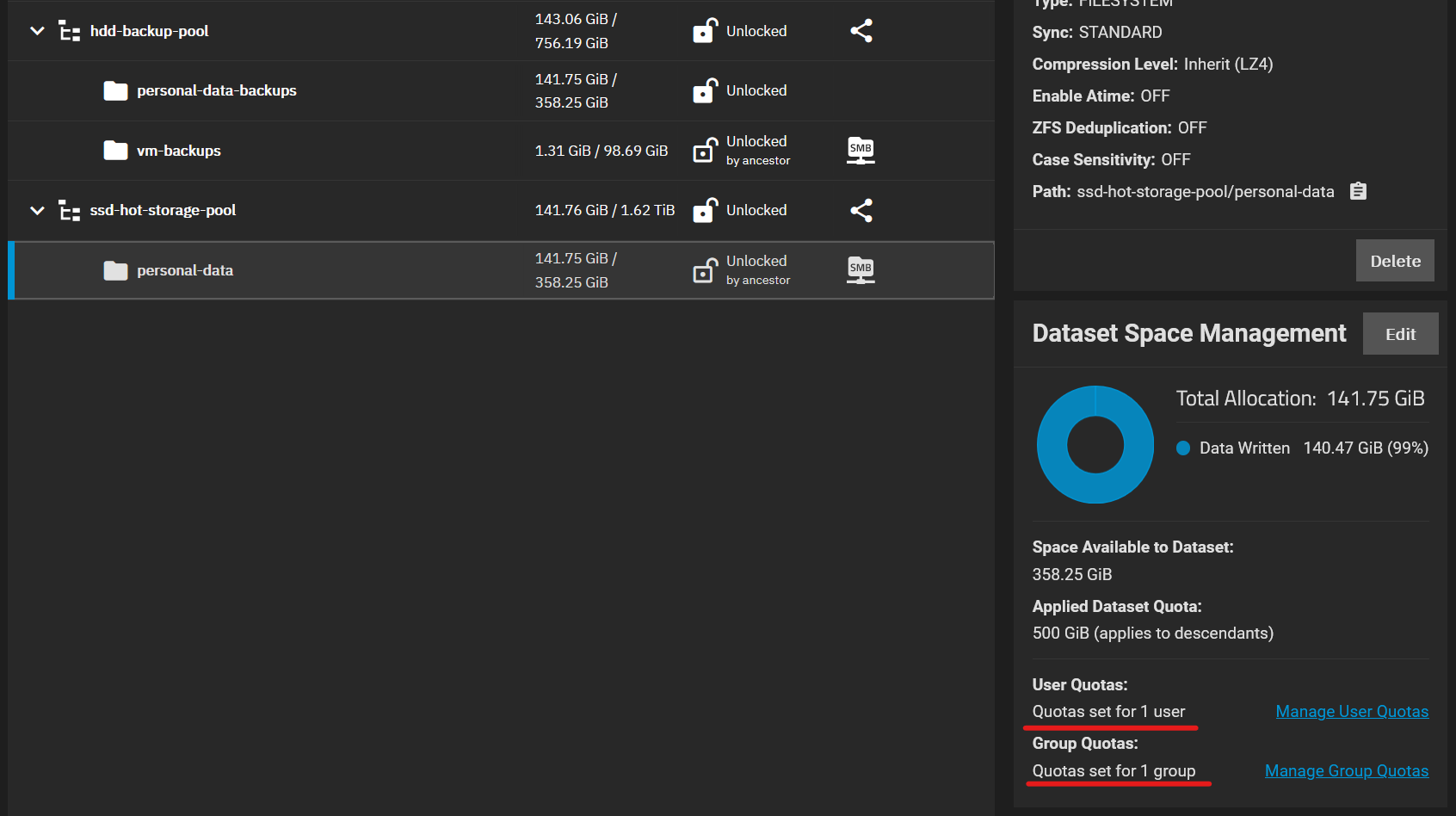
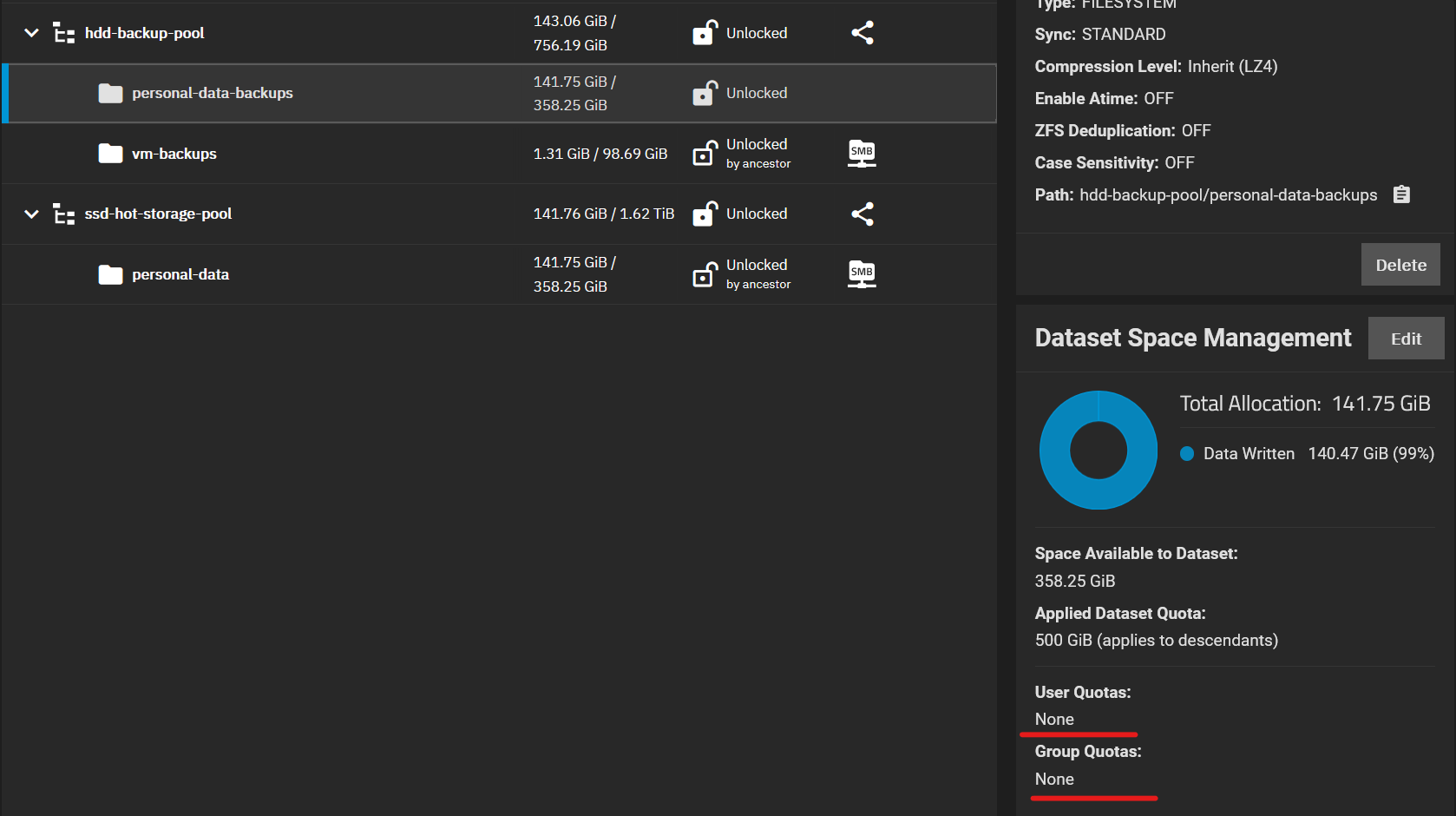
Also, I’ve noticed a weird bug. Or maybe that’s a configuration error on my part? After replicating a dataset, clicking on the target dataset for the first time gives me Unable to get quotas for the user/group error (writing from memory, not the exact error). And while all the other datasets/pools show that the quotas are configured for exactly one user and one group (although you can’t see them when you click the link), this target dataset shows no users and groups in quota configuration widget. Not sure what to make of it. It’s also quite weird that while some datasets/pools do in fact have quotas configured, the ones that don’t still report that the quotas are configured for exactly one user and one group. Maybe it’s just a UI quirk rather than the actual bug, the quotas seem to work as expected.
Honestly, I couldn’t tell you why. I assumed that “Properties Exclude” in the GUI invokes -x on the zfs recv side.
Invoking zfs recv -x encryption prevents the source stream from changing the destination’s encryption property, which will leave it “as is” (inherited by the destination’s parent.)
The GUI feels like a “black box” at times, where it’s not clear what is happening under-the-hood, unless you comb through the source code.
While the dataset is unlocked?
EDIT: I think I know what’s going on. (And it has to do with “raw” streams. I’m testing something right now.
I think at one point I’ve got the error when the dataset was already unlocked. But this time the dataset was locked and the first replication was still in process.