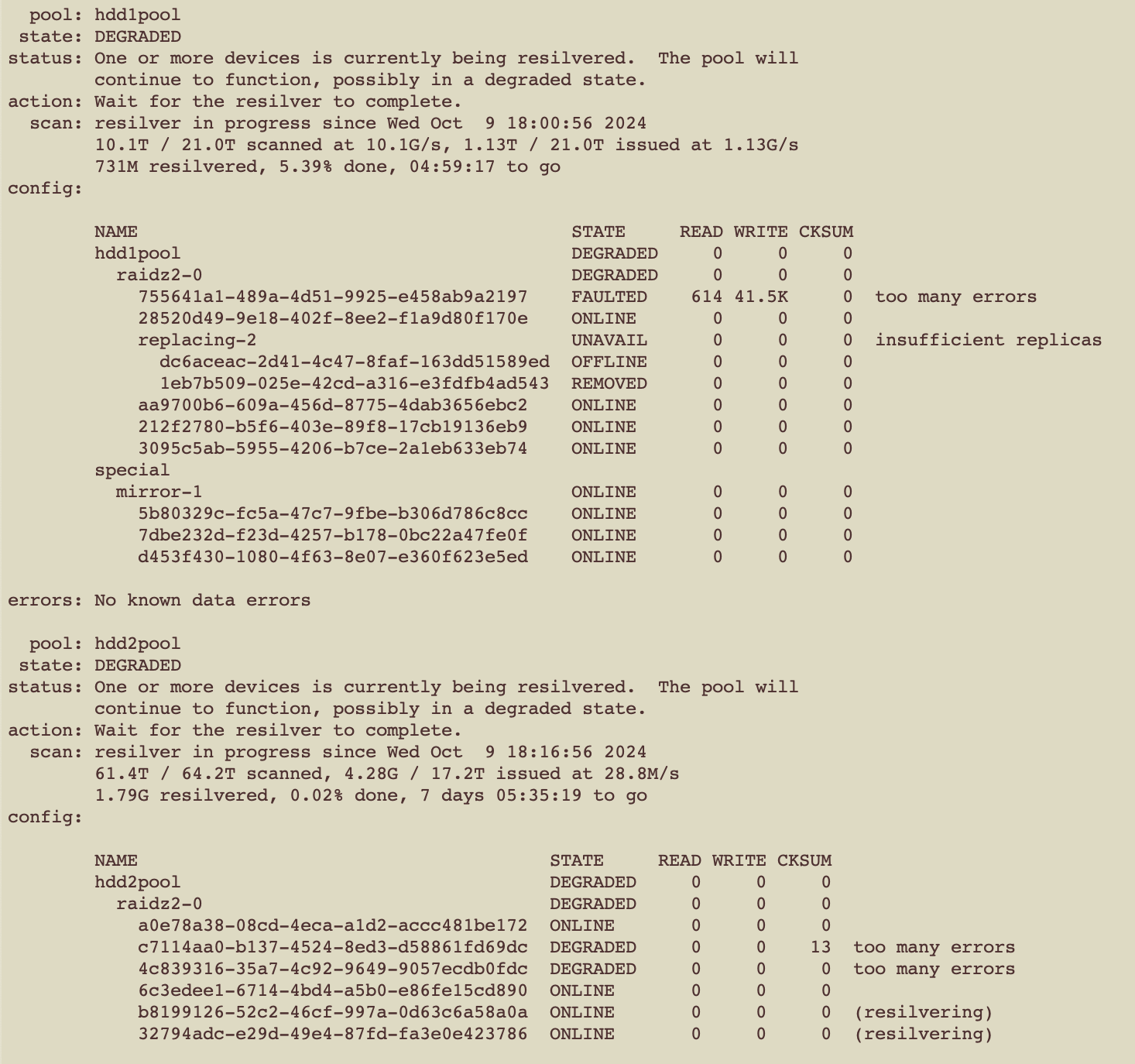
There is definitely a card related faulty port in that swapping cables doesn’t make the drive slot work, but swapping card ports the faulty slot moves to another slot. This does make me think again it’s controller related - or something between the controller and the OS. Does anyone know of a known good LSI card I should buy or have one they want to sell that is known good? I live in New Zealand and as such I have to rely on eBay which takes quite a while to deliver.
My thought is a known good card would rule out the card.
In the mean time anyone know which logs I should submit? Here’s a snippet from /var/log/messages
Thanks.
Oct 13 10:03:17 Skywalker kernel: mpt3sas_cm0: handle(0x1f) sas_address(0x300062b20a744802) port_type(0x1)
Oct 13 10:03:18 Skywalker kernel: scsi 15:0:60:0: Direct-Access ATA ST18000NT001-3LU EN01 PQ: 0 ANSI: 6
Oct 13 10:03:18 Skywalker kernel: scsi 15:0:60:0: SATA: handle(0x001f), sas_addr(0x300062b20a744802), phy(2), device_name(0x0000000000000000)
Oct 13 10:03:18 Skywalker kernel: scsi 15:0:60:0: enclosure logical id (0x500062b20a744800), slot(8)
Oct 13 10:03:18 Skywalker kernel: scsi 15:0:60:0: enclosure level(0x0000), connector name( )
Oct 13 10:03:18 Skywalker kernel: scsi 15:0:60:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y)
Oct 13 10:03:18 Skywalker kernel: scsi 15:0:60:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1)
Oct 13 10:03:18 Skywalker kernel: sd 15:0:60:0: Attached scsi generic sg17 type 0
Oct 13 10:03:18 Skywalker kernel: sd 15:0:60:0: Power-on or device reset occurred
Oct 13 10:03:18 Skywalker kernel: end_device-15:60: add: handle(0x001f), sas_addr(0x300062b20a744802)
Oct 13 10:03:18 Skywalker kernel: sd 15:0:60:0: [sdt] 35156656128 512-byte logical blocks: (18.0 TB/16.4 TiB)
Oct 13 10:03:18 Skywalker kernel: sd 15:0:60:0: [sdt] 4096-byte physical blocks
Oct 13 10:03:18 Skywalker kernel: sd 15:0:60:0: [sdt] Write Protect is off
Oct 13 10:03:18 Skywalker kernel: sd 15:0:60:0: [sdt] Write cache: enabled, read cache: enabled, supports DPO and FUA
Oct 13 10:03:18 Skywalker kernel: sdt: sdt1
Oct 13 10:03:18 Skywalker kernel: sd 15:0:60:0: [sdt] Attached SCSI disk
Oct 13 10:03:21 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:03:21 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:03:21 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:03:22 Skywalker kernel: sd 15:0:53:0: device_block, handle(0x001d)
Oct 13 10:03:25 Skywalker kernel: sd 15:0:53:0: device_unblock and setting to running, handle(0x001d)
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=1 offset=2156594257920 size=1048576 flags=1074267304
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=1 offset=2156593209344 size=1048576 flags=1074267304
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=1 offset=2156596355072 size=1048576 flags=1074267304
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=1 offset=2156595306496 size=1048576 flags=1074267304
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=1 offset=2156597403648 size=1048576 flags=1074267304
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:25 Skywalker kernel: sd 15:0:53:0: [sdr] Synchronizing SCSI cache
Oct 13 10:03:25 Skywalker kernel: sd 15:0:53:0: [sdr] Synchronize Cache(10) failed: Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK
Oct 13 10:03:25 Skywalker kernel: mpt3sas_cm0: mpt3sas_transport_port_remove: removed: sas_addr(0x300062b20a744800)
Oct 13 10:03:25 Skywalker kernel: mpt3sas_cm0: removing handle(0x001d), sas_addr(0x300062b20a744800)
Oct 13 10:03:25 Skywalker kernel: mpt3sas_cm0: enclosure logical id(0x500062b20a744800), slot(11)
Oct 13 10:03:25 Skywalker kernel: mpt3sas_cm0: enclosure level(0x0000), connector name( )
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:25 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:28 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:28 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:31 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:33 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/0840a677-c089-4baa-af1c-3aa14652219b error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:34 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:03:34 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:03:34 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:03:34 Skywalker kernel: sd 15:0:60:0: device_block, handle(0x001f)
Oct 13 10:03:37 Skywalker kernel: sd 15:0:60:0: device_unblock and setting to running, handle(0x001f)
Oct 13 10:03:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2159787999232 size=65536 flags=1074267304
Oct 13 10:03:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2159788064768 size=32768 flags=1573032
Oct 13 10:03:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2159788097536 size=1048576 flags=1074267304
Oct 13 10:03:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2159787933696 size=65536 flags=1074267304
Oct 13 10:03:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2159789146112 size=1048576 flags=1074267304
Oct 13 10:03:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:03:37 Skywalker kernel: sd 15:0:60:0: [sdt] Synchronizing SCSI cache
Oct 13 10:03:37 Skywalker kernel: sd 15:0:60:0: [sdt] Synchronize Cache(10) failed: Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK
Oct 13 10:03:37 Skywalker kernel: mpt3sas_cm0: mpt3sas_transport_port_remove: removed: sas_addr(0x300062b20a744802)
Oct 13 10:03:37 Skywalker kernel: mpt3sas_cm0: removing handle(0x001f), sas_addr(0x300062b20a744802)
Oct 13 10:03:37 Skywalker kernel: mpt3sas_cm0: enclosure logical id(0x500062b20a744800), slot(8)
Oct 13 10:03:37 Skywalker kernel: mpt3sas_cm0: enclosure level(0x0000), connector name( )
Oct 13 10:03:43 Skywalker netdata[1976565]: CONFIG: cannot load cloud config '/var/lib/netdata/cloud.d/cloud.conf'. Running with internal defaults.
Oct 13 10:03:45 Skywalker kernel: mpt3sas_cm0: handle(0x1d) sas_address(0x300062b20a744800) port_type(0x1)
Oct 13 10:03:46 Skywalker kernel: scsi 15:0:61:0: Direct-Access ATA ST18000NT001-3LU EN01 PQ: 0 ANSI: 6
Oct 13 10:03:46 Skywalker kernel: scsi 15:0:61:0: SATA: handle(0x001d), sas_addr(0x300062b20a744800), phy(0), device_name(0x0000000000000000)
Oct 13 10:03:46 Skywalker kernel: scsi 15:0:61:0: enclosure logical id (0x500062b20a744800), slot(11)
Oct 13 10:03:46 Skywalker kernel: scsi 15:0:61:0: enclosure level(0x0000), connector name( )
Oct 13 10:03:46 Skywalker kernel: scsi 15:0:61:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y)
Oct 13 10:03:46 Skywalker kernel: scsi 15:0:61:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1)
Oct 13 10:03:46 Skywalker kernel: sd 15:0:61:0: Attached scsi generic sg15 type 0
Oct 13 10:03:46 Skywalker kernel: sd 15:0:61:0: Power-on or device reset occurred
Oct 13 10:03:46 Skywalker kernel: end_device-15:61: add: handle(0x001d), sas_addr(0x300062b20a744800)
Oct 13 10:03:46 Skywalker kernel: sd 15:0:61:0: [sdr] 35156656128 512-byte logical blocks: (18.0 TB/16.4 TiB)
Oct 13 10:03:46 Skywalker kernel: sd 15:0:61:0: [sdr] 4096-byte physical blocks
Oct 13 10:03:46 Skywalker kernel: sd 15:0:61:0: [sdr] Write Protect is off
Oct 13 10:03:46 Skywalker kernel: sd 15:0:61:0: [sdr] Write cache: enabled, read cache: enabled, supports DPO and FUA
Oct 13 10:03:46 Skywalker kernel: sdr: sdr1
Oct 13 10:03:46 Skywalker kernel: sd 15:0:61:0: [sdr] Attached SCSI disk
Oct 13 10:03:57 Skywalker kernel: mpt3sas_cm0: handle(0x1f) sas_address(0x300062b20a744802) port_type(0x1)
Oct 13 10:03:58 Skywalker kernel: scsi 15:0:62:0: Direct-Access ATA ST18000NT001-3LU EN01 PQ: 0 ANSI: 6
Oct 13 10:03:58 Skywalker kernel: scsi 15:0:62:0: SATA: handle(0x001f), sas_addr(0x300062b20a744802), phy(2), device_name(0x0000000000000000)
Oct 13 10:03:58 Skywalker kernel: scsi 15:0:62:0: enclosure logical id (0x500062b20a744800), slot(8)
Oct 13 10:03:58 Skywalker kernel: scsi 15:0:62:0: enclosure level(0x0000), connector name( )
Oct 13 10:03:58 Skywalker kernel: scsi 15:0:62:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y)
Oct 13 10:03:58 Skywalker kernel: scsi 15:0:62:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1)
Oct 13 10:03:58 Skywalker kernel: sd 15:0:62:0: Attached scsi generic sg17 type 0
Oct 13 10:03:58 Skywalker kernel: sd 15:0:62:0: Power-on or device reset occurred
Oct 13 10:03:58 Skywalker kernel: end_device-15:62: add: handle(0x001f), sas_addr(0x300062b20a744802)
Oct 13 10:03:58 Skywalker kernel: sd 15:0:62:0: [sdt] 35156656128 512-byte logical blocks: (18.0 TB/16.4 TiB)
Oct 13 10:03:58 Skywalker kernel: sd 15:0:62:0: [sdt] 4096-byte physical blocks
Oct 13 10:03:58 Skywalker kernel: sd 15:0:62:0: [sdt] Write Protect is off
Oct 13 10:03:58 Skywalker kernel: sd 15:0:62:0: [sdt] Write cache: enabled, read cache: enabled, supports DPO and FUA
Oct 13 10:03:58 Skywalker kernel: sdt: sdt1
Oct 13 10:03:58 Skywalker kernel: sd 15:0:62:0: [sdt] Attached SCSI disk
Oct 13 10:04:08 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:04:08 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:04:08 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:04:09 Skywalker kernel: sd 15:0:62:0: device_block, handle(0x001f)
Oct 13 10:04:12 Skywalker kernel: sd 15:0:62:0: device_unblock and setting to running, handle(0x001f)
Oct 13 10:04:12 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2174122418176 size=32768 flags=1573032
Oct 13 10:04:12 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2174122385408 size=32768 flags=1573032
Oct 13 10:04:12 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2174122450944 size=1048576 flags=1074267304
Oct 13 10:04:12 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2174122352640 size=32768 flags=1573032
Oct 13 10:04:12 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2174123499520 size=1048576 flags=1074267304
Oct 13 10:04:12 Skywalker kernel: sd 15:0:62:0: [sdt] Synchronizing SCSI cache
Oct 13 10:04:12 Skywalker kernel: sd 15:0:62:0: [sdt] Synchronize Cache(10) failed: Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK
Oct 13 10:04:12 Skywalker kernel: mpt3sas_cm0: mpt3sas_transport_port_remove: removed: sas_addr(0x300062b20a744802)
Oct 13 10:04:12 Skywalker kernel: mpt3sas_cm0: removing handle(0x001f), sas_addr(0x300062b20a744802)
Oct 13 10:04:12 Skywalker kernel: mpt3sas_cm0: enclosure logical id(0x500062b20a744800), slot(8)
Oct 13 10:04:12 Skywalker kernel: mpt3sas_cm0: enclosure level(0x0000), connector name( )
Oct 13 10:04:12 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:12 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:15 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:15 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:21 Skywalker netdata[1979229]: CONFIG: cannot load cloud config '/var/lib/netdata/cloud.d/cloud.conf'. Running with internal defaults.
Oct 13 10:04:32 Skywalker kernel: mpt3sas_cm0: handle(0x1f) sas_address(0x300062b20a744802) port_type(0x1)
Oct 13 10:04:33 Skywalker kernel: scsi 15:0:63:0: Direct-Access ATA ST18000NT001-3LU EN01 PQ: 0 ANSI: 6
Oct 13 10:04:33 Skywalker kernel: scsi 15:0:63:0: SATA: handle(0x001f), sas_addr(0x300062b20a744802), phy(2), device_name(0x0000000000000000)
Oct 13 10:04:33 Skywalker kernel: scsi 15:0:63:0: enclosure logical id (0x500062b20a744800), slot(8)
Oct 13 10:04:33 Skywalker kernel: scsi 15:0:63:0: enclosure level(0x0000), connector name( )
Oct 13 10:04:33 Skywalker kernel: scsi 15:0:63:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y)
Oct 13 10:04:33 Skywalker kernel: scsi 15:0:63:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1)
Oct 13 10:04:33 Skywalker kernel: sd 15:0:63:0: Attached scsi generic sg17 type 0
Oct 13 10:04:33 Skywalker kernel: end_device-15:63: add: handle(0x001f), sas_addr(0x300062b20a744802)
Oct 13 10:04:33 Skywalker kernel: sd 15:0:63:0: Power-on or device reset occurred
Oct 13 10:04:33 Skywalker kernel: sd 15:0:63:0: [sdt] 35156656128 512-byte logical blocks: (18.0 TB/16.4 TiB)
Oct 13 10:04:33 Skywalker kernel: sd 15:0:63:0: [sdt] 4096-byte physical blocks
Oct 13 10:04:33 Skywalker kernel: sd 15:0:63:0: [sdt] Write Protect is off
Oct 13 10:04:33 Skywalker kernel: sd 15:0:63:0: [sdt] Write cache: enabled, read cache: enabled, supports DPO and FUA
Oct 13 10:04:33 Skywalker kernel: sdt: sdt1
Oct 13 10:04:33 Skywalker kernel: sd 15:0:63:0: [sdt] Attached SCSI disk
Oct 13 10:04:33 Skywalker kernel: mpt3sas_cm0: log_info(0x31110d00): originator(PL), code(0x11), sub_code(0x0d00)
Oct 13 10:04:34 Skywalker kernel: sd 15:0:63:0: device_block, handle(0x001f)
Oct 13 10:04:37 Skywalker kernel: sd 15:0:63:0: device_unblock and setting to running, handle(0x001f)
Oct 13 10:04:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2183223898112 size=1048576 flags=1074267304
Oct 13 10:04:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=1 offset=2183224946688 size=1048576 flags=1074267304
Oct 13 10:04:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:37 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:37 Skywalker kernel: sd 15:0:63:0: [sdt] Synchronizing SCSI cache
Oct 13 10:04:37 Skywalker kernel: sd 15:0:63:0: [sdt] Synchronize Cache(10) failed: Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK
Oct 13 10:04:37 Skywalker kernel: mpt3sas_cm0: mpt3sas_transport_port_remove: removed: sas_addr(0x300062b20a744802)
Oct 13 10:04:37 Skywalker kernel: mpt3sas_cm0: removing handle(0x001f), sas_addr(0x300062b20a744802)
Oct 13 10:04:37 Skywalker kernel: mpt3sas_cm0: enclosure logical id(0x500062b20a744800), slot(8)
Oct 13 10:04:37 Skywalker kernel: mpt3sas_cm0: enclosure level(0x0000), connector name( )
Oct 13 10:04:39 Skywalker netdata[1980864]: CONFIG: cannot load cloud config '/var/lib/netdata/cloud.d/cloud.conf'. Running with internal defaults.
Oct 13 10:04:40 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:40 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:40 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:40 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:43 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:43 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:46 Skywalker kernel: zio pool=hdd1pool vdev=/dev/disk/by-partuuid/074df82f-bf92-4bd7-8bea-f8981dd3c9c4 error=5 type=5 offset=0 size=0 flags=1049728
Oct 13 10:04:57 Skywalker kernel: mpt3sas_cm0: handle(0x1f) sas_address(0x300062b20a744802) port_type(0x1)
Oct 13 10:04:57 Skywalker kernel: scsi 15:0:64:0: Direct-Access ATA ST18000NT001-3LU EN01 PQ: 0 ANSI: 6
Oct 13 10:04:57 Skywalker kernel: scsi 15:0:64:0: SATA: handle(0x001f), sas_addr(0x300062b20a744802), phy(2), device_name(0x0000000000000000)
Oct 13 10:04:57 Skywalker kernel: scsi 15:0:64:0: enclosure logical id (0x500062b20a744800), slot(8)
Oct 13 10:04:57 Skywalker kernel: scsi 15:0:64:0: enclosure level(0x0000), connector name( )
Oct 13 10:04:57 Skywalker kernel: scsi 15:0:64:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y)
Oct 13 10:04:57 Skywalker kernel: scsi 15:0:64:0: qdepth(32), tagged(1), scsi_level(7), cmd_que(1)
Oct 13 10:04:57 Skywalker kernel: sd 15:0:64:0: Attached scsi generic sg17 type 0
Oct 13 10:04:57 Skywalker kernel: sd 15:0:64:0: Power-on or device reset occurred
Oct 13 10:04:57 Skywalker kernel: end_device-15:64: add: handle(0x001f), sas_addr(0x300062b20a744802)
Oct 13 10:04:57 Skywalker kernel: sd 15:0:64:0: [sdt] 35156656128 512-byte logical blocks: (18.0 TB/16.4 TiB)
Oct 13 10:04:57 Skywalker kernel: sd 15:0:64:0: [sdt] 4096-byte physical blocks
Oct 13 10:04:57 Skywalker kernel: sd 15:0:64:0: [sdt] Write Protect is off
Oct 13 10:04:57 Skywalker kernel: sd 15:0:64:0: [sdt] Write cache: enabled, read cache: enabled, supports DPO and FUA
Oct 13 10:04:57 Skywalker kernel: sdt: sdt1
Oct 13 10:04:57 Skywalker kernel: sd 15:0:64:0: [sdt] Attached SCSI disk
Oct 13 10:04:57 Skywalker netdata[1982379]: CONFIG: cannot load cloud config '/var/lib/netdata/cloud.d/cloud.conf'. Running with internal defaults.
As you can see, things are not happy.
log.txt (19.0 KB)
dmesg.txt (386.3 KB)