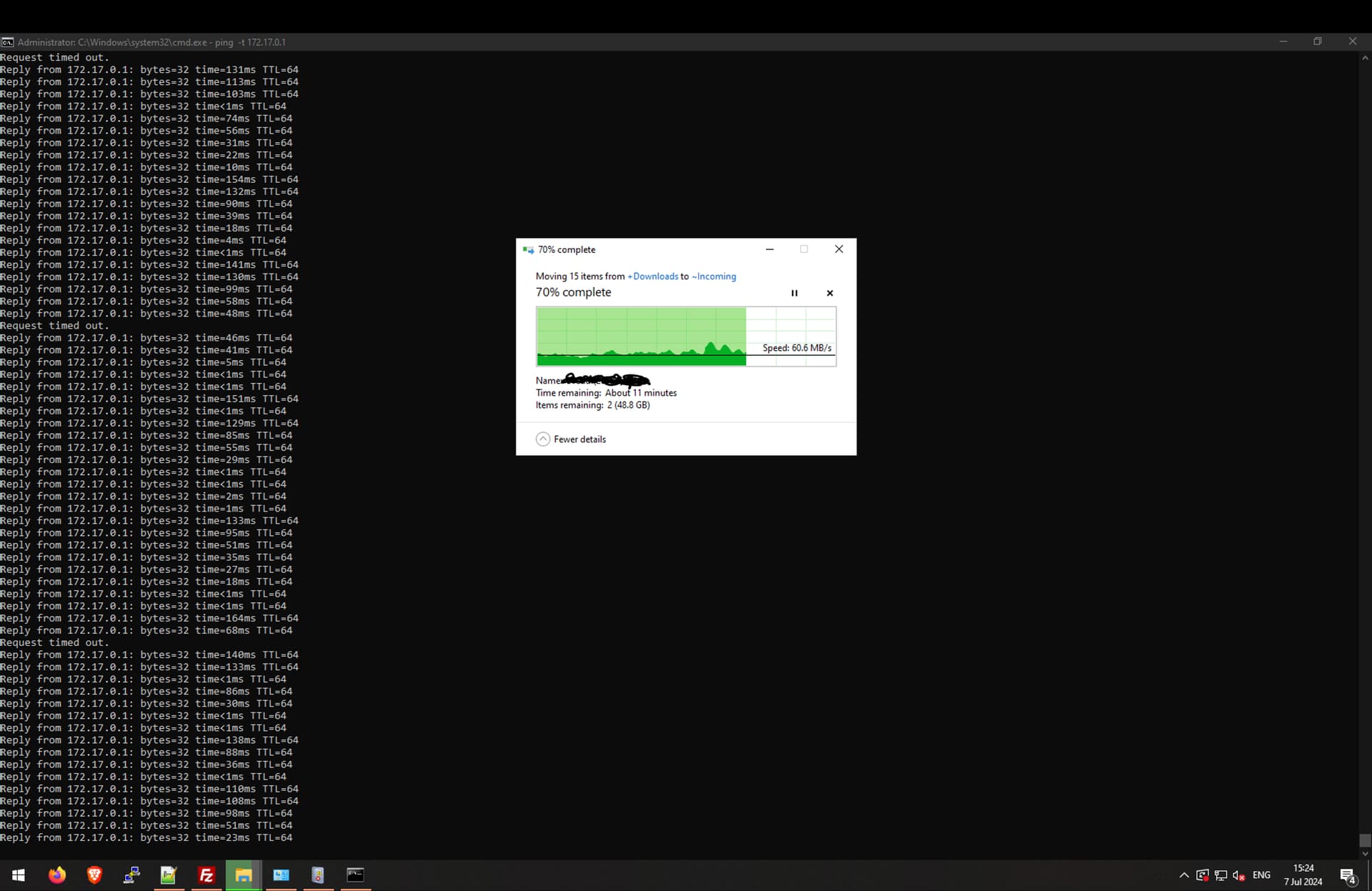
I’m trying to figure out why my TrueNAS SCALE Dragonfish server is causing a Windows VM to hang and then resume, it just temporarily freezes and keeps working whenever i’m downloading files from a remote FTP server (unrelated/internet) and downloading the files, straight to an SMB mount on windows to the actual server itself, the C drive does not get used in this scenario at all, all the machine is doing is sitting in the middle.
Now the C drives are running on a separate pool. POOL-B that one comprises of 5x2TB NVMe from Crucial 2TB while the POOL-A comprises of 8x14TB Exos, I have auto trim enabled on pool b and sync disabled on both (server has a ups set to shutdown vms and the host itself when battery is low) in case of power outage so perfectly safe.
Another important piece of information about the Windows VM, it’s Windows Server 2022 and I have a Radeon Pro W6600 as a passthrough GPU, the host itself is running on an older Quadro P620.
Server Specs:
AMD Ryzen Threadripper 1950X
128GB DDR4 3200MT/s (running at 2966mt/s due to memory controller limitations)
2x Samsung 860 Pro 500GB ZFS BOOT (Mirror)
5x 2TB Crucial P5 Plus ZFS POOL-B (RAID-Z1)
8x 14TB Seagate Exos ZFS POOL-A (RAID-Z2)
i’m not sure where to start troubleshooting this, also doesn’t help that I want to switch this particular VM to Ubuntu 24 ASAP but I would like to figure out what’s going on before I do that.
Nothing relevant to this case in event viewer i also tried replicating the problem and monitoring in real time nothing showed up with correct the timestamp so doesn’t seem like it’s something windows is aware of at least.
If I download to C drive does not affect the VM in any way, same for all the other VMs running in this system they’re not affected, so it only occurs when sending data to the HDD array on TrueNAS directly via SMB.
This is a little update, so here I am pinging the default gateway in this specific network which is an unrelated pfSense physical machine, you can see the file transfer is going to the truenas host itself at 50MiB/s usually I get around 500-600MiB/s from C to the array, the physical nics are all Intel X520-DA2 based with 10G SFP+ and local shouldn’t matter since it’s a linux bridge and VirtIO and yet I’m seeing tons of packet loss and the freezes may very well be just packet loss that over RDP feels like a system freeze. And the IPv6 stack looks the same, and so does pinging the TrueNAS host itself.
Pinging from the TrueNAS physical host (using the shell) to the pfSense box I get 0.05-0.06ms ping so as expected.
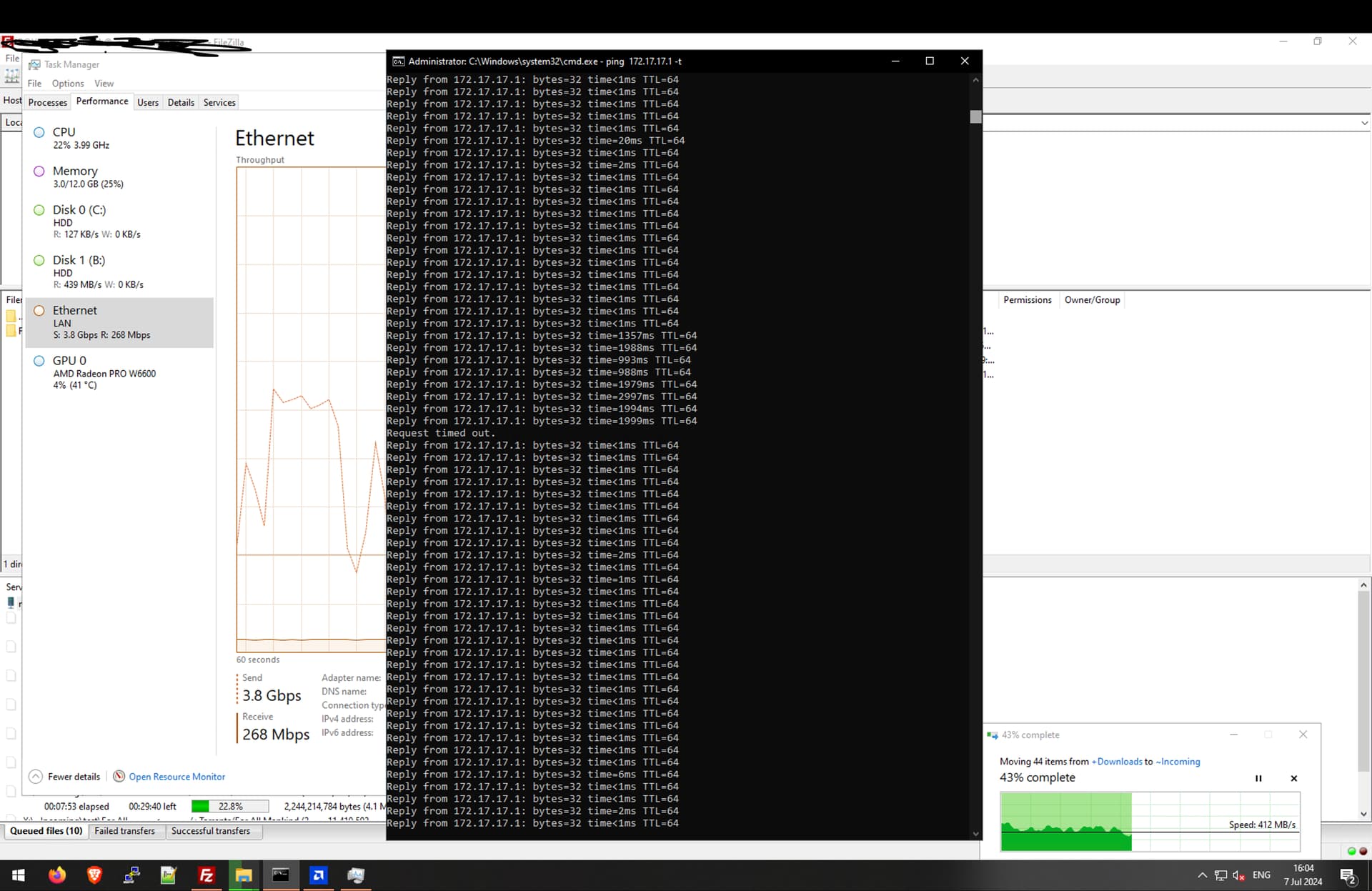
I’m pinging the TrueNAS host from this vm and another vm running on the same system and even though they are running the exact same OS and VirtIO drivers the problematic VM is having major latency without even much traffic going through.
I’m going to remove the GPU passthrough and see if anything changes other than that i’m out of ideas but at this point i’m convinced the problem is at the virtualisation layer as other vms within the linux bridge are running fine.
If they are identical, then what about available storage in each VM and looking at the SWAP Space? Do you have the same amount of RAM allocated to each VM? These are the little things that can make a difference.
How about disabling other VMs you might have or services.
Are you using Dragonfish 24.04.1.1 ? It may sound like a stupid question but you have no idea how many times we are making assumptions. Don’t let us.
So here are more test results, if I remove the GPU the vm feels fast, if I attatch the GPU it feels sluggish I also get a warning saying the GPU is not isolated even though it is, when I add them to the VM the drivers install normally.
It took a long time for the problem to start happening I was getting a straight 500-600MiB/s transfer speed (moving data from C drive to TrueNAS) but eventually it just froze and the latency shot up as you can see.
As for the question from joesschmuck they’re both 12 GiB and the RAM use is negligible, also there seems to be a relation to more network activity in general, more connections and more data throughput seems to hit hard.
I also feel like something in TrueNAS is ‘filling up’ like some sort of buffer and when that’s full cannot cope with the VM load, even though ZFS should be writing straight to disk and even if it were to completely slow down it shouldn’t affect the network stack of a virtual machine as they’re not related.
Version:
Dragonfish-24.04.1.1
As for turning off other VMs this machine is basically a ‘production’ server in terms of home services so If i turn off other vms i can’t work and a lot of smart things around my house will stop working it’s an essential machine here that cannot have problems or be stopped randomly and unfortunately currently i’m not able to move that out to another machine either as the lab needs a major overhaul and upgrades to power and cooling etc and my only other machine there right now is a 3960X with 256GiB of RAM but it’s running Proxmox and is quite power hungry with 2 gpus so that one has to wait for AC upgrade and it’s a workstation for gaming not really for core services that run 24/7, and even then exporting and importing from TrueNAS Scale into Proxmox isn’t a straightforward task despite the VMs being technically quite similar and last but not least, it should work as is unless the virtualisation side of TrueNAS scale has some issues i’m not aware of but other than this VM specifically everything else has been running fine.