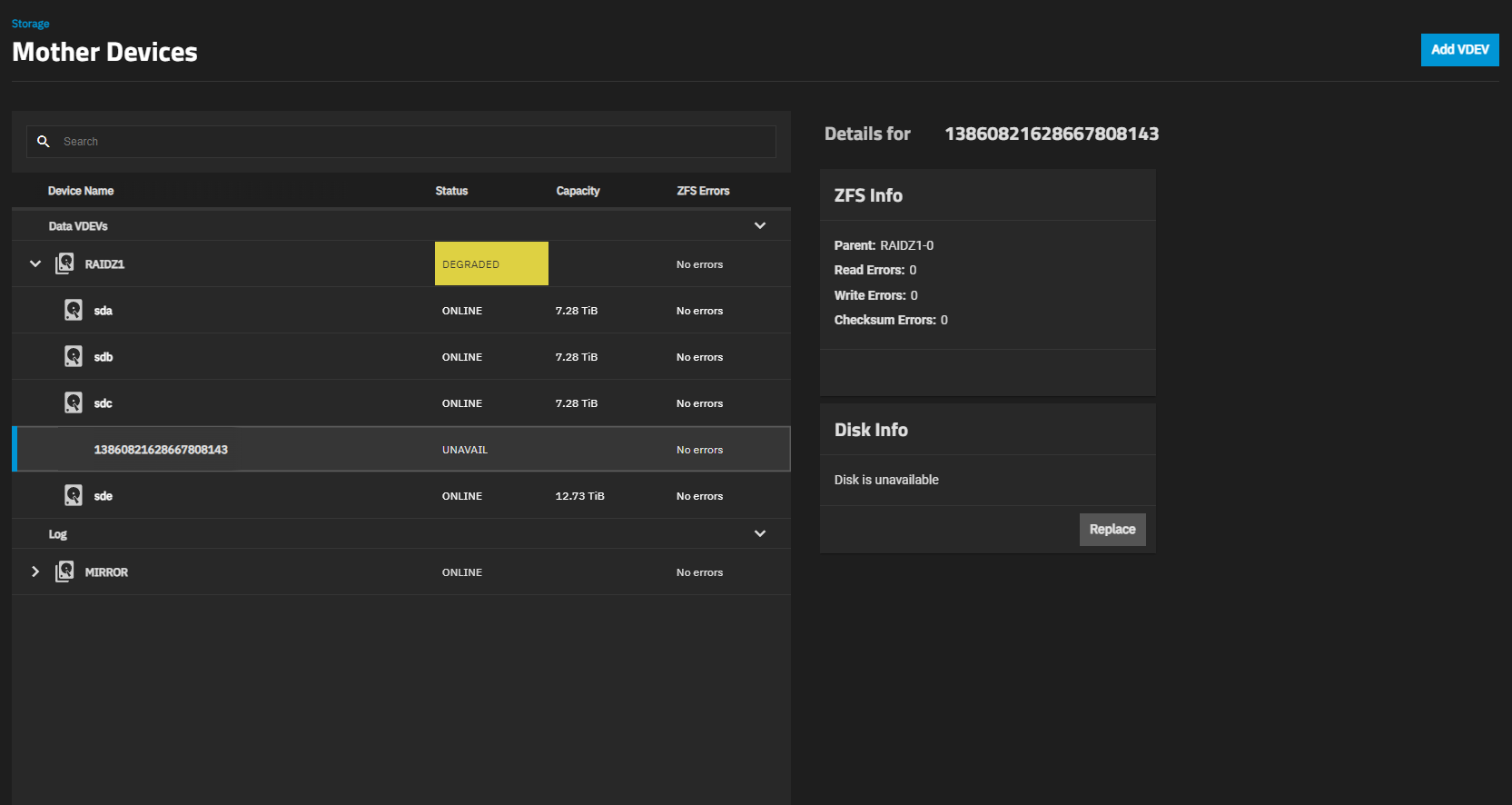
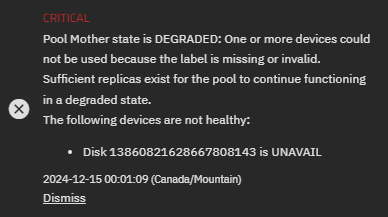
Hello everyone, bit of a green horn to TrueNAS and I have a problem.
While I was expanding the pool, the system ran the automated scrub, and now the system is reporting a degraded state and the expansion is paused. After it finished the scrub, I switched off the automation. Help would be greatly appreciated.
pool: Mother
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J
scan: scrub repaired 0B in 15:06:33 with 0 errors on Sun Dec 15 15:07:30 2024
expand: expansion of raidz1-0 in progress since Tue Dec 10 02:00:24 2024
15.5T / 24.3T copied at 32.5M/s, 63.70% done, paused for resilver or clear
config:
NAME STATE READ WRITE CKSUM
Mother DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
ed4c0028-a16b-4f12-9412-784ea35c2707 ONLINE 0 0 0
9ad18062-9800-4b72-80d6-4601a309149a ONLINE 0 0 0
49d51ca4-bc4a-437a-9b6f-6f072160ab99 ONLINE 0 0 0
bd6710a6-008a-4fa0-8d00-cf75b6019fee ONLINE 0 0 0
178861c9-da20-417f-b415-3b206ca8b1e1 UNAVAIL 0 0 0
logs
mirror-1 ONLINE 0 0 0
dbead5fa-880c-4316-a7e6-6b60508de098 ONLINE 0 0 0
9fc44b1b-5bf1-455e-aec2-512656fa6133 ONLINE 0 0 0
errors: No known data errors
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:25 with 0 errors on Tue Dec 10 03:45:27 2024
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
nvme0n1p3 ONLINE 0 0 0
That’s exactly what happened (well, a minute into the scrub), though the expansion has been running for a few days (the crux of SMR as I’ve sorely learned…)
The SMR drive in question is under a year old.
At this point, I’d be more interested in taking the drive out and count my blessings I’m still able to access everything. Do you believe a reboot is possible without loss of data, given the current state?
I suspect that if you remove a partially expanded disk you will still be degraded even though all disks look fine. Some records had blocks on the failed disk, so those records have 1 less redundant block but in theory you should still have enough blocks for a Scrub or resilver to fix things.
So it MAY be possible to remove the drive and do a scrub and be back where you were before. But removing a drive is not supported, so personally I doubt this is the case. I think it is more likely that…
ZFS now sees itself as permanently having the extra drive, even though expansion was never completed. Removing the drive will remove your redundancy and leave you with a permanent degraded RAIDZ until you can resilver with the new disk to regain redundancy. I would imagine that ZFS would need first to resilver all the blocks that had previously been copied and then finish the expansion.
The absolute worst case is that the ZFS coders never anticipated needing to resilver the expansion disk part way through expansion - and your pool is now in a state where no tools can fully recover it and it is permanently degraded.
Perhaps @kris or @honeybadger can advise what will happen and what actions you should take based on more detailed knowledge.
ZFS itself appears to have gine the best advice: Replace the SMR drive with a CMR drive.
The interaction between resilver and expansion has been considered: Expansion is only performed on healthy pools, and is therefore paused whenever a resilver is necessary.
I think the SMR disk did it’s timeout thing during expansion because of these 3 SMART values;
None reached the threshold for the drive to consider it’s self bad. But, ZFS also has timing issues that are independent of SMART values.
My opinion is that;
The scrub has little to do with the problem. It likely started as normal, after the RAID-Zx expansion was paused. Though it is possible it was started due to the pause of the RAID-Zx expansion. (All completed RAID-Zx expansions are immediately followed by a pool scrub, which is mandatory.)
The RAID-Zx expansion was paused because of timeouts from the “new” SMR disk, which caused the drive to appear failed to ZFS.
The “new” SMR drive is now a permanent part of the pool.
Rebooting won’t help anything.
The “new” SMR drive should be replaced sooner rather than later.
Whence the replacement drive has been re-silvered, the RAID-Zx expansion can resumed. (Or will automatically resume…)
The above, as I stated, are my opinions.
Item 5 says sooner rather than later, because it is possible that some data is no longer covered by RAID-Z1 parity. So a bad block in another disk could result in data loss in a file. (But not the whole pool, unless another disk goes bad completely.)
Further, when replacing the “new” SMR disk, I’d suggest replace in place. Meaning install the new replacement disk in to the server and leaving the “new” SMR disk in place too. This gives a higher chance of a successful replacement. Of course, this requires a disk slot, power cables and a SATA port. Which if you don’t have such, then you have to perform the normal disk replacement and take your chances.
It MAY be possible to resume the RAID-Zx expansion on the “new” SMR disk. This can possibly be done by using the suggested clear command as below. But, the same problem may re-occur. zpool clear Mother
I am in two minds whether it would be better to resume the expansion on the SMR drive whilst waiting for the new CMR replacement thus increasing the number of blocks reliant on the SMR drive for redundancy in the hope that it will eventually finish and have a non-degraded, fully redundant, fully expanded pool which would be the base for a completely standard resilver, or to wait for the new drive and do a resilver followed by resuming the expansion (which is much less tested but which leaves the majority of the data redundant even during the resilver.
On the whole my gut reaction is that it would be better to wait.
P.S. I am not sure whether setting higher TLER values than the standard 70 decisecs (i.e. 7 seconds) would help avoid errors. I am, however, unclear whether these error values are a result of TLER or whether they indicate internal errors unrelated to TLER.
Just giving an update.
Over the last few days, I’ve been backing up my data and have ordered the new ironwolf drive (which I now have.)
I’ve decided to take Arwen’s advice and am now replacing in place. Currently re-silvering.
Things to note: After startup, the expansion job was no longer queued, but vpool status through shell reports the same expansion progress and degraded status.
Hey there, I’m back from several weeks in the future!
I’m pleased to report that the expansion was successful. Thank you everyone for your input. There are zero problems with the system after the whole dance.
As for why it finished earlier than expected, I believe the expansion picked up where it last left off after resilvering finished.
pool: Mother
state: ONLINE
scan: scrub repaired 0B in 11:49:23 with 0 errors on Wed Dec 25 22:12:51 2024
expand: expanded raidz1-0 copied 23.5T in 15 days 08:23:04, on Wed Dec 25 10:23:28 2024
config:
NAME STATE READ WRITE CKSUM
Mother ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ed4c0028-a16b-4f12-9412-784ea35c2707 ONLINE 0 0 0
9ad18062-9800-4b72-80d6-4601a309149a ONLINE 0 0 0
49d51ca4-bc4a-437a-9b6f-6f072160ab99 ONLINE 0 0 0
bd6710a6-008a-4fa0-8d00-cf75b6019fee ONLINE 0 0 0
9b1ff822-6b42-4d78-ba82-802d06e7b321 ONLINE 0 0 0
logs
mirror-1 ONLINE 0 0 0
dbead5fa-880c-4316-a7e6-6b60508de098 ONLINE 0 0 0
9fc44b1b-5bf1-455e-aec2-512656fa6133 ONLINE 0 0 0
errors: No known data errors
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:26 with 0 errors on Tue Dec 24 03:45:27 2024
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
nvme0n1p3 ONLINE 0 0 0
This is part of ZFS standard practices. Scrubs, Re-Silvers and ASync Destroys will continue after a reboot. On the other hand, ZFS sends are a user level function so they would be aborted by a reboot and have to be manually restarted.