We are looking at getting a TrueNAS system with 16 data disks, with half for redundancy. 18-tb magnetic 7200rpm drives.
Most basic, and performant, way to do that is 8 VDEVs each a mirror. Fair enough, and likely how we’ll do it. The only thing that worries me is that gets us a situation where a 2-disk failure could cause data loss in theory. I realize it isn’t super likely, but it can and does happen where two disks fail in the same set.
So, my though it what about a set of 4 VDEVs with 4 disk raidz2 in each? Same 50% loss to parity/mirror but now each set can lose 2 drives without data loss which makes the probability of data loss much, much, lower.
My question is if this is a bad idea and if so, why?
Backups are a different issue from availability. Yes, we have a backup solution for our data. However, reconstructing things from backups takes time and ultimately it is preferable not to do that if at all possible. To my thinking, backups should be a last resort, not a first one, systems should be resilient enough to hopefully not need the backups, they are just the incase everything goes REALLY wrong.
Another option would be 5x 3-way mirrors with a spare shared by every vdev. That drops you to only 5 drives of usable instead of 8 but here, you can loose any 2 drives instantly and still a third one once the spare is re-silvered.
Despite all of this, as @Stux mentioned already, backups are not optional. No matter how robust your server will be, a single server is always a single point of failure. Every drives will be destroyed by the same fire or water or the same pool will be damaged by human error or other logical threat.
I mean ideally I’d like the same downtime we’ve had with our NetApp which has been 0, it has never gone down for 5 years.
NetApp uses what they call RAID-TEC which is basically RAID-4 extended to 3 parity disks. Has the performance downside of being limited by the speed of the dedicated parity disks, they fix that with caching.
Now that level of reliability is not a requirement, as I know you can’t guarantee that no matter what someone claims, but I want to keep it as reliable as possible. If we go the TrueNAS route, it’ll be an HA system from iX.
3-way mirroring costs more disks than I’m willing to give up, we’d need 24 disks just for data, never mind the spare, which would be more than the chassis could hold so we’d need a shelf and of course part of the reason for switching to TrueNAS is to try and keep costs reasonable. That’s why I was considering the 2x2 idea. Same 50% storage penalty as a mirror, but more resilience.
No it’s all file storage, mostly SMB, some NFS. It’s a big place for researchers to store their data and have a high confidence it’ll be there when they need it again.
One of the things I worry about with a larger raidz array, performance aside, is resilvering in the event of failure, I’m not sure how efficient ZFS is at a rebuild. NetApp gets around the rebuild time issue by using dedicated parity disks, since they are dedicated the rebuild process is a lot simpler, is only write intensive on the new parity disk, and thus completes pretty quickly.
My concern is if a rebuild takes too long and is too intense, it can increase the chance of drive failure of another drive in the array. I don’t know much about ZFS and how efficient its rebuild process is. We are looking at 18TB magnetic drives, so not the fastest things in the world, in relation to their size.
The plan proposed by iX is just mirrors, 16 data disks total, with one hot spare and one cold spare. I’m just considering other options and wondering if anyone had experience with them. The 3x5 z2 or 2x8 z2 are also options I am open to, particularly since if we expand the storage it’ll be quite a few disks, we aren’t going to just add two, it would be a whole shelf probably.
ZFS uses fairly efficient resilvering. It only resilvers actual in-use blocks, and I believe in a RaidZ2 disk failure situation all the other disks in the vdev are read similtaneously to rebuild…
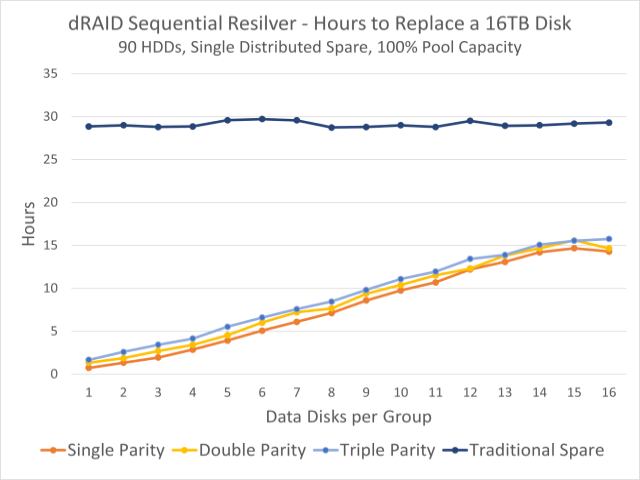
I will do an in-depth look at dRAID. You are right it looks like it was designed for a scenario like this, though I’ll have to see how appropriate it is with this number of drives (it sounds like it was designed for really large arrays) and I’ll also have to consider how this would impact expandability of storage, as it sounds like we would have to add a whole populated shelf at a time and not just 6 disks or the like. Might be worth doing though as usually when we add storage we add a bunch at once.
I’ve never seen a single-node system have zero downtime as far as users are concerned. Many OS patches require the system to be restarted, and that means downtime with only one node.
Most high-end, high-availability storage systems use distributed storage and a “special sauce” software that allows arbitrary redundancy levels on the equivalent of a ZFS pool level. The difference is that most of these systems (e.g., Isilon) don’t require disks to have a specified redundancy (i.e., mirror, RAIDz2, RAID5, etc.)…the redundancy is completely on a block level. The system does know about physical disks so that it can spread out the copies of the data.
I mean the NetApp isn’t single node in the true sense, it’s an HA system with two controllers (like the one we are looking at from iX) but yes, it really has done zero downtime. When you patch it controller A does a takeover, where it takes control of all disks, they check to make sure it is all good, controller B updates the code, comes back up, they get back in quorum, disks are given to B, A patches and reboots, then they are redistributed and the system goes on with normal operation.
We didn’t even have an availability outage when a RAM stick went bad on a controller and it crashed. Other controller took over and things went on as normal, from a user standpoint.
Again, this isn’t a requirement, I’m not saying the TrueNAS system HAS to be this resilient, it is cheaper, we are making a tradeoff. I’m just saying I’d like to engineer it to be as reliable as I can.
Particularly since there’s a big difference between an availability outage due to a patch and one due to restoring from backup. A patch you are out for maybe 30 minutes on the long end, and you get to choose when. Restoring 100TB from backup is a LONG process. That’s days of downtime.
I just like to try and have systems where going to backup is basically something that never happens, rather than something that happens if there’s a failure. I want there to have to be multiple failures, if possible, before going to backup because usually the failures can be remedied before more happen.
I prefer true multi-node systems with data replication over multiple front ends that connect to the same back-end disks, since you get more theoretical performance, and with a filesystem like gluster or Ceph and a native driver, you get more real-world performance, too. But your NetApp is really multiple systems in one box, so you can have 100% uptime. IIRC, not all NetApp installations are this way.
Another advantage to distributed data is that the “100TB restore” is very unlikely to happen, as that would require a whole node to go up in smoke (every disk fried). It still wouldn’t require any downtime for restore, though, as the distrubuted filesystem will rebuild it.
I was part of a project to back up 2.7PB of data to the other side of the country, in case the original site fell into the ocean (California near the San Andreas fault). Our original proposal was to replicate the server structure minimally, but even that was too expensive, so all we did was back up to tape, despite explaining that a restore would take months after they got new hardware up and running.