I hope you are all doing well. I’m experiencing an issue with my NAS and would greatly appreciate your help.
My NAS has two pools: one called “Data,” made up of two SSDs in a mirror configuration, and another called “Media,” made up of two HDDs in a stripe configuration. The “Data” pool hosts Kubernetes applications and two virtual machines.
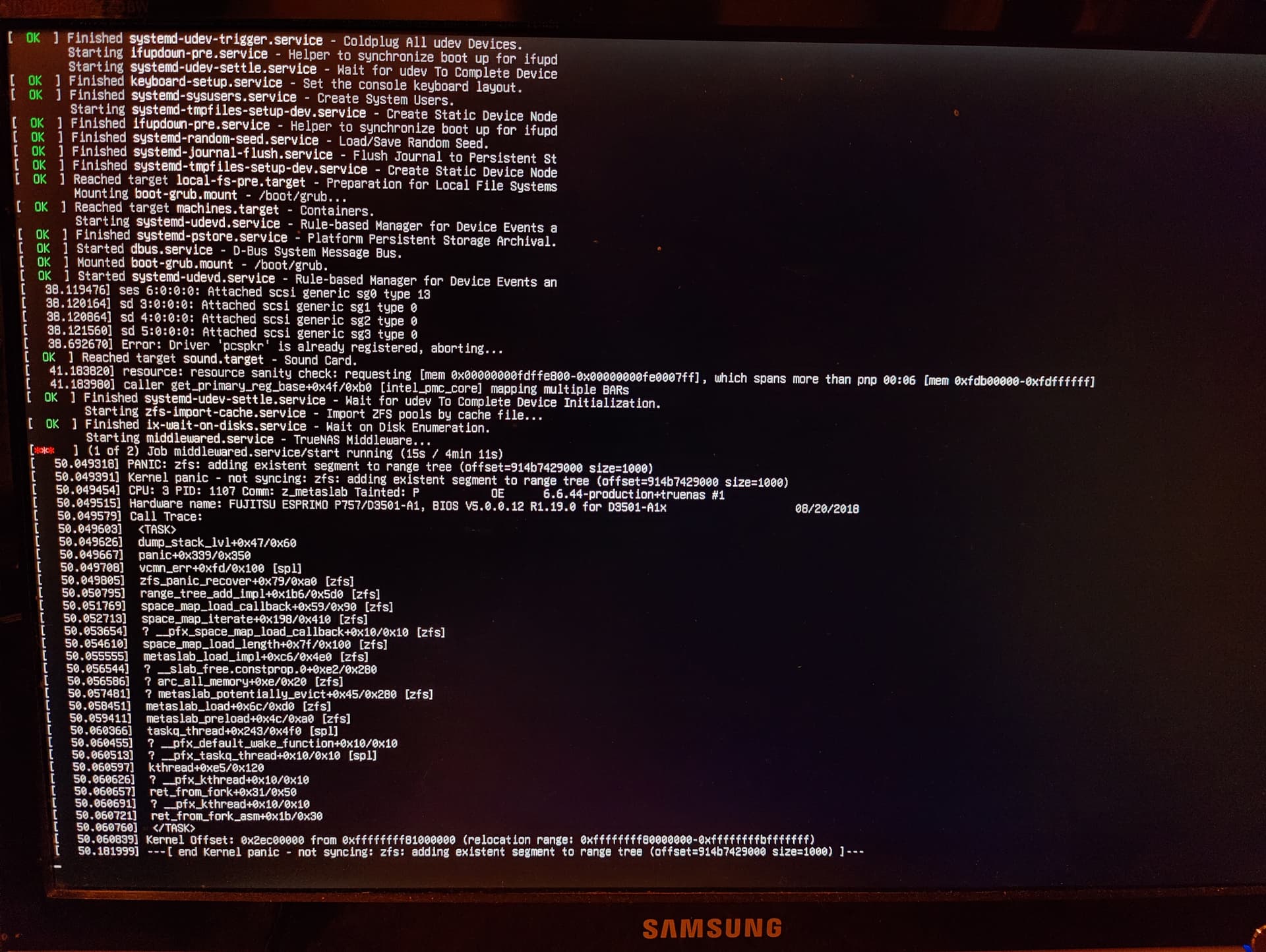
Today, while I was using my computer, the NAS suddenly froze. After rebooting, it enters a Kernel Panic state. If I physically disconnect the disks from the “Data” pool, the NAS boots normally. However, if I reconnect either of the two “Data” disks, the issue reappears.
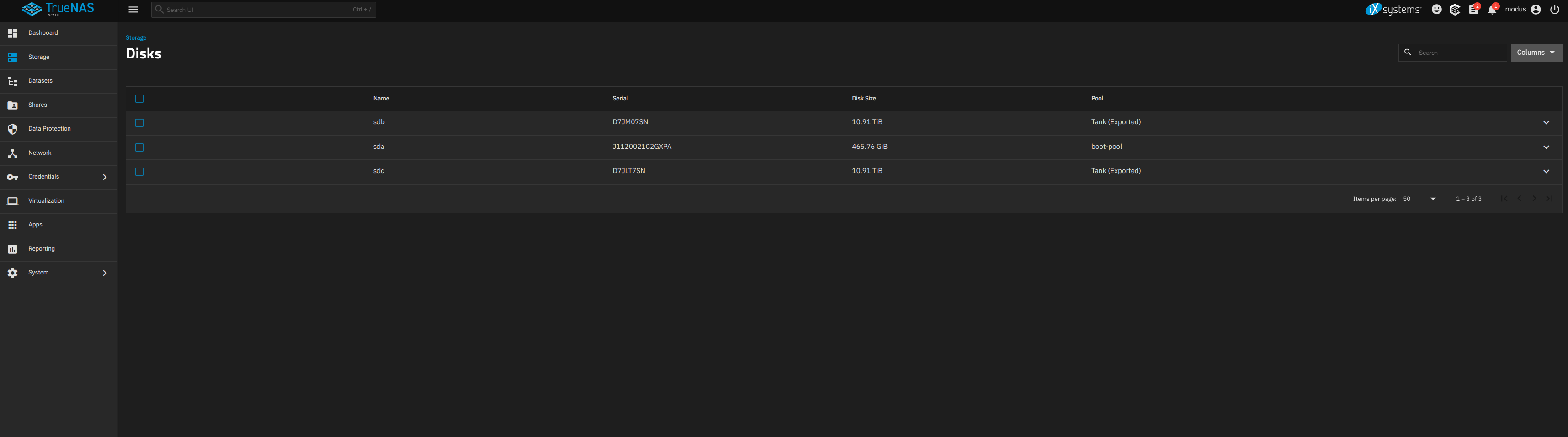
I also tried connecting them while the system was running, but the disks are recognized as “uninitialized,” and in the disks section, the system identifies them as part of a pool called “Data (external).”
I’m attaching a screenshot of the error message that appears during the kernel panic for additional context.
(Attach the screenshot)
I will not be able to help with any prospective recovery but I can ask you for some more information.
What version of TrueNAS do you have installed?
Tell us about your hardware and how your drives are connected. Please be thorough.
If this is a virtualised setup, tell us about that.
After answering those questions, you would benefit from running memtest overnight. If RAM faults were the cause of your freeze and other issues you will want to know of and address that before attempting any recovery.
Thank you again for your assistance. I’d like to share some additional information and ask for guidance regarding a potential solution I found online.
TrueNAS Version: I am currently running TrueNAS-SCALE 24.04.2.2.
Hardware:
Motherboard: ITX B75A.
CPU: Intel i7-3770K.
RAM: 16 GB Non-ECC.
Drives and Connections:
All drives are connected directly to the SATA ports on the motherboard.
The system runs natively (no virtualization).
The “Data” pool consists of two SSDs in a mirror configuration, both with only six months of use.
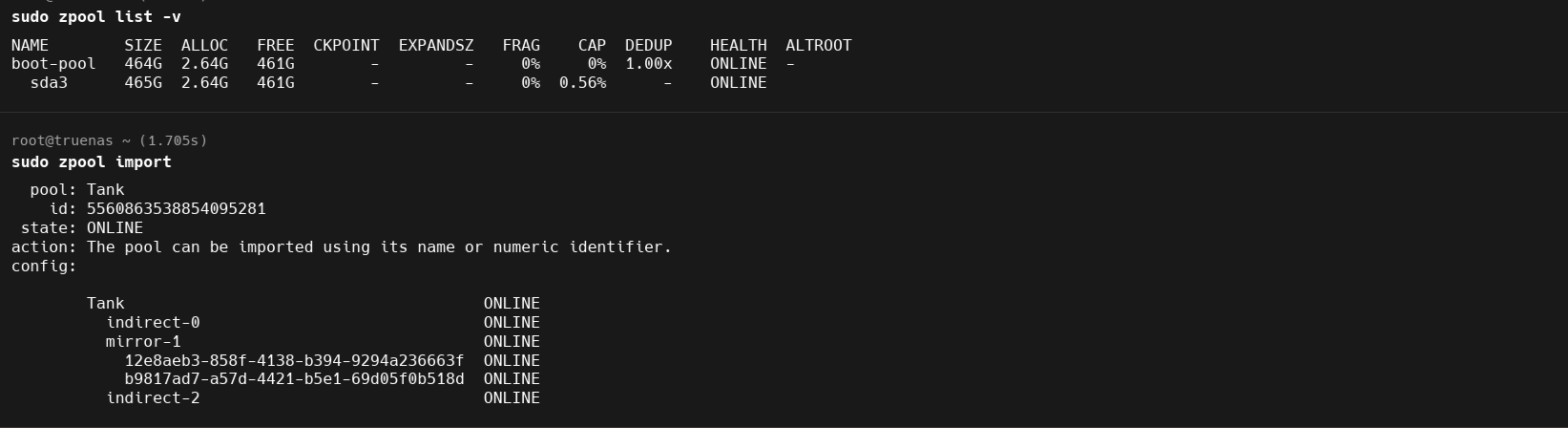
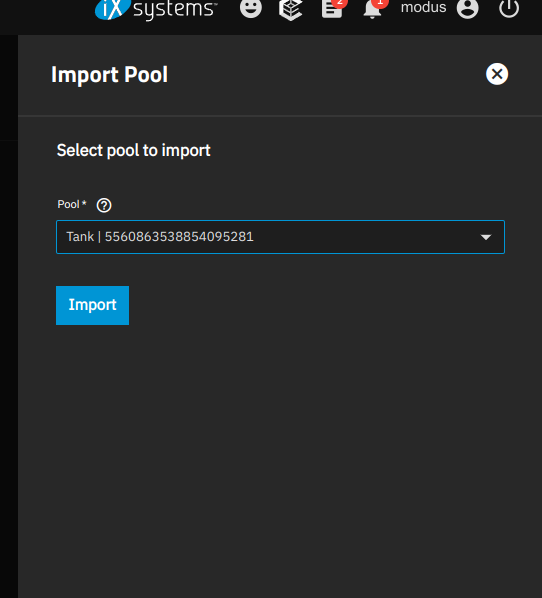
I’ve attached images showing the system and hardware information, the composition of the DATA pool, and the current state of the pool (appears as Data (Exported)). Please note that the image only shows one of the two SSDs from the “Data” pool. However, if I connect the other SSD, it also appears in the same state.
I found information online about importing a ZFS pool in read-only mode to potentially recover data from a damaged pool. The process involves these commands:
This method supposedly mounts the pool in read-only mode, allowing access to the data without modifying the pool. Once read-only access is established, exporting and re-importing the pool would return it to read-write mode:
first server fujitsu esprimo P758
i7-7800
64 GB RAM non ecc
Mellanox Connect x3 10gb
2xWD RED PLUS 12TB
Samsung 840 120gb boot
After a month it simply hung and after restarting I had kerlen panic with similar symptoms as above in the picture. I changed literally all components and it did not work. I moved the disk (boot) with two WD (data) to another computer and everything worked without any problems, the system started normally and the entire pool was visible without any errors, i.e. I determined that the motherboard was damaged. I had a second similar server based on Fujitsu Esprimo P757. I3-6100T
64 GB RAM non ecc
Mellanox Connect x3 10gb
I transferred the boot and two WD to this server and after a week and a half the same thing happened, the server froze and after restarting kernel panic. When I disconnect these two WD drives the system starts normally, which means that the drives may be damaged. These two WD drives are completely new.
Previously I had two 8TB Seagate drives refurbished and when I bought new WD I did resilvering and could I transfer any errors during this? but it would be strange because the system did not show me anything during use.
Okay, do you have a backup of the data on your pool? Do you have a backed up copy of your TrueNAS configuration?
Considering you have had problems with two different Fujitsu servers. Are you reusing any components between the two servers besides the boot and data drives? Have you been using new SATA cables or the same ones? I am trying to figure out if there was anything similar or if any reused components could be an issue.
I would try doing a full hardware test on the server. Self diagnostics and Memtest86 to test the RAM
Have you ran SMART Long tests on the hard drives? Are you seeing any errors doing your scheduled pool scrub?
It also help to know what the server is used for. If it is just a lightly loaded NAS or if it has a bunch of applications and VMs running. What version of TrueNAS are you running?
TrueNAS-SCALE-24.10.2 System
Mostly it is as NAS with several applications (Plex, Tailscale, Cloudflare, Adguard, Immich, Photoprism) without VM. And also this time I changed all components sata cables, sata controller (pcie), ram etc. I installed a new system on another disk and it did not change the problem.
The system starts normally on the new system (new disk) + import of old settings or old system on the old disk only when I connect two large WD disks there is a kernel panic.
Yes I have a backup of everything the entire system (settings) + data pool
Yes all disks just checked SMART. Tomorrow I’m going to a company dealing with disks because you really need a proper controller (hardware) to check if the disk is really damaged or not SMART will not really say anything.
The wierd thing is if i moved boot and data pool to another server everything is working its absolutely the same situation like before.
And to update Yes ive check all components and test them on other servers and are running with no problems i mean RAM, Sata cables, Processor.
What are you expectations here? They are unlikely have a machine that will physically check the disk. Anything they can do you can do as well, unless they plan on opening the drive up in a clean room to manually pull data from the platters, in which case the drive would be a paper weight after they were done with it. Are they just going to run HD Sentinel on it so they can hand you the verdict on a piece of paper at the end?
To fully test the drive using software, you would write to the whole drive and then verify that you can successfully read back what you wrote. badblocks is one way to do this. Mind you, if you want to do this properly it’s destructive to any data currently on the drive.
There are of non-destructive methods to just check if the sectors can be read, but that’s less thorough. A zfs scrub will test the readability of all parts of the drive currently containing data.
Have you actually run memtest on the server with issues? How many passes and how long did it take?
Inexplicably the problem solved itself . After a few reboots and removing and replacing the disks while testing it, it was solved.
After trying the commands I mentioned and seeing that all the data was intact, backing up again, after a reboot it worked normally again.
I plan to change the hardware soon, I hope I don’t run into the same problem
I forgot to add after install fresh system on new disk i able to see pool(mirrored) but can not import. Ive tried from gui to import and whats happend i can see its immporting but the system is restarting and after restart nothing is imported.
You need to provide screenshots or post the details on commands you are trying. CLI data, post back here using Preformatted Text (</>) (Ctrl+e) on toolbar when replying.
My observation is that we see these issues on non-ECC systems, but rarely on ECC systems.
Its easy to understand why… corrupted metadata can potentially be stored in the pool. ZFS will checksum the corrupted data nicely, but then be unable to use it.
It’s a rare event, but with hundreds of thousands of users, it can happen. Let us know if you do find any hardware issues so we can keep the problem in mind.
Hi again in few hrs smart will finish to check last disk(first one pass). What should i do to import pool basically i want all my old settings to be uploaded but i know if i do this ill have kernel panic after restart which happen before. Im able to see the pool thru gui or cli. When I just import pool thru gui system will show importing popup but after few minutes will restart it self and will not import the pool which this happen before.
Before [SmallBarky] asked me about tests yes I did memtest on 64gb ram which took almost 6hrs and pass and the same with CPU all pass(on CPU i did stress test few hrs). With disks WD red plus which are brand new I test them on some hardware controller (ACElab) and pass flawlessly also long SMART. Now TN(last ver.) is on new boot disk which is clean and i have connected old pool which im able to see what next should I do. many thx for help;)
Im able to boot system only if I disconnect disks if i connect and boot ive have kernel panic.
This situation on server Fujitsu P757 is exactly the same like before on Fujitsu P758. And now if i want take those disks and install them in to other server every thing will work:
on new boot system and old pool and upload old settings or
old boot system with old pool
I dont know whats going on, this is second time and I cant resolve this. The only thing which could cause this problem is resilvering from old pool cos ive change HDDs from refurbish 8TB to brand new 12TB. On old pool (those 8TB) i had many zfs errors and what i did just clear errors manually. Those errors was not possible to fix cos HDD was damage but the thing is this NEW pool was working absolutely fine on old server then I moved all disks(old pool and boot) to new server(Fujitsu P758) and after month and half server just freeze and after reboot kernel panic and now the same situation on server Funitsu P757 after few weeks freez and kernel panic.
Ps also im able only do 3 posts per day cos this forum.
I am not sure either. Your image from the zpool import is strange to me with an ‘indirect -0’ and ‘indirect-2’ listings. I was hoping more experienced would post.