ZFS has a feature called “bookmarks”.
It’s had this feature for a long time. You don’t use them because you probably didn’t know they exist. If you did know about them, you probably brushed them off as pointless. To make matters worse, they’re not (currently) exposed in the TrueNAS GUI.
This guide will:
Give you a brief historical context about ZFS bookmarks- Give you an overview of what a ZFS “bookmark” is
- Give you a quick example of creating a ZFS “bookmark” in the command-line
- Share a little-known secret and powerful feature that actually has practical use!
ZFS Bookmarks: A Brief History of <Stephan Hawking reference that rhymes with “Time”>
Ever used a search engine to find an interesting piece of trivia on the internet?
Ever wondered how historical records are preserved?
Ever found yourself thinking “How does Google/Amazon/Apple handle so much data?”
The answer: ZFS bookmarks.
What most people fail to understand is that beginning in the early 1980’s, the internet’s backbone was constructed of ZFS bookmarks, intertwined at all the major da-
Moderator edit: Winnie. Cut it out. You need to stop trolling everyone with factually incorrect information and outright lies.
Moderator edit 2: This guy just tried to Venmo me $40 USD to “make it all go away”. Sorry, that’s not how this works.
What is a ZFS “bookmark”?
You might know what a ZFS “snapshot” is. (At least a bird’s eye understanding.)
A “snapshot” is an immutable, read-only copy of a dataset (“filesystem”) as it existed at a certain point in time.
It references blocks of data that may overlap or differ with another snapshot (or the “live filesystem” itself). The difference between two snapshots is the “delta”, and this is essentially what is “sent” when you issue an incremental replication.
Okay, but what is a ZFS bookmark?
A “bookmark” is the “tombstone” of a particular snapshot, regardless whether or not the snapshot even exists!
If you destroy a snapshot, its bookmark remains. (Assuming you created a bookmark for it at some point in time.)
A bookmark consumes nearly no size at all. (Might as well say “zero size”!)
What information does a bookmark contain?
- a creation date
- a GUID
- a transaction group number (“TXG”)
- a reference size (how much data the snapshot had referenced)
The most interesting (and useful) properties of a bookmark are its creation date, GUID, and TXG… which are all exactly identical as the snapshot from whence it was birthed! (Even if you created the bookmark months or years later.) You’ll see why this is important later on.
You can think of a bookmark as the “ghost form” of a snapshot, with enough (important) information that is shared with the original snapshot.
While a snapshot references blocks of a filesystem or volume, a bookmark references no blocks, yet retains enough “meta” information for its own practical uses.
Uses of a ZFS bookmark:
- A zero-size placeholder for destroyed snapshots, retaining some information of the filesystem at the time (e.g, “referenced space”, “creation date”, “GUID”, “name”, “TXG”)
- A way to “mark” important snapshots, even if they still exist
- A failsafe of preserving your ability to do incremental replications, even if the source dataset no longer has a base snapshot (which only exists on the destination)
Creating and reviewing ZFS bookmarks (command-line)
Creating a bookmark is fairly simple. Just use this syntax:
zfs bookmark mypool/mydata@snapshotname mypool/mydata#bookmarkname
![]() While you can use a different name for the bookmark, it’s more intuitive to keep the bookmark’s name the same as the snapshot’s name.
While you can use a different name for the bookmark, it’s more intuitive to keep the bookmark’s name the same as the snapshot’s name.
Here’s an actual example.
First, let’s look at some important information about a snapshot:
zfs get createtxg,guid,creation,refer mainpool/media@backup-2024-03-01
createtxg 306824
guid 42678828729112662
creation Fri Mar 1 00:00 2024
referenced 2.46T
Now, let us create a bookmark from this snapshot:
zfs bookmark mainpool/media@backup-2024-03-01 mainpool/media#backup-2024-03-01
Let’s now look at the bookmark’s properties, and see if they are exactly the same as what they were on the snapshot:
zfs get createtxg,guid,creation,refer mainpool/media#backup-2024-03-01
createtxg 306824
guid 42678828729112662
creation Fri Mar 1 00:00 2024
referenced 2.46T
They are exactly the same! ![]()
Let’s have some more fun.
To list all bookmarks in a pool:
zfs list -t bookmark -r mainpool
To list bookmarks of a specific dataset:
zfs list -t bookmark mainpool/media
That’s all well and good, but besides creating a “ledger” or handy annotation of bookmarks with the immutable properties of (destroyed) origin snapshots, what’s the real benefit of a bookmark?
ZFS Boomarks’ Vindication: A “fallback” for incremental replications, in situations where you lost the source’s “base” snapshot
As you might know, in order to send an “incremental” replication from a source dataset to a destination dataset, only the “delta” is transferred. In other words, only the differences between a base snapshot (which resides on both sides) and a newer snapshot (which only exists on the source.)
What is required from the destination? A base snapshot, which will serve as the “starting point” for the delta stream to “fill up” the dataset, up until the point of the desired newer snapshot.
What is required from the source? The same exact base snapshot (which will serve as the “starting point” to create a delta stream to be sent over) and a newer snapshot that will serve as the point-in-time filesystem that you wish to be saved on the destination. This delta stream is the difference of data between the source’s base snapshot → newer snapshot.
It goes something like this:
zfs send -i mainpool/media@backup-2024-03-01 @backup-2024-06-01 | ssh remote.host zfs recv remotepool/media
In order for this to work, the snapshot @backup-2024-03-01 must exist on both the source and destination.
It looks something like this:


You again try this:
zfs send -i mainpool/media@backup-2024-03-01 @backup-2024-06-01 | ssh remote.host zfs recv remotepool/media
But it will fail, unable to generate a delta, because the snapshot @backup-2024-03-01 does not exist on the source! ![]()
It looks something like this:

The only difference is that the “base snapshot” is specified as a bookmark. Notice the hash symbol:
zfs send -i mainpool/media#backup-2024-03-01 @backup-2024-06-01 | ssh remote.host zfs recv remotepool/media
It looks something like this:

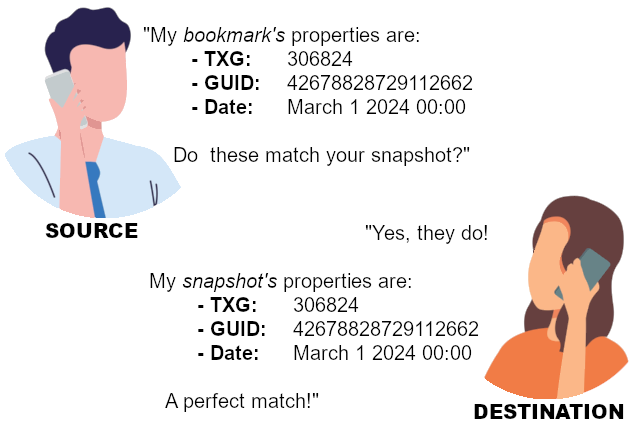

That’s pretty much the gist of ZFS bookmarks.
- They consume zero extra space
- They can be used to denote important snapshots
- They can be used to form a “ledger” of extinct and extant snapshots
- They can be used as a “fallback” for incremental replications if the source’s base snapshot is missing[1]
As it stands now in May of 2024, a bookmark does not support the
-Rflag when used in replications. There is no “technical” limitation for this. It simply hasn’t been implemented, nor is it considered a high priority by the OpenZFS developers. ↩︎