Ive got backup(most of it but not all) but really dont want to do it this way. Probably its easy way to fix this but i dont know how. Ive got another server to move this pool and i know will work but after few days/weeks will that happen again freez server and kernel panic, even if I try manually scrub pool (which I have automated) will not show me errors its looks like something is wrong deeper inside pool setting or something.
Not really, at home U can check just by software(Victoria, Hdd Sentinel etc) which will tell U basic really basic which is nothing compare to proper sata controller like “ACE Lab” the cheapest cost over 1000$. This controller can access service zone where any software can not do it because is close by every HDD manufacturer. This service zone can tell everything about HDD its like black box.
HI ive found similar topic in other forum LINK and drive to this LINK which is about Block Cloning Bug in openZFS. I know this bug was in 2.2 ver. but i have this pool and system for few yrs on my server and maybe maybe this bug release after ive swap server and drives on to new one.
That issue was fixed, over a year ago.
OP:
you say your NAS became unresponsive, was it during a deletion of a bunch of data?
the error is (likely the ZIL being replayed) is trying to add a segment of free space twice to the space map which should never happen but can a large file deletion or destroy is in progress before an ungraceful reboot. this is one of the more common issues I’ve seen (and encountered).
first, try to see if you can import the read only, as I said above when this exact error usually happens it’s because the ZIL is trying to replay something that already happened during import which fails… readonly ignores the ZIL and I’m fairly certain it also doesn’t load spacemaps.
first, boot up your system with enough of the disks connected that it doesn’t automatically try to import the pool
when your system is up, reconnect the disks and try:
zpool import Data -o readonly=on to import the pool readonly
you may want to try zpool import Data -F -o readonly=on if the first try is unsuccessful…
however, if you can import the pool readonly you have some options:
- copy the data out and recreate the pool from scratch.
- try enabling
zil_replay_disablebefore importing to throw out the ZIL if the ZIL is your problem (you will lose some recent transactions, and you will likely leak some space) - more drastic then the last… enable the
zfs_recovertunable which will allow duplicate entries into the spacemap… this might be necessary if you have issues beyond the ZIL.
I’ve had success on a system that was hard shutdown due to “freezing” while deleting a rather large dataset, importing readonly worked, and separately importing with zfs_recover worked, and it was enough to let the zfs metaslab coalescing algorithms work and fix the issue naturally, the pool has been healthy since. here is the post that led me to try this, years ago
but it is important to understand what put your pool in this state, and what risk you are willing to take, data that you were already trying to delete is obviously less valuable so it may be acceptable to try these drastic measures… good luck.
i was just hoping it was this, which will sort my problems ;(
Hello everyone,
The issue has happened again today. ![]() I just ran:
I just ran:
# zpool import -o readonly=on Data
The pool is detected without errors:
# zpool status
pool: Data
state: ONLINE
scan: scrub repaired 0B in 01:29:28 with 0 errors on Sun Feb 2 03:29:30 2025
remove: Removal of vdev 2 copied 300M in 0h0m, completed on Wed May 22 22:10:04 2024
42.2K memory used for removed device mappings
config:
NAME STATE READ WRITE CKSUM
Data ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
5c995451-1d6b-4e49-9910-e35e1334d48c ONLINE 0 0 0
dd27a607-0e60-4217-9ae1-3e1b03e2b5b7 ONLINE 0 0 0
errors: No known data errors
At this point, I can confidently say that the problem is with the RAM. The issue coincides with the installation of HAOS as a virtual machine, along with the number of containers I have running. With only 16GB of RAM, I suspect it’s insufficient, as I was experiencing random reboots.
During one of those reboots, the kernel panic occurred again. It’s clear that I need to upgrade my hardware, which is already on its way.
Thanks for all the help so far!
Best regards.
Hi for me its weird if u think U have not enough ram and that cause problems. The system will be slow not do randomly reboots. Its maybe power supply then RAM cause random reboots or CPU. Im not expert but ive got few servers in homelab and the most causing problems are those who mess with them the most(which is my main one) backups are solid as rock(even on shity HDDs).
For my HA ive got Fujitsu futro S740(4 wats in idle) as separate device. From my experience ill never do HA on VM on any server cos if server will break U basically screwed.
Hi mate,
Thanks for sharing your experience. The truth is, I started having reboots right after installing the virtual machine because I wanted to reduce the number of devices. I migrated from a mini PC where everything was running fine.
I wonder what the real cause is. I ran a memtest, and it passed without issues
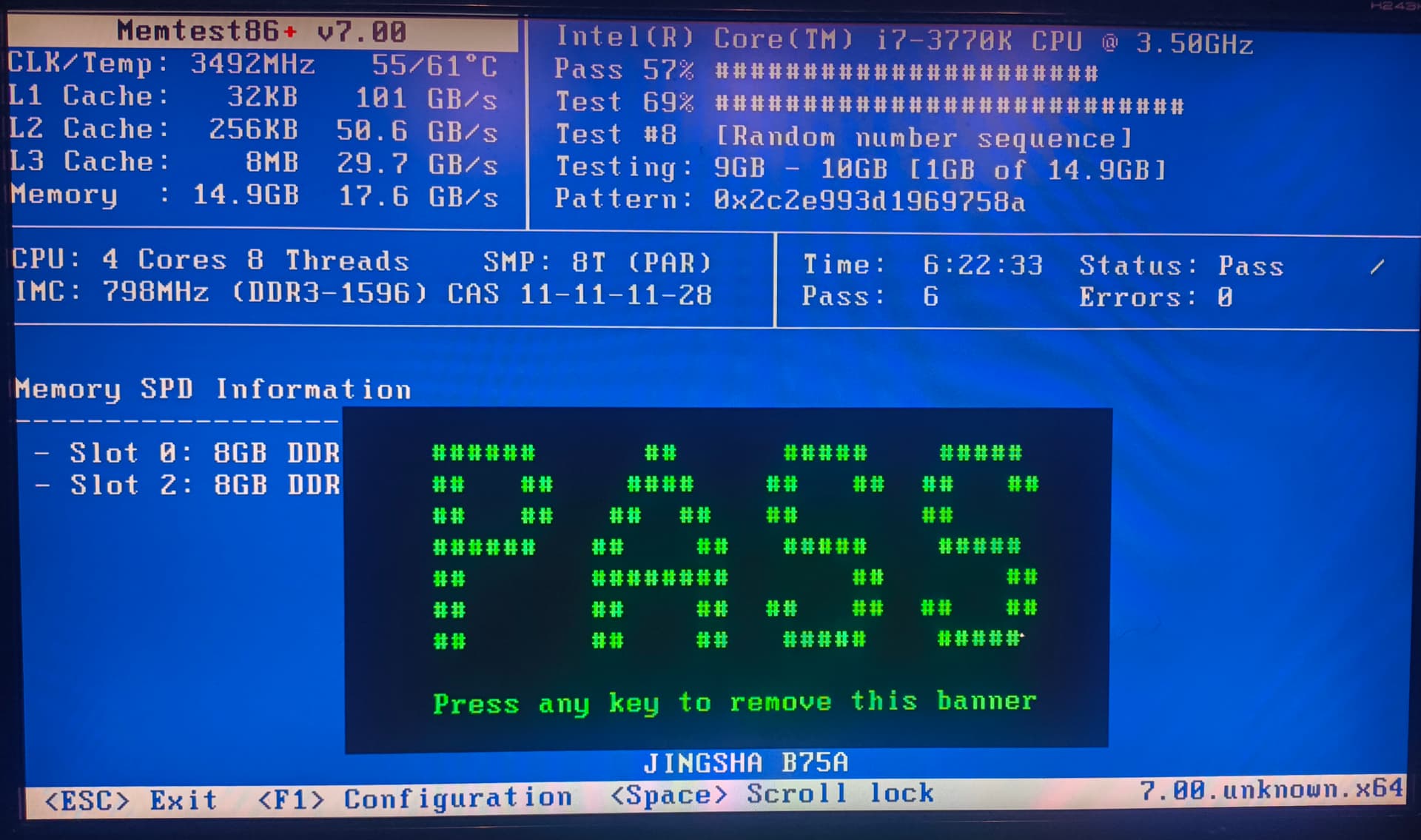
but I’m still getting kernel panic.
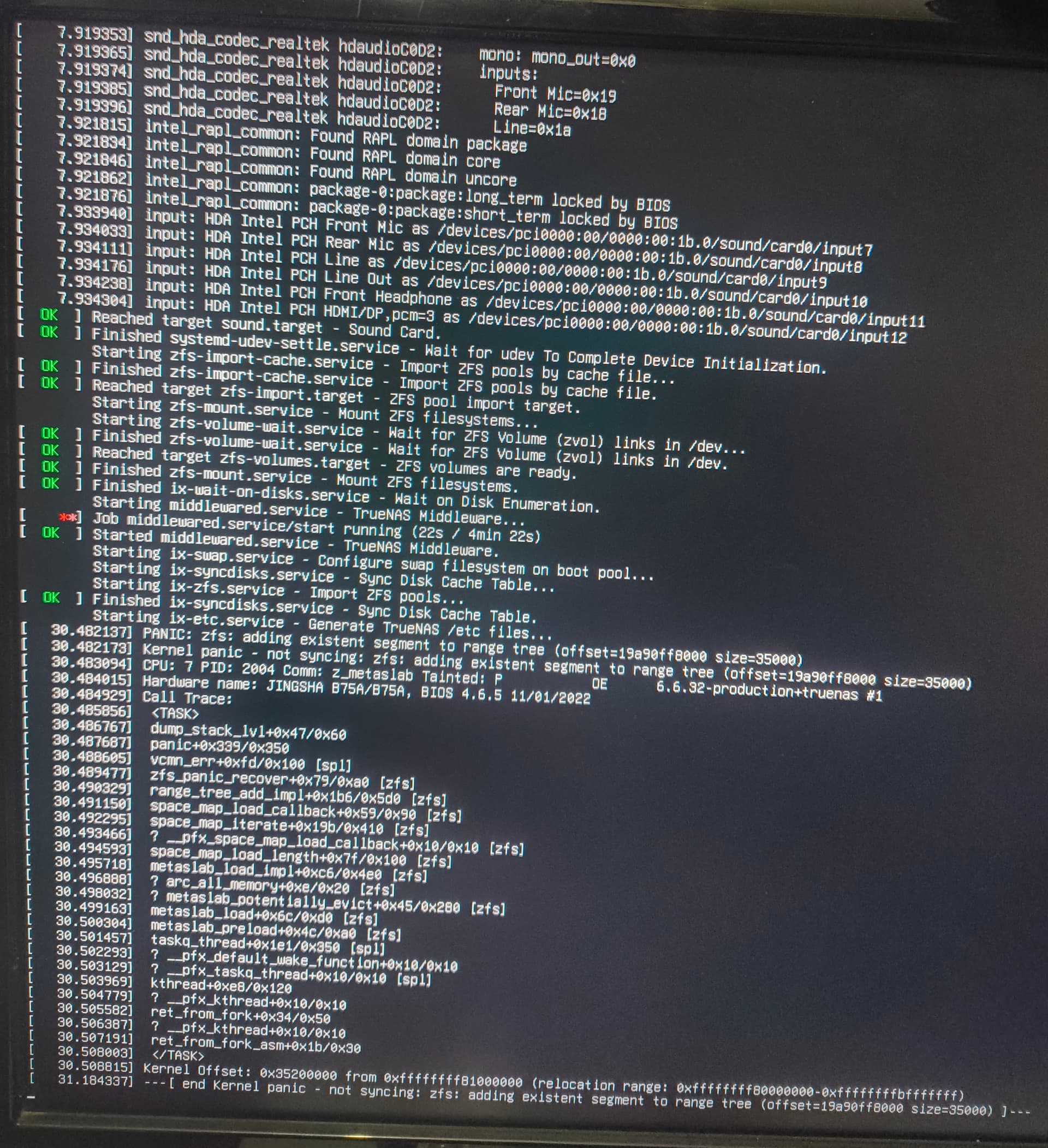
If I import the disks in read-only mode, I can see that I have access to all of them, but the system won’t boot. ![]()
Does anyone know the next steps to take? Do I really need to rebuild the pool and reload all the data? Just thinking about it is quite discouraging…
Any help is greatly appreciated. Thanks!
I quick internet search suggests that:
- This is caused by pool corruption; and
- No one has been able to fix it - they have all recreated their pool.
My advice is to bite the bullet and recreate your pool from backups.
And avoid adding a VM again until you have more memory.
1 Like
So, if I understand it correctly, when you remove a vDev (from a Mirror - you can’t do it with RAIDZ), ZFS moves the blocks from that vDev elsewhere and the indirect marker is a ZFS label that helps ZFS remember that there is a mapping of the blocks that were on this vDev to blocks elsewhere.
Have I got that right?
1 Like
Thanks for the recommendations. Recreating the pool was not necessary thanks to the suggested steps.
First, I tried importing the pool in read-only mode, then used -F to discard recent transactions. When that didn’t fully work, I enabled zfs_recover and managed to import the pool, but it wouldn’t mount due to a read-only filesystem issue.
After remounting the system root in read/write mode and manually mounting the datasets, everything went back to normal, including Kubernetes and the containers. Server is now 100% operational.
Thanks again, your advice was incredibly helpful!
2 Likes
it’s good that you were able to regain access to your data, but I want to know what led up to the you having to you needing to reboot your NAS?
more specifically, were you deleting any large files or dataset? they can cause a zfs filesystem to “freeze” (it isn’t frozen but it can take long amounts of time to progress and stalls out other I/O)
that specifically can cause the error “adding existent segment to range tree” when hard rebooted in this state. this is one of the few times that I would say the pool should be reasonably safe to use after importing with zfs_recover.
also, keep in mind that once you enabled that zfs_recover tunable to import your pool (with this error), you need to let it run for a day or two for the metaslabs to coalesce on-disk, which is required to let it import normally in the future.
I don’t deal with non-servers, so any time I’ve seen this error it has been on ECC systems. my experience with “adding existing segment to range tree” panics, every other time they seem to have been caused by a hard reboot during a large deletion (and why I’m curious to see if that was true for OP as well)
My system used to reboot very rarely, and I suspect it might be due to low RAM availability, since I run many services along with a virtual machine.
Right now, I only have 1GB of RAM available, and that’s without the VM running, so I definitely have less memory than I should.
That being said, it’s still too early to draw conclusions, so I’ll keep monitoring the system to see if the issue happens again.
1 Like
in recent versions of TrueNAS Scale swap was disabled starting in 24.04, due to a number of issues with it causing performance degradation. I strongly believe that the lack of swap caused your lack of memory to turn into reboot issues.
if you are on 24.04, you should be able to run sudo swapon -d=once /dev/mapper/md127 to re-enable the swap. I believe this is the version you are on as you mention Kubernetes and this is the last version to have Kubernetes. (edit, you definitely are, so follow this and don’t upgrade until you have more RAM)
if you are on 24.10, you can no longer manually enable swap as they have removed the md subsystem altogether, and the partitions used as md slices cannot individually be used as swap partitions without redoing them somehow… (it would be nice if ix could either implement a way to easily enable swap if the user feels it necessary or even just add back md?)
I would highly recommend enabling swap if you can until you have more RAM, with your system in this state it could mean the difference between slightly slow vs unstable with hard restarts.